
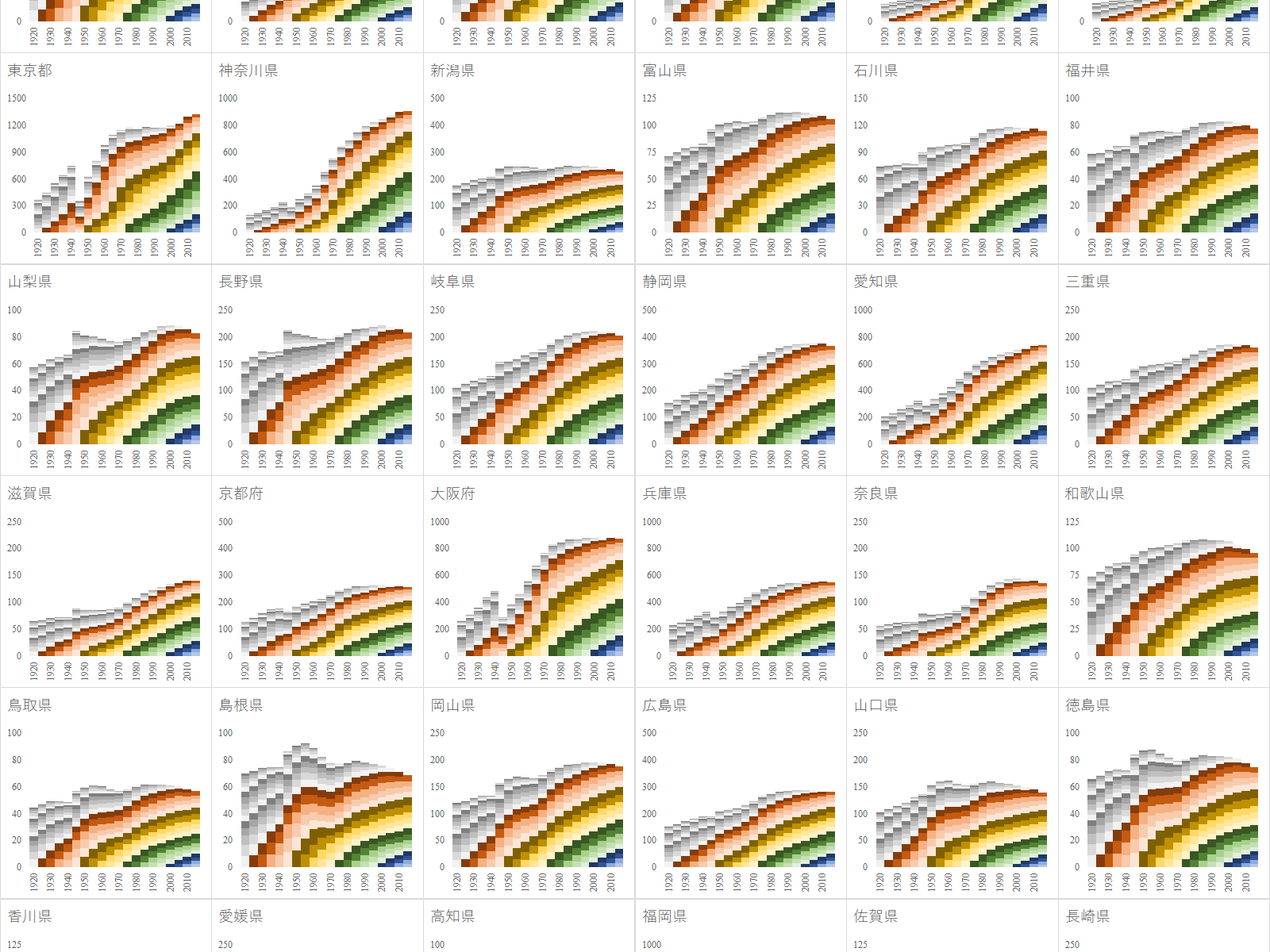
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
Power Query でデータクレンジング
ダウンロードしたファイル (“FEI_CITY_************.csv”) を直接開かず,別の EXCEL ファイルから Power Query で開く.
