国勢調査の結果がeStatに掲載され始めている.今回は小地域の境界データをダウンロードし,SQL Serverにアップロードするまでの記録を記す.
eStatから国勢調査の小地域の境界データをダウンロードしSQL Serverにアップロードする


Co-evolution of human and technology
国勢調査の結果がeStatに掲載され始めている.今回は小地域の境界データをダウンロードし,SQL Serverにアップロードするまでの記録を記す.
SQL Server でウィンドウ関数を使い,1行前の行を取得するではウィンドウ関数を用いて1行前の行を取得した.今回は RANK 関数,NTILE 関数を用いて順位,四分位を得る.
SQL Server でウィンドウ関数を使い,1行前の行を取得するではウィンドウ関数を用いて1行前の行を取得した.今回は LAG 関数を用いて1行前の行を取得する.
ウィンドウ関数は比較的新しい技術である.筆者は正直,SQL が苦手だ.IPA の試験が終わったのでデータベース関連の勉強を再開している.
前章では,空間参照系の背後にある理論を紹介し,異なる種類のシステムが地球上の特徴を記述する方法を説明した.本章では,これらのシステムを適用して SQL Server 2008 における新しい空間データ型を使って空間情報を蓄積する方法を学んでもらう.
“第 2 章 SQL Server 2008 で空間データを実装する (Beginning Spatial with SQL Server 2008)” の続きを読む
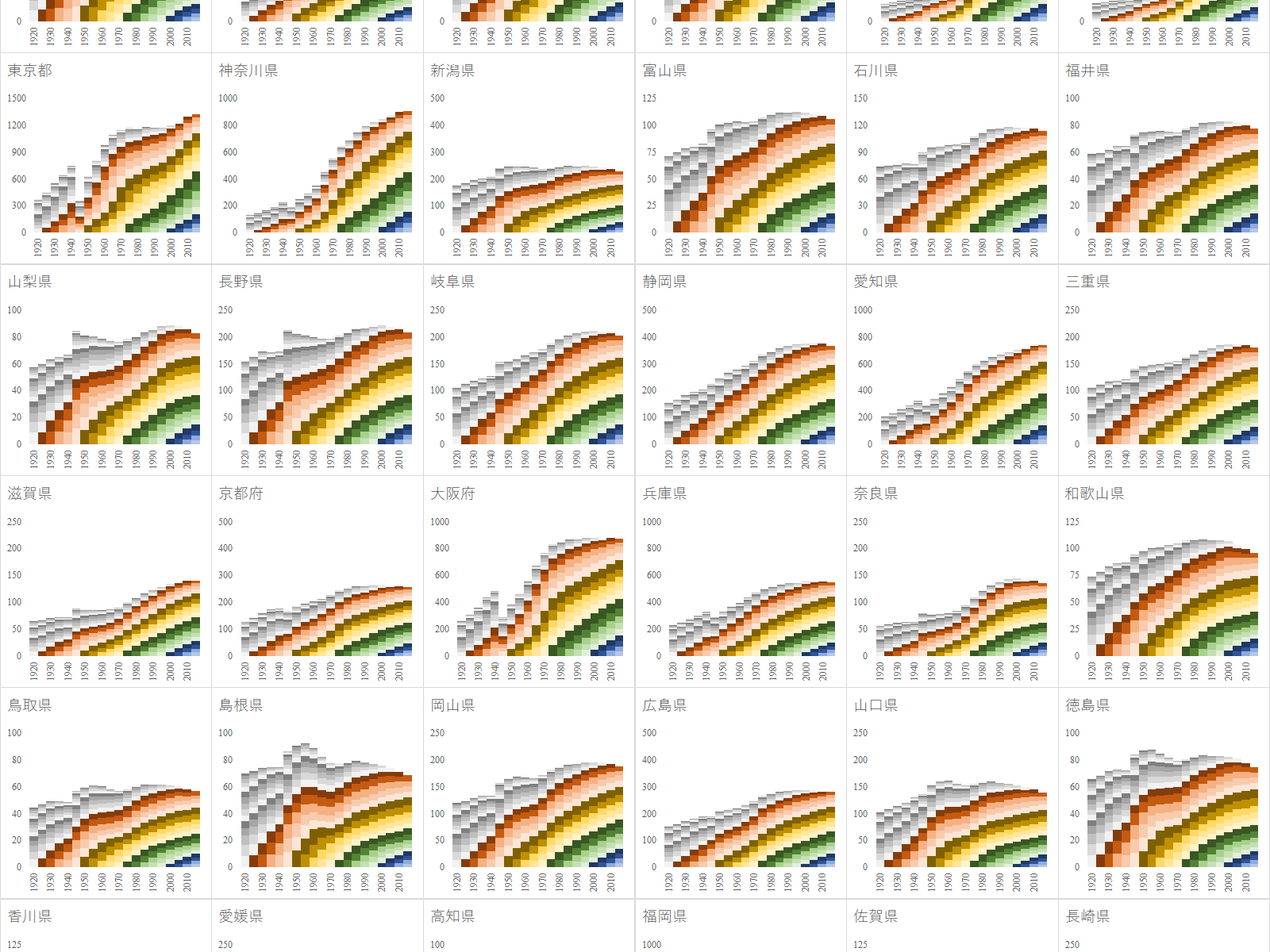
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
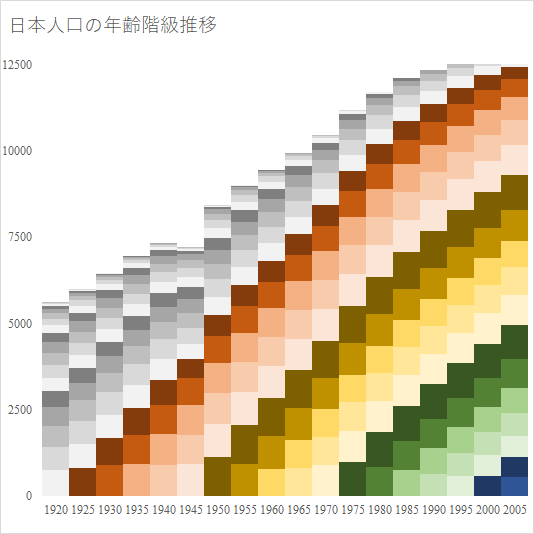
人口統計は最も重要な基幹統計の一つである.総務省の e-Stat は確かに有用であるが,かゆいところに手が届かない.例えば「市区町村ごと,年齢5歳階級ごとの人口構成の国勢調査ごとの推移を知りたい」という要求には全く無力である.
主として技術的な理由によるものと,統計調査の粒度の細かさによる.技術的な理由としては,データベースの画面表示セル数の上限を容易に超えてしまうデータ量になってしまうことである.しかし,根本的な理由は調査の粒度の細かさである.
2005 年以前と 2010 年以降とでは調査の精度が違う.今後は高精度なデータファイルが e-Stat に掲載されていくものと思われるが,2005 年以前に関しては都道府県より細かい粒度は存在しない.そこを求めると手作業になってしまい,現実的ではない.国立社会保障・人口問題研究所ならデータを持っているかもしれない.
2020 年は国勢調査の年にあたる.総務省にはできるだけ細かい粒度でのデータ掲載を望むものである.