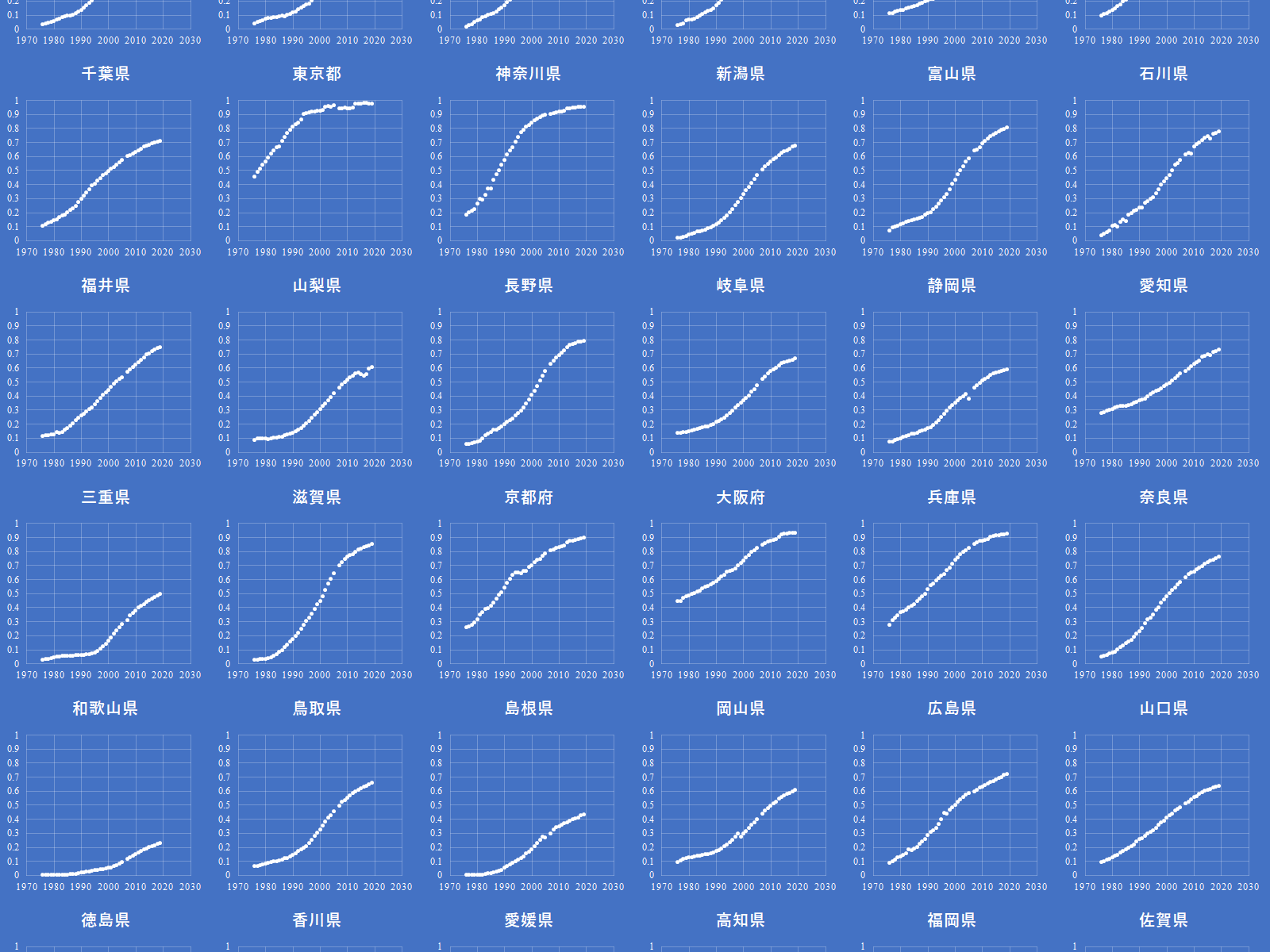
eStatから日本の資源収支を概略するで概略を取り上げた話題の一つに,トイレ水洗化人口が挙げられる.今回は各都道府県ごとの下水道によるトイレ水洗化人口の人口に占める割合の推移をグラフ化する.