「元号」と「和暦(年)」は不要なので削除する.重要なのは西暦年である.
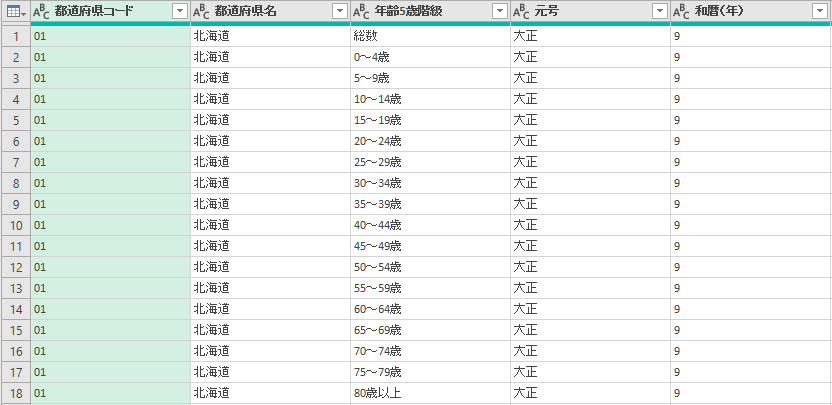
年齢5歳階級の列を観察する
まずフィルターをポップアップしてどんなデータがあるか確認する.

スクロールバーをスクロールして最下段まで見に行く.
「数え歳」の扱い
5歳階級であるから範囲の数値となる.一部,1歳ずつずれている範囲がある.これは 1945 年の国勢調査にだけ見られるもので,日本人独特の「数え歳」を反映している.終戦後の混乱の中で国勢調査を実施する困難は想像に余りある.
それはともかく,これはデータ系列を作成するには邪魔になるため,目をつぶって1歳ずらすことにする.
上図を見ると分かるが,「空白」と「総数」は不要な行なのでチェックを外しておく.「80歳以上」「80~84歳」「85歳以上」が混乱するが,「80歳以上」の分類は国勢調査の始まったごく初期だけのものであるため,このままにしておく.
「列の分割」は「数字から数字以外による分割」
問題は「年齢5歳階級」をどう分割するかである.適切な分割方法が既に用意されていた.「数字から数字以外による分割」できれいに先頭の数字だけを抽出できる.

この段階でテーブルに読み込む.
生年は年度から年齢階級を引き算して求める
観察する年によって値が変わるという意味で,年齢は相対値である.しかし,生年は絶対値である.世の中に数多くあるグラフは年齢で区分されていたため,経時的な推移を見るには不適切だった.むしろ生年で区分けした方が分かりやすい.
こういう作業も EXCEL は得意である.
まず,Mod 関数で年齢を 5 で除算した剰余を求める.次に,IF 関数で結果が 1 なら年齢から 1 を引き,そうでないなら年齢をそのまま扱う.最後に年度から IF 関数の結果を引き算して生年を求める.
1 月から 3 月生まれの分がずれるが,これは毎年のことであり,誕生月が不明のためやむを得ないと割り切る.今後の調査で誕生月まで分かれば,さらに正確なデータからグラフを作成できるだろう.
作業列をコピーして値を貼り付けし,参照関係を解消する.生年の列だけを残して作業列を削除する.結果を .txt ファイルに保存する.
SQL Server でデータ系列を整形
概要
ウィザードを使って先程保存した .txt ファイルをインポートする.
EXCEL のデータ系列の仕様に合わせてデータの枠組みを作成する.年度は 1920 年から 2015 年までの 20 件.一方,生年は 1840 年から 2015 年までの 36 件.さらに都道府県が 47 ある.これらの直積 33840 件を求める.
クエリ
一時テーブルで生年,年度,都道府県を作成する.都道府県コードと都道府県名は先程インポートしてできたテーブルから読み込んでいる(70-71 行目).
