
新型コロナウイルスのパンデミック宣言以降,Twitter でフォローしているアカウントに自然と相互協調の動きがみられる.
厚労省が「地域ごとのまん延の状況に関する指標等」の公表を開始。
— にゃんこそば (@ShinagawaJP) 2020年4月23日
都道府県ごとの①確定患者数、②リンクが不明な患者数、③相談件数、④PCR検査の実施数…と、必要な情報を一通り網羅しています。
が、ファイルはまさかのPDF形式。ExcelかCSVも提供してくれれば…https://t.co/Ox5rU6m1Xo
このツイートから始まった一連のやりとりで,厚労省の発表した PDF からテーブルを抽出するくだりに注目した.
失礼します。今、マクロソフト Power BI デスクトップを使用したところ無事PDFを読み込めました。また、列のピボット解除という機能を使うことで、クロス集計表を添付のような集計用フォーマットに加工できます。 pic.twitter.com/FEV0SBSito
— Akira Takao (@modernexcel7) 2020年4月23日
今回はここを画像つきで実施してみた.
PDF への接続
データソースは地域ごとのまん延の状況に関する指標等の公表についてである.ファイル名は 2020 年 4 月 24 日時点で 000624135 となっている.
EXCEL の Power Query では PDF に接続できない
PDF ファイルからデータを抽出したくても,EXCEL の Power Query からではできない.そのため Power BI Desktop を使う必要がある.
Power BI Desktop のインストールについてはこちらを参照されたい.
Excelだとデータの取得と変換というメニューがあるのですが、まだPDFには対応していなかったようなので、PowerBIから作りました。
— Akira Takao (@modernexcel7) 2020年4月23日
にゃんこそばさんの分析をいつも楽しみにしていますので、お役に立てれば幸いです!https://t.co/DSAWDdKwXO
