SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.

Co-evolution of human and technology

SQL Serverでサブクエリとウィンドウ関数のパフォーマンスを比較した.用いたデータベースはHeatStrokeDBで,熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するで作成したものである.
比較するツールはSET STATISTCS PROFILE ONコマンドである.クエリストアは筆者の環境では機能しなかった.
二乗平均平方根誤差とは英語では Root Mean Squared Error (RMSE) と書く.真値と予測値との乖離(誤差)を二乗し,その平均値をとり,その平方根を求めた値のことである.非負の値を取り,0に近いほど優れたモデルであることを示唆する.
今回使用するのはe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析するで使用したデータベースである.先の記事では回帰モデルを評価する指標が必要との認識であった.
都道府県別の熱中症搬送人員数の予測と実際をEXCELの組み合わせグラフで描くでは独立変数として日最高気温,日平均水蒸気圧,65歳以上人口,人口密度を投入し都道府県別の熱中症搬送人員数を予測した.以前の記事ではe-Statからの社会疫学的指標を加えて熱中症搬送人員数を分析した.社会疫学的指標としては日最高気温,日平均水蒸気圧,都道府県人口に加えて過去30日間の平均気温,エアコン保有台数,年間収入のジニ係数,光熱・水道費,実収入,第1次産業就業者比率,第2次産業就業者比率,都市公園数,都市緑化割合,自然公園割合,自然公園数,生活保護被保護人員である.
今回は社会疫学的指標を独立変数として加えた熱中症搬送人員数の予測と実際を示す.
国勢調査の結果がeStatに掲載され始めている.今回は小地域の境界データをダウンロードし,SQL Serverにアップロードするまでの記録を記す.
ROC曲線の閾値を求めるストアドプロシージャまたはインラインテーブル値関数をSQL Serverで定義するでは単一のレコードを返すストアドプロシージャ,またはインラインテーブル値関数を作成した.今回は引数の最小値と最大値を渡して複数行のレコードセットをテーブルとして返すストアドプロシージャ,またはユーザー定義のインライン関数を定義したい.
“複数行のレコードセットをテーブルとして返すストアドプロシージャまたはユーザー定義のインラインテーブル値関数をSQL Serverで定義する” の続きを読む
前回の記事では階乗の自然対数を求めるユーザー定義関数をSQL Serverで作成するを記述した.今回はそのユーザー定義関数を用いてFisherの直接確率を求めるストアドプロシージャを記述する.
ウィンドウ関数は比較的新しい技術である.筆者は正直,SQL が苦手だ.IPA の試験が終わったのでデータベース関連の勉強を再開している.

熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定するでは最高気温と搬送人員との相関関係を解析した.今回は水蒸気圧と搬送人員との関係を可視化し,閾値を求めた.重症度別の搬送人員についての検討は日平均蒸気圧と熱中症の重症度別搬送人員との関連を調べるに記述した.
前章では,空間参照系の背後にある理論を紹介し,異なる種類のシステムが地球上の特徴を記述する方法を説明した.本章では,これらのシステムを適用して SQL Server 2008 における新しい空間データ型を使って空間情報を蓄積する方法を学んでもらう.
“第 2 章 SQL Server 2008 で空間データを実装する (Beginning Spatial with SQL Server 2008)” の続きを読む
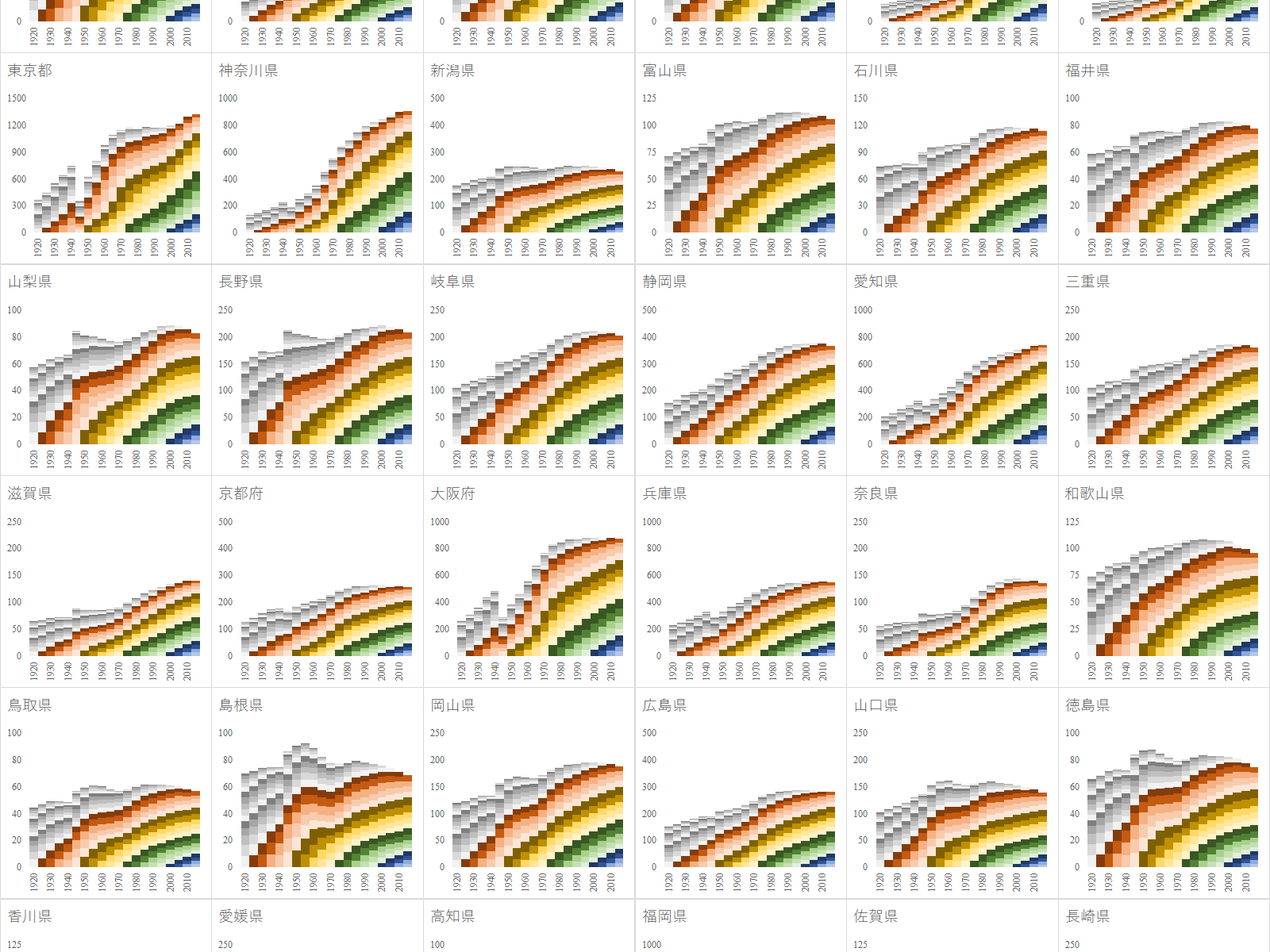
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.