都道府県ごとの下水道によるトイレ水洗化人口の人口に占める割合の推移をグラフ化する

Co-evolution of human and technology
eStatから日本の資源収支を概略するで概略を取り上げた話題の一つに,トイレ水洗化人口が挙げられる.今回は各都道府県ごとの下水道によるトイレ水洗化人口の人口に占める割合の推移をグラフ化する.
件の統計は復興庁の全国の避難者の数(所在都道府県別・所在施設別の数にあるが,このページはトップページから辿ることができず,検索からのみ到達できる.時系列でのデータは必須と思われるが,トップページから辿れるのは最新の情報のみであり,これは国民の利益に反する.
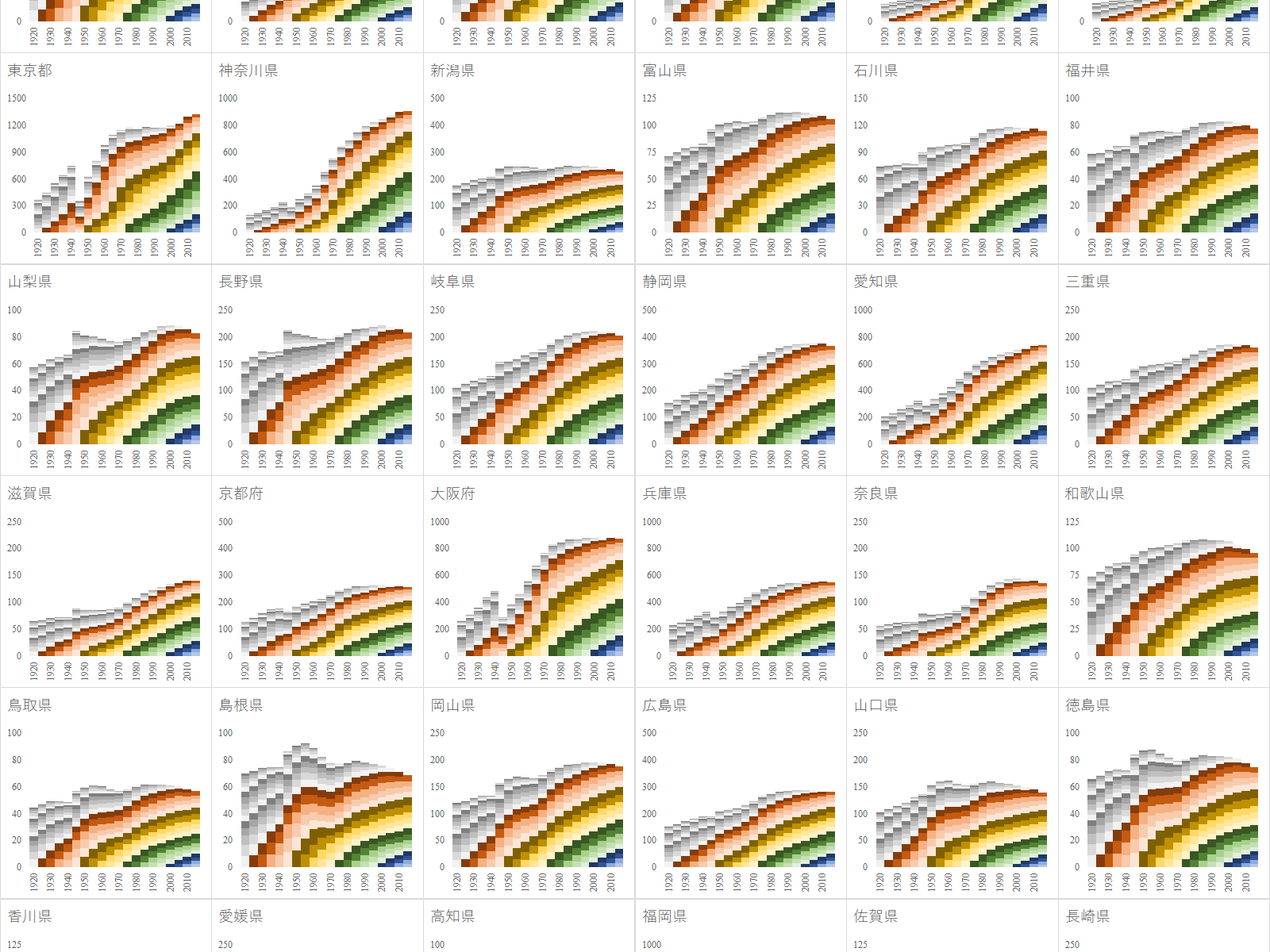
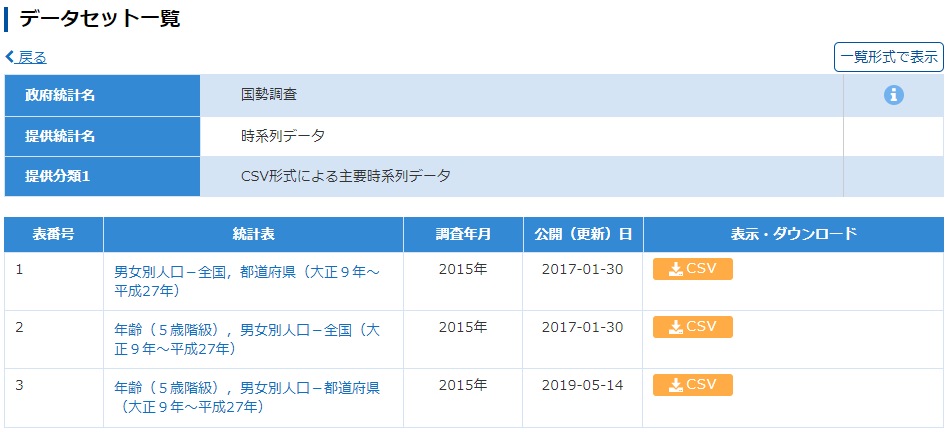
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
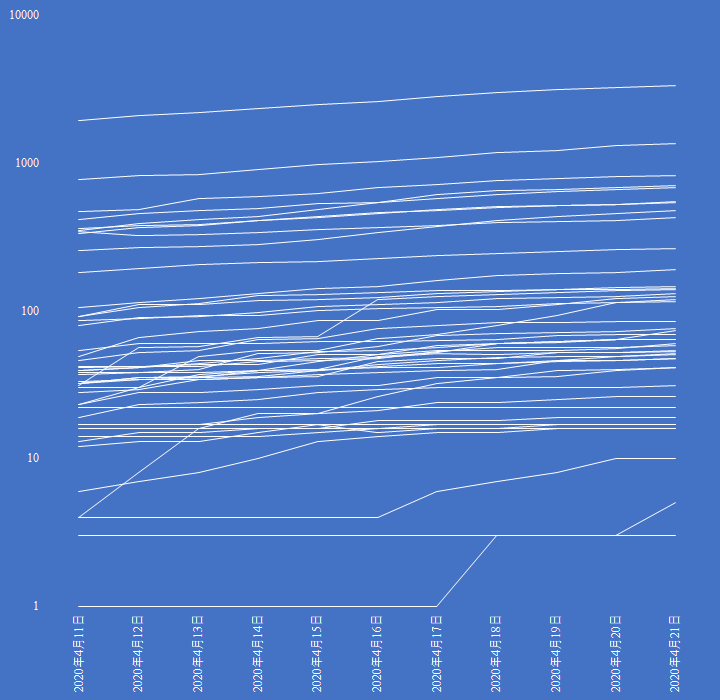
新型コロナウイルスのパンデミック宣言以降,Twitter でフォローしているアカウントに自然と相互協調の動きがみられる.