Power BI Desktopを起動

「ホーム」「データを取得」「詳細」
ホームタブの「データを取得」を押下し最下部の「詳細…」を選ぶ.
「ファイル」「PDF」
「データを取得」ウィンドウで「ファイル」から「PDF」を選ぶとファイルパスを指定するよう促される.指定して OK をクリックする.
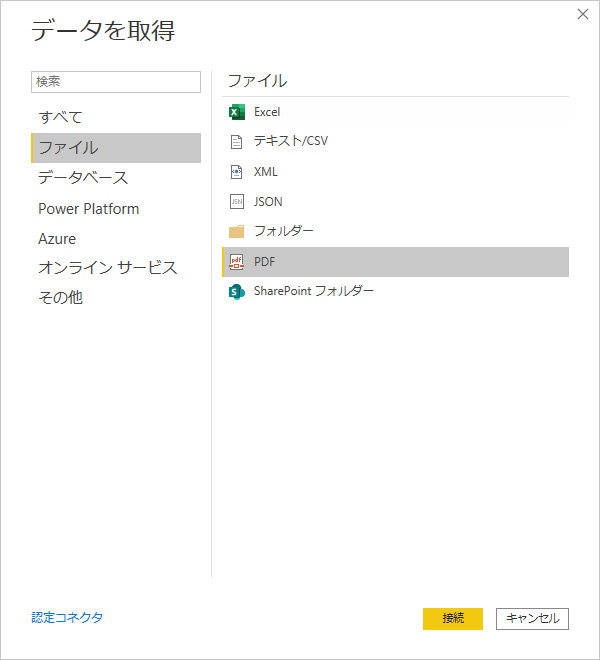
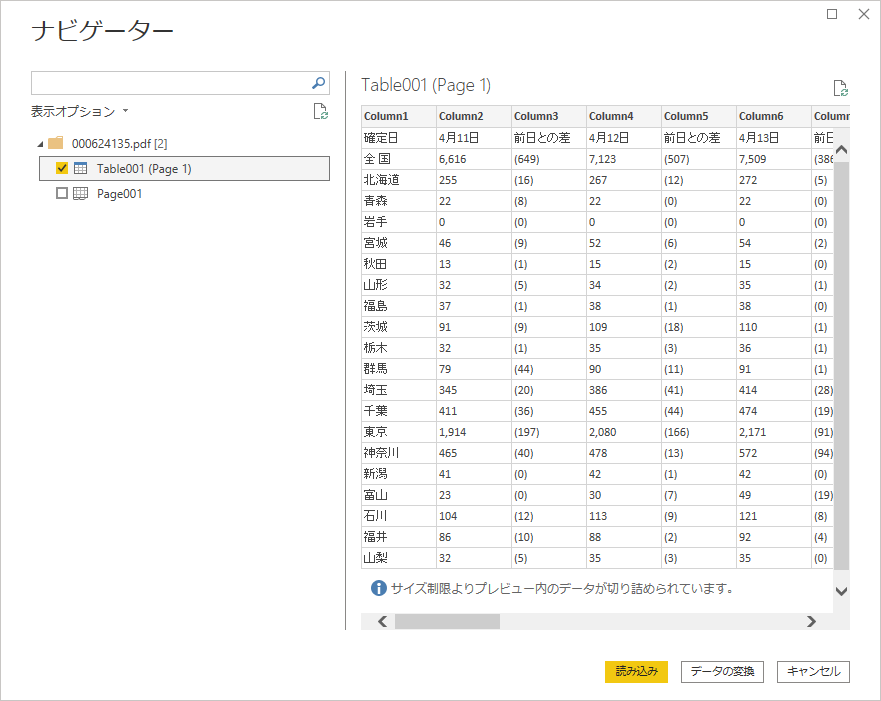
Table001(Page 1)のチェックを入れ、「データの変換」
下図のようにナビゲーターウィンドウが開く.チェックボックスが 2 つあるので Table001(Page 1) にチェックを入れ,「データの変換」をクリックする.
Power Query による加工
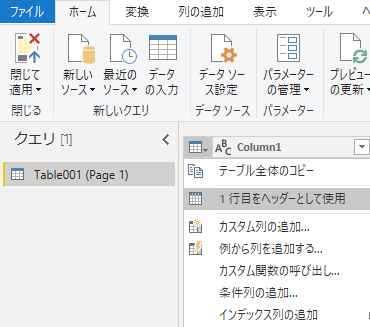
「変換」「1行目をヘッダーとして使用」
ここからデータの整形に入る.主な作業はピボット解除である.その前にヘッダー行を指定する.「1行目をヘッダーとして使用」を選ぶ.
「確定日」列を選択したまま右クリックし「その他の列のピボット解除」
ピボット解除すべき列の数が不定の場合には,解除しない列を指定しておいて「その他の列のピボット解除」を使う.
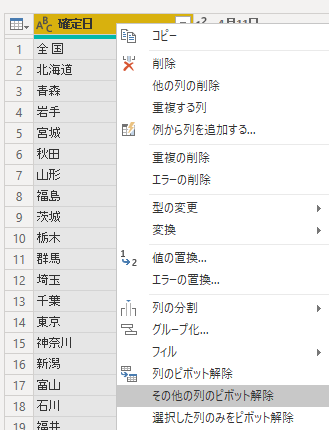
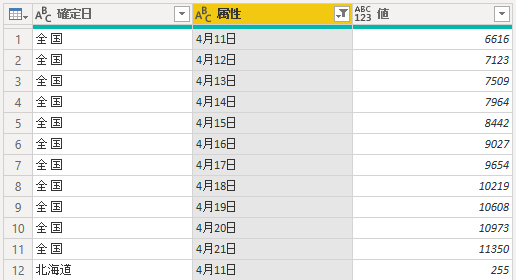
結果はこうなる.「属性」「値」という名前の列ができる.「属性」列のフィールド内に「前日との差」という値が見える.今回,これはグラフ化の邪魔になるので削除したい.
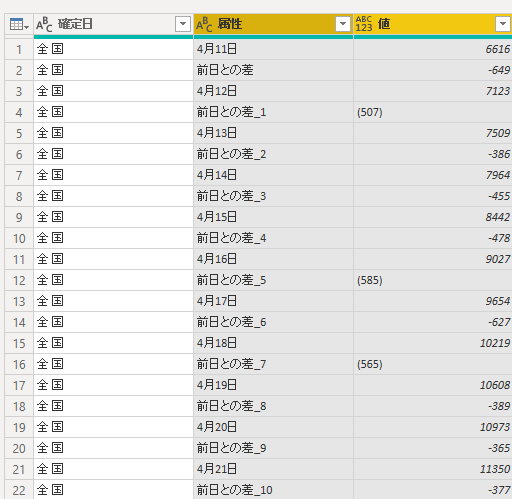
「属性」列のフィルター▼をクリックし「テキスト フィルター」「指定の値を含まない」
そこで列のフィルターを使って除外する.「テキストフィルター」のうち「指定の値を含まない」である.