DROP TABLE IF EXISTS #BIRTHYEAR; CREATE TABLE #BIRTHYEAR(BirthYear int NOT NULL); INSERT INTO #BIRTHYEAR VALUES (1840) ,(1845) ,(1850) ,(1855) ,(1860) ,(1865) ,(1870) ,(1875) ,(1880) ,(1885) ,(1890) ,(1895) ,(1900) ,(1905) ,(1910) ,(1915) ,(1920) ,(1925) ,(1930) ,(1935) ,(1940) ,(1945) ,(1950) ,(1955) ,(1960) ,(1965) ,(1970) ,(1975) ,(1980) ,(1985) ,(1990) ,(1995) ,(2000) ,(2005) ,(2010) ,(2015); DROP TABLE IF EXISTS #FISCALYEAR; CREATE TABLE #FISCALYEAR(FiscalYear int NOT NULL); INSERT INTO #FISCALYEAR VALUES (1920) ,(1925) ,(1930) ,(1935) ,(1940) ,(1945) ,(1950) ,(1955) ,(1960) ,(1965) ,(1970) ,(1975) ,(1980) ,(1985) ,(1990) ,(1995) ,(2000) ,(2005) ,(2010) ,(2015); DROP TABLE IF EXISTS #PrefCode CREATE TABLE #PrefCode(PrefCode nchar(2) NOT NULL, Prefecture nvarchar(50) NOT NULL); INSERT INTO #PrefCode SELECT DISTINCT PrefCode, Prefecture FROM dbo.T_PrefPopulation1920_2015; WITH CTE AS ( SELECT PrefCode, Prefecture, BirthYear, FiscalYear FROM #PrefCode CROSS JOIN #BIRTHYEAR CROSS JOIN #FISCALYEAR ) SELECT CTE.PrefCode , CTE.BirthYear , CTE.FiscalYear , CTE.Prefecture , CASE WHEN P.TotalPopulation IS NULL THEN 0 ELSE P.TotalPopulation END AS Total , CASE WHEN P.MenPopulation IS NULL THEN 0 ELSE P.MenPopulation END AS Men , CASE WHEN P.WomenPopulation IS NULL THEN 0 ELSE P.WomenPopulation END AS Women FROM CTE LEFT JOIN dbo.T_PrefPopulation1920_2015 AS P ON CTE.BirthYear = P.BirthYear AND CTE.FiscalYear = P.FiscalYear AND CTE.PrefCode = P.PrefCode ORDER BY CTE.PrefCode, CTE.BirthYear, CTE.FiscalYear;
結果をヘッダー付きでコピーし,EXCEL に貼り付ける.マクロつきブックで保存する.
EXCEL VBA でグラフ作成
概要
人口は絶対値であるためグラフ形式は「積み上げ棒」が妥当である.ここでは男女別ではなく総数のため縦棒である(26 行目).男女別にするなら横棒となる.
まずテーブルに都道府県コードでフィルターをかけ,結果を Range オブジェクトで取得する(33-35 行目).
ついで生年でフィルターをかけ,結果を Range オブジェクトで取得する(39-41 行目).
取得した Range オブジェクトから年度と総人口を取得し,配列に入力する(47-48 行目).
Series オブジェクトを生成し,データ系列名と横軸,縦軸の値を入力する(52-56 行目).
以上 61 行目までがグラフの骨格であり,62 行目以降はいわば「お化粧」である.
63-67 行目でタイトルを有効化し,.Caption プロパティで都道府県名を入力し,位置を調整する.
70-74 行目で横軸の書式を設定している.軸目盛の方向を左に 90 度傾けている.
75-100 行目で縦軸の書式を設定している.表示単位を万とし,ラベルを削除する.境界値の最大値に応じて最大値を変更して揃え,主目盛線を 5 等分する.
101-104 行目でグラフエリアの書式を設定し,グラフ全体のフォントを変更している.
105-107 行目でデータ系列の間隔を 0 とし,間を詰めている.
108-189 行目でデータ系列の色を設定する.5歳階級を連続で5回分,合計 25 年で 1 系統となるように選んでいる.結果として 1925 年生まれ,1950 年生まれ,1975 年生まれ,2000 年生まれの色が最も濃くなった.これらは日本の人口統計を議論する上で重要な年齢階級である.