厚労省が「地域ごとのまん延の状況に関する指標等」の公表を開始。
— にゃんこそば (@ShinagawaJP) 2020年4月23日
都道府県ごとの①確定患者数、②リンクが不明な患者数、③相談件数、④PCR検査の実施数…と、必要な情報を一通り網羅しています。
が、ファイルはまさかのPDF形式。ExcelかCSVも提供してくれれば…https://t.co/Ox5rU6m1Xo
このツイートから始まった一連のやりとりで,厚労省の発表した PDF からテーブルを抽出するくだりに注目した.
失礼します。今、マクロソフト Power BI デスクトップを使用したところ無事PDFを読み込めました。また、列のピボット解除という機能を使うことで、クロス集計表を添付のような集計用フォーマットに加工できます。 pic.twitter.com/FEV0SBSito
— Akira Takao (@modernexcel7) 2020年4月23日
今回はここを画像つきで実施してみた.
“厚労省「地域ごとのまん延の状況に関する指標等」の PDF から Power BI Desktop でデータを抽出し EXCEL のグラフに表現する” の続きを読む
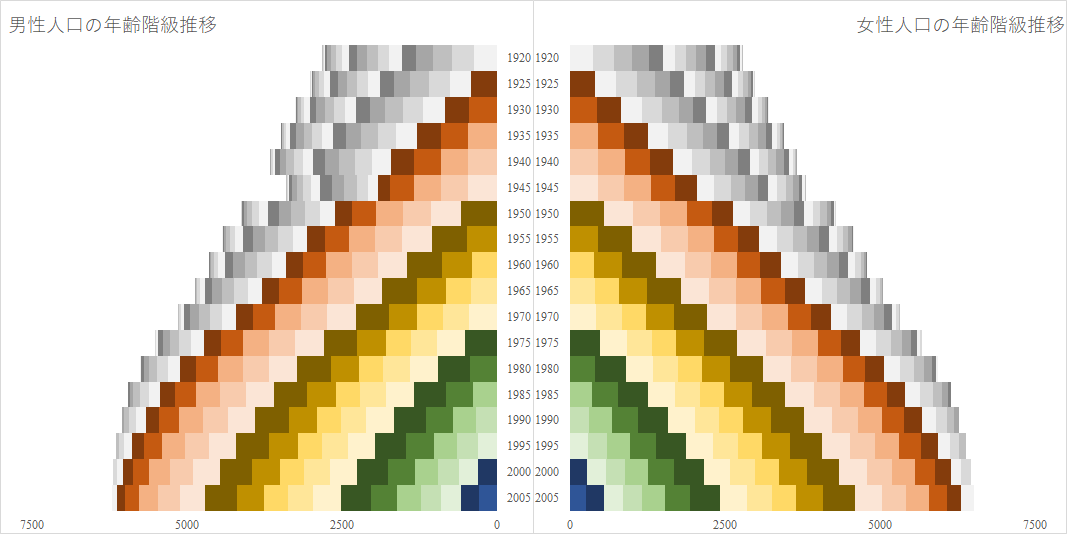
前回の記事では大正 9 年から平成 17 年までの日本人口総数の年齢階級推移を積み上げ縦棒グラフに描いた.今回は男女別に描く.
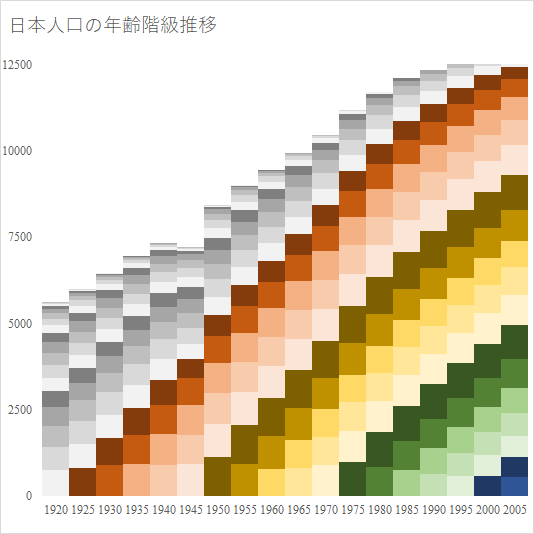
人口統計は最も重要な基幹統計の一つである.総務省の e-Stat は確かに有用であるが,かゆいところに手が届かない.例えば「市区町村ごと,年齢5歳階級ごとの人口構成の国勢調査ごとの推移を知りたい」という要求には全く無力である.