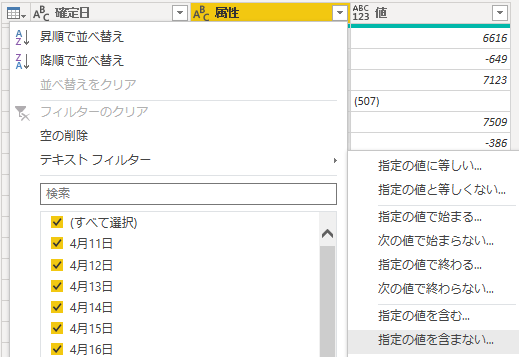
「前日との差」とタイプ入力し「OK」
「行のフィルター」ウィンドウが開くので『前日との差』とキーボードからタイプ入力し,OK をクリックする.
結果はこうなる.
「ホーム」「閉じて適用」
「閉じて適用」する.
クエリの詳細
上記操作の記録を記述したクエリである.
let
ソース = Pdf.Tables(File.Contents("C:\Users\UserName\Dropbox\20200424COVID19\000624135.pdf")),
Table001 = ソース{[Id="Table001"]}[Data],
昇格されたヘッダー数 = Table.PromoteHeaders(Table001, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"確定日", type text}, {"4月11日", Int64.Type}, {"前日との差", Int64.Type}, {"4月12日", Int64.Type}, {"前日との差_1", type text}, {"4月13日", Int64.Type}, {"前日との差_2", Int64.Type}, {"4月14日", Int64.Type}, {"前日との差_3", Int64.Type}, {"4月15日", Int64.Type}, {"前日との差_4", Int64.Type}, {"4月16日", Int64.Type}, {"前日との差_5", type text}, {"4月17日", Int64.Type}, {"前日との差_6", Int64.Type}, {"4月18日", Int64.Type}, {"前日との差_7", type text}, {"4月19日", Int64.Type}, {"前日との差_8", Int64.Type}, {"4月20日", Int64.Type}, {"前日との差_9", Int64.Type}, {"4月21日", Int64.Type}, {"前日との差_10", Int64.Type}}),
ピボット解除された他の列 = Table.UnpivotOtherColumns(変更された型, {"確定日"}, "属性", "値"),
フィルターされた行 = Table.SelectRows(ピボット解除された他の列, each not Text.Contains([属性], "前日との差"))
in
フィルターされた行
Excel での作業
左側の三つのアイコンのうち真ん中の表をクリック
ウィンドウ左側にあるアイコンは上から順にレポート,データ,モデルという.アイコンの形状から想像できるが,それぞれデータの構造を象徴している.レポートは EXCEL ではグラフに該当するが,表現力は正直 Power BI の方が上である.
今回は EXCEL へのデータ移行を目的とするため,真ん中のデータアイコンをクリックし,テーブルを表示する.
右側フィールドの中の『Table001 (Page1 )』を右クリックし「テーブルのコピー」
右クリックしても,右側の縦 3 つの点をクリックしても同じメニューが出現するが,「テーブルのコピー」を選ぶ.クリップボードにデータがコピーされる.
Excel へ貼り付け
EXCEL のワークシートに貼り付け,テーブルに変換する.確定日が月と日しかないため,右隣のセルに
="2020年"&[確定日]
とタイプし,さらに右隣のセルに DATEVALUE 関数を適用して確実に年月日として確定する.
人数が文字列として認識されている場合は
=[値]*1
などと数式を使って数値と認識させる.共に「値のみ貼り付け」してセルの参照関係を解消しておく.
折れ線グラフの追加
新規ワークシートを追加し,空白の折れ線グラフを追加作成する.
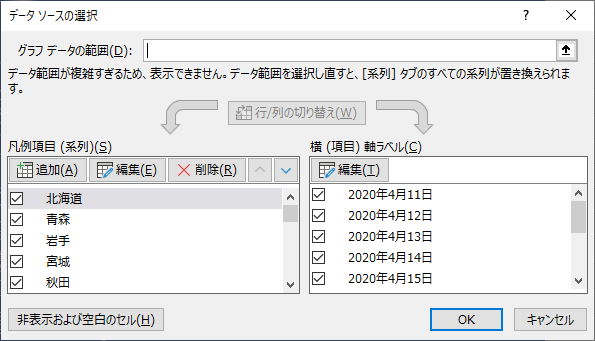
データ系列の追加
グラフ内部を右クリックして「データの選択…」を選び,系列を 47 個追加して,テーブルの各都道府県名を「系列名」に指定し,確定患者数のセル範囲を「値」に指定する.横軸ラベルの「編集」をクリックし,全国の「確定日」のセル範囲を指定する.