コード
Option Explicit
Sub PrefPopulation()
Dim mySht1 As Worksheet
Dim mySht2 As Worksheet
Dim LstObj As ListObject
Dim myCht As Chart
Set mySht1 = Worksheets("Sheet1")
Set mySht2 = Worksheets.Add
Set LstObj = mySht1.ListObjects(1)
Dim i As Long
Dim j As Long
Dim myRng1 As Range
Dim myRng2 As Range
Dim k As Long
Dim FiscalYear() As Long
Dim Population() As Long
Dim mySeries As Series
Dim myAxis As Axis
For i = 1 To 47
Set myCht = mySht2.Shapes.AddChart2(Style:=-1, _
XlChartType:=xlColumnStacked, _
Left:=200 * ((i - 1) Mod 6), _
Top:=200 * ((i - 1) \ 6), _
Width:=200, _
Height:=200).Chart
With LstObj
.Range.AutoFilter field:=1, Criteria1:=i
Set myRng1 = Intersect(.DataBodyRange, _
.Range.SpecialCells(Type:=xlCellTypeVisible))
If myRng1 Is Nothing Then
Else
For j = 2015 To 1845 Step -5
.Range.AutoFilter field:=2, Criteria1:=j
Set myRng2 = Intersect(.DataBodyRange, _
.Range.SpecialCells(Type:=xlCellTypeVisible))
If myRng2 Is Nothing Then
Else
For k = 0 To myRng2.Rows.Count - 1
ReDim Preserve FiscalYear(k)
ReDim Preserve Population(k)
FiscalYear(k) = myRng2.Cells(k + 1, 3)
Population(k) = myRng2.Cells(k + 1, 5)
Next k
End If
.Range.AutoFilter field:=2
Set mySeries = myCht.SeriesCollection.NewSeries
With mySeries
.Name = j
.XValues = FiscalYear
.Values = Population
End With
Next j
End If
.Range.AutoFilter field:=1
End With
With myCht
.HasTitle = True
With .ChartTitle
.Caption = myRng2.Cells(1, 4)
.Left = 0
.Top = 0
End With
Set myAxis = .Axes(xlCategory)
With myAxis
.Format.Line.Visible = msoFalse
.MajorGridlines.Format.Line.Visible = msoFalse
.TickLabels.Orientation = xlUpward
End With
Set myAxis = .Axes(xlValue)
With myAxis
.DisplayUnit = xlTenThousands
.DisplayUnitLabel.Delete
Select Case .MaximumScale
Case 0 To 1000000
.MaximumScale = 1000000
Case 1000001 To 1250000