主として技術的な理由によるものと,統計調査の粒度の細かさによる.技術的な理由としては,データベースの画面表示セル数の上限を容易に超えてしまうデータ量になってしまうことである.しかし,根本的な理由は調査の粒度の細かさである.
2005 年以前と 2010 年以降とでは調査の精度が違う.今後は高精度なデータファイルが e-Stat に掲載されていくものと思われるが,2005 年以前に関しては都道府県より細かい粒度は存在しない.そこを求めると手作業になってしまい,現実的ではない.国立社会保障・人口問題研究所ならデータを持っているかもしれない.
2020 年は国勢調査の年にあたる.総務省にはできるだけ細かい粒度でのデータ掲載を望むものである.
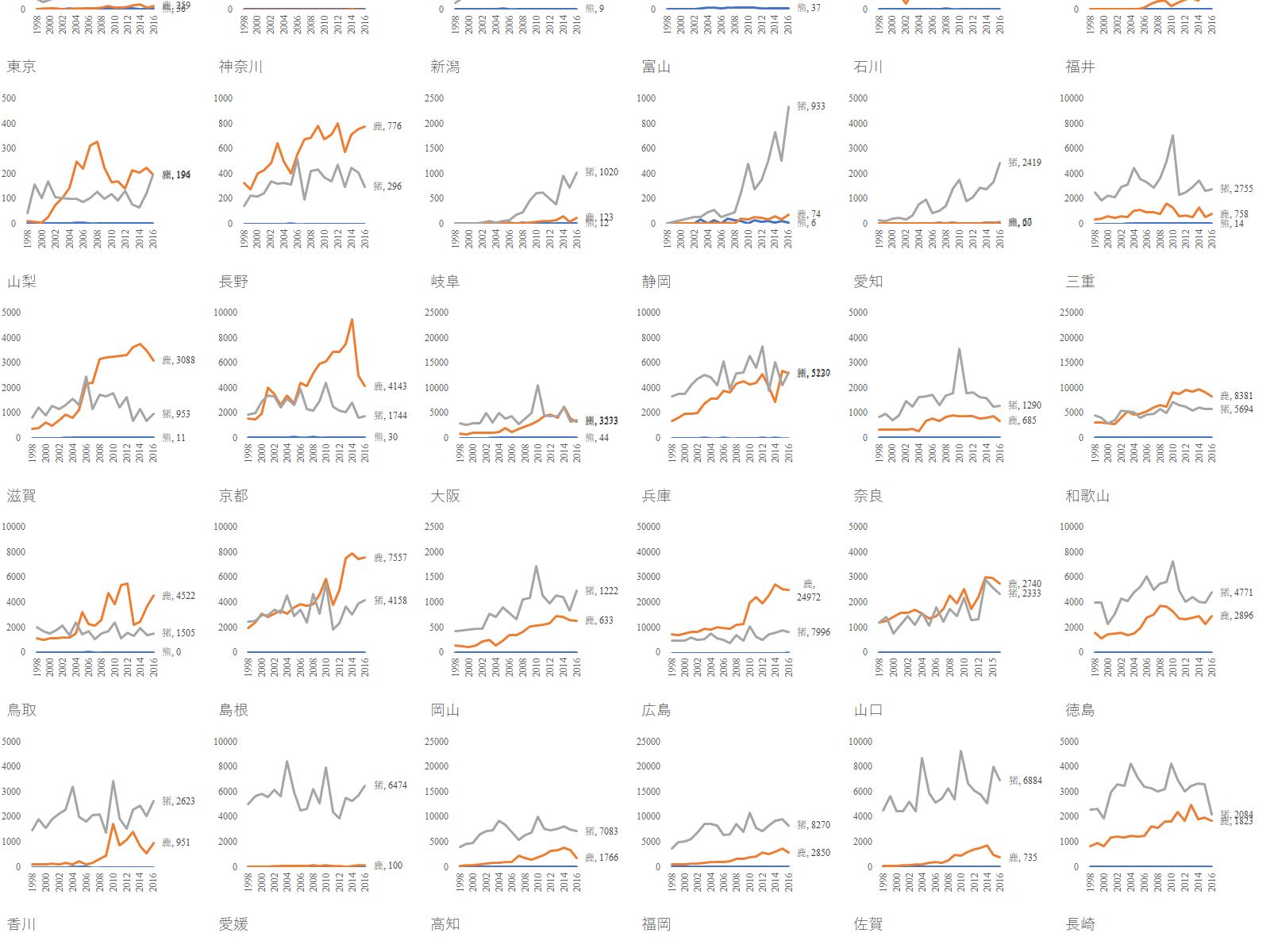
また面倒な統計を見つけてしまった.Power Query に食わせれば早いのかも知れないが,どうにも埒が明かないので手動でデータを整形することになった.頼むから第一正規形で公開してくれ…
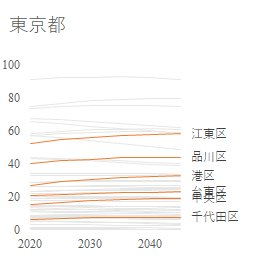
これまでは日本の都市人口の過去の推移を見てきた.総務省には日本の都市人口の推移予測がある.今回はこのデータをグラフにする.
データを可視化するにあたり,重要なのは引き算である.強調すべき系列のみを強調するために,VBA の知識が欠かせない.