縦軸の書式は初期の「線形」のままではなく,「対数」にしておく.これには疫学的理由があるが,詳細には踏み込まないでおく.
書式を設定するコード
下記コードを標準モジュールに記述し,F5 を押下して実行する.
Sub ChartFormat()
Dim mySht1 As Worksheet
Dim myCht As Chart
Dim mySeries As Series
Dim myPoint As Point
Dim myLine As LineFormat
Dim myAxis As Axis
Set mySht1 = Worksheets("Sheet2")
Set myCht = mySht1.ChartObjects(1).Chart
With myCht
For Each mySeries In .SeriesCollection
For Each myPoint In mySeries.Points
myPoint.Format.Fill.ForeColor.RGB = RGB(255, 255, 255)
Next myPoint
Set myLine = mySeries.Format.Line
With myLine
.ForeColor.RGB = RGB(255, 255, 255)
.Weight = 0.25
End With
Next mySeries
With .ChartArea
.Format.Line.Visible = msoFalse
.Format.Fill.ForeColor.ObjectThemeColor = msoThemeColorAccent1
.Format.TextFrame2.TextRange.Font.Name = "TimesNewRoman"
.Format.TextFrame2.TextRange.Font.Fill.ForeColor.RGB = RGB(255, 255, 255)
End With
Set myAxis = .Axes(xlCategory)
With myAxis
.Format.Line.Visible = msoFalse
.MajorGridlines.Format.Line.Visible = msoFalse
End With
Set myAxis = .Axes(xlValue)
With myAxis
.Format.Line.Visible = msoFalse
.MajorGridlines.Format.Line.Visible = msoFalse
End With
End With
End Sub
結果
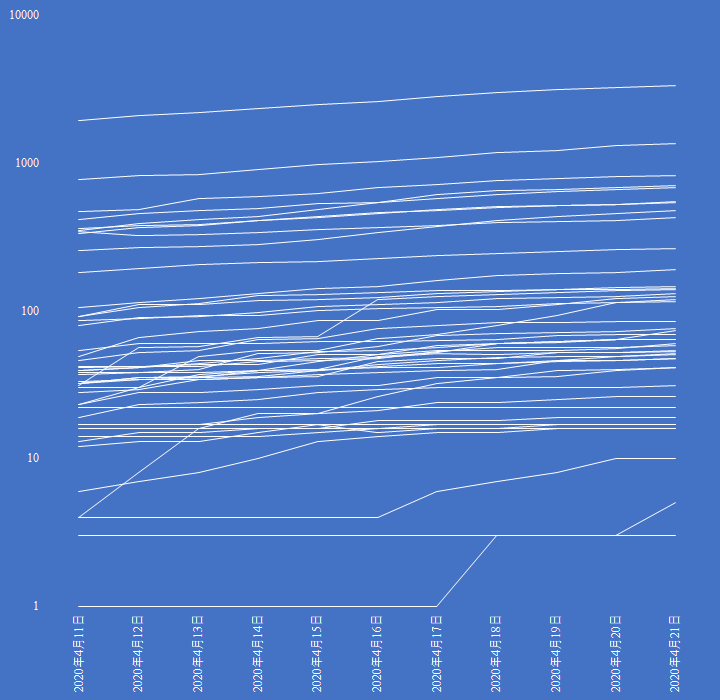
新型コロナウイルス確定患者数の推移
結果を示す.筆者は疫学が専門ではないため,考察には踏み込まず,専門家に委ねる.
まとめ
厚労省の公開した PDF ファイルを元に各都道府県のコロナウイルス確定患者数の推移を折れ線グラフに表現した.
PDF ファイルからのデータ抽出には EXCEL の Power Query は未対応で,Power BI Desktop が必要であった.厚労省には csv ファイルまたは EXCEL でファイル形式でのデータ公開を求めたい.
方法はすでに Akira Takao (@modernexcel7) さんが公開してくれている.筆者はその方法を画像つきで解説した.
追加情報:空のクエリ
さらに Akira Takao さんから追加情報が寄せられたので紹介しておく.
ExcelのPower