.MaximumScale = 1250000
Case 1250001 To 1500000
.MaximumScale = 1500000
Case 1500001 To 2500000
.MaximumScale = 2500000
Case 2500001 To 5000000
.MaximumScale = 5000000
Case 5000001 To 10000000
.MaximumScale = 10000000
Case 10000001 To 12500000
.MaximumScale = 12500000
Case 12500001 To 15000000
.MaximumScale = 15000000
Case Else
End Select
.MajorUnit = .MaximumScale / 5
.MajorGridlines.Format.Line.Visible = msoFalse
End With
With .ChartArea
.Format.Fill.ForeColor.ObjectThemeColor = msoThemeColorBackground1
.Format.TextFrame2.TextRange.Font.Name = "TimesNewRoman"
End With
With .ChartGroups(1)
.GapWidth = 0
End With
For Each mySeries In .SeriesCollection
With mySeries
Select Case .Name
Case "2020"
.Format.Fill.ForeColor.RGB = RGB(218, 227, 243)
Case "2015"
.Format.Fill.ForeColor.RGB = RGB(180, 199, 231)
Case "2010"
.Format.Fill.ForeColor.RGB = RGB(143, 170, 220)
Case "2005"
.Format.Fill.ForeColor.RGB = RGB(47, 85, 151)
Case "2000"
.Format.Fill.ForeColor.RGB = RGB(32, 56, 100)
Case "1995"
.Format.Fill.ForeColor.RGB = RGB(226, 240, 217)
Case "1990"
.Format.Fill.ForeColor.RGB = RGB(197, 224, 180)
Case "1985"
.Format.Fill.ForeColor.RGB = RGB(169, 209, 142)
Case "1980"
.Format.Fill.ForeColor.RGB = RGB(84, 130, 53)
Case "1975"
.Format.Fill.ForeColor.RGB = RGB(56, 87, 35)
Case "1970"
.Format.Fill.ForeColor.RGB = RGB(255, 242, 204)
Case "1965"
.Format.Fill.ForeColor.RGB = RGB(255, 230, 153)
Case "1960"
.Format.Fill.ForeColor.RGB = RGB(255, 217, 102)
Case "1955"
.Format.Fill.ForeColor.RGB = RGB(191, 144, 0)
Case "1950"
.Format.Fill.ForeColor.RGB = RGB(127, 96, 0)
Case "1945"
.Format.Fill.ForeColor.RGB = RGB(251, 229, 214)
Case "1940"
.Format.Fill.ForeColor.RGB = RGB(248, 203, 173)
Case "1935"
.Format.Fill.ForeColor.RGB = RGB(244, 177, 131)
Case "1930"
.Format.Fill.ForeColor.RGB = RGB(197, 90, 17)