グラフの系列にデータラベルを表示する方法にはいくつかある.
「おい,新米 Range オブジェクト!何ボーッと突っ立ってんだよ」
「す,すみません!」
「お前,名前は?」
「は,はい.myRng1と申します.よろしくお願いいたします」
「仕事に来たら,まず名乗れ.それがここの流儀だ」
「それから,自分の職域も一緒に言うんだ.わかったか?」
「は,はい」
「最初に書いてあるだろ?Option Explicit ってな.俺も詳しくは知らねぇが,あのルールは絶対だ.名乗らない奴に居場所はない…ほら,仕事が来たぞ」
「何い?誰だ,こんな糞コード書いたのは?ワークシートに何回アクセスさせる気だよ,全く…ほれ,ここからあそこまで走って値を取ってこい」
「ここからあそこまでって…えーっ?本気で言ってます?」
「何言ってるんだ?ワークシートにアクセスするような力仕事は新米 Range オブジェクトの役割と相場が決まってるんだ.さあ行った行った」
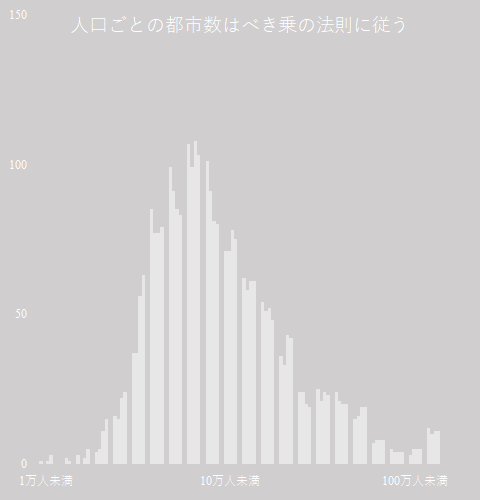
総務省統計ポータル e-Stat からのデータに全国の市区町村の人口推移があった.マーク・ブキャナンの「歴史はべき乗則で動く」の p 261 に「人口が半分の都市は四つある」とある.本当だろうか.検証してみた.