Case "1925"
.Format.Fill.ForeColor.RGB = RGB(132, 60, 12)
Case "1920"
.Format.Fill.ForeColor.RGB = RGB(242, 242, 242)
Case "1915"
.Format.Fill.ForeColor.RGB = RGB(217, 217, 217)
Case "1910"
.Format.Fill.ForeColor.RGB = RGB(191, 191, 191)
Case "1905"
.Format.Fill.ForeColor.RGB = RGB(166, 166, 166)
Case "1900"
.Format.Fill.ForeColor.RGB = RGB(127, 127, 127)
Case "1895"
.Format.Fill.ForeColor.RGB = RGB(242, 242, 242)
Case "1890"
.Format.Fill.ForeColor.RGB = RGB(217, 217, 217)
Case "1885"
.Format.Fill.ForeColor.RGB = RGB(191, 191, 191)
Case "1880"
.Format.Fill.ForeColor.RGB = RGB(166, 166, 166)
Case "1875"
.Format.Fill.ForeColor.RGB = RGB(127, 127, 127)
Case "1870"
.Format.Fill.ForeColor.RGB = RGB(242, 242, 242)
Case "1865"
.Format.Fill.ForeColor.RGB = RGB(217, 217, 217)
Case "1860"
.Format.Fill.ForeColor.RGB = RGB(191, 191, 191)
Case "1855"
.Format.Fill.ForeColor.RGB = RGB(166, 166, 166)
Case "1850"
.Format.Fill.ForeColor.RGB = RGB(127, 127, 127)
Case "1845"
.Format.Fill.ForeColor.RGB = RGB(242, 242, 242)
Case "1840"
.Format.Fill.ForeColor.RGB = RGB(217, 217, 217)
Case "1835"
.Format.Fill.ForeColor.RGB = RGB(191, 191, 191)
End Select
End With
Next mySeries
End With
Next i
End Sub
結果
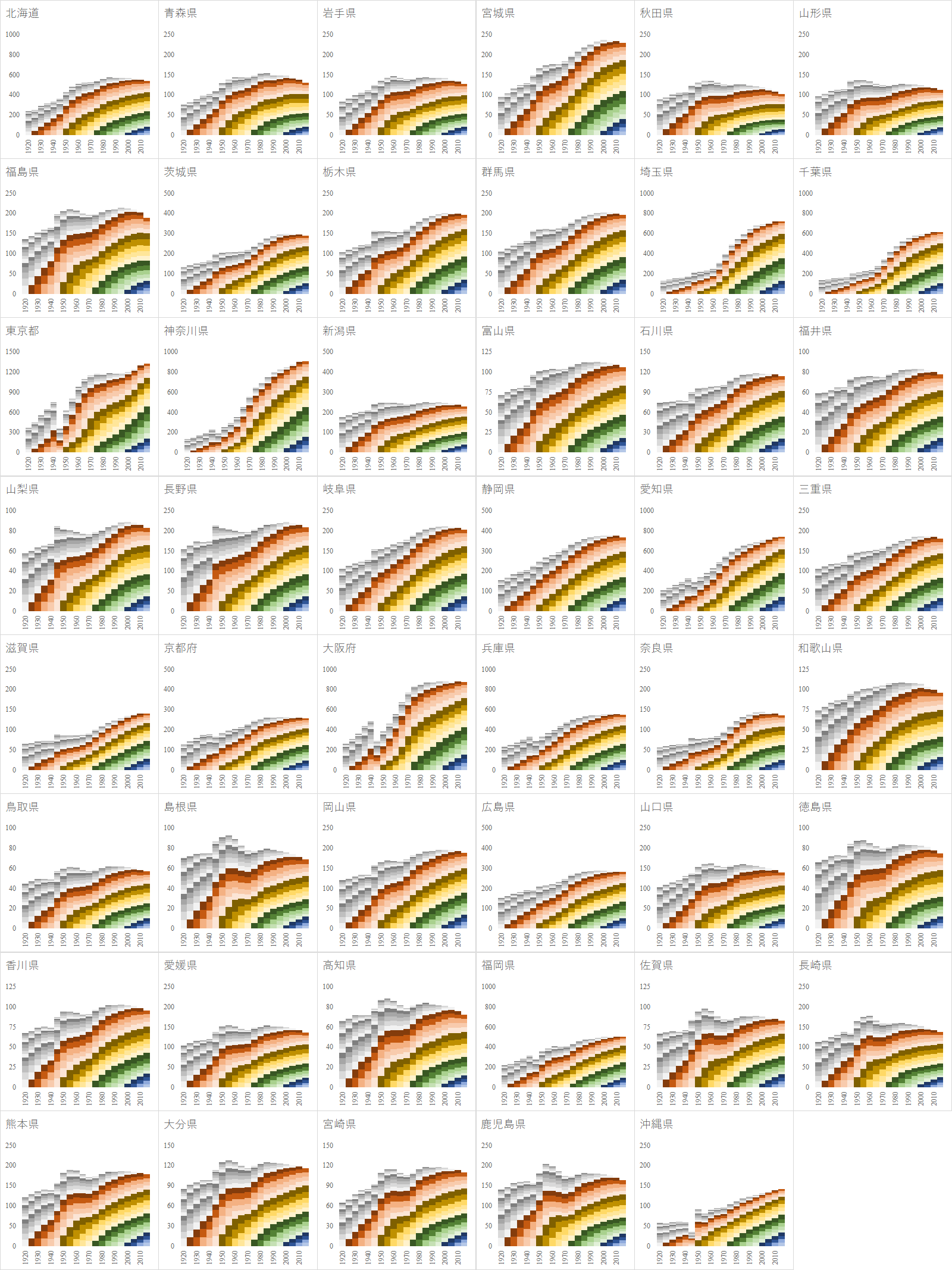
都道府県によって人口動態が異なるが,全体を俯瞰してみると,やはり第2次世界大戦により東京と大阪,沖縄の人口が激減しているのがまず目に止まる.
1925 年生まれは終戦時 20 歳から 25 歳にあたり,戦場に駆り出されたと考えられる.他にも疎開で地方に移動した人口もある.1945 年人口が突出している県はおそらく疎開の影響である.
1950 年代生まれは第1次ベビーブーム世代にあたる.この世代は団塊世代と呼ばれ,高齢化して社会の重荷となりつつある.
1975 年生まれは団塊ジュニア世代と呼ばれ,20 年後には社会の重荷と言われるようになる.理由は様々であるが,就職氷河期世代とも呼ばれ,十分な資本蓄積が進まなかった影響が大きい.
2000 年生まれは第3次ベビーブーム世代とはならなかった.団塊ジュニア世代が結婚せず,子供を作らなかったためである.
まとめ
総務省の「1920年から2015年までの都道府県別の5歳階級別人口推移」のファイルから,都道府県別の5歳階級別人口推移のグラフを作成した.
国勢調査から作成された人口動態グラフは数多く存在するが,生年で年齢階級を分類したグラフは見たことがない.
分類法を変更するだけで複雑なデータが分かりやすくなる.これもデータビジュアライゼーションの一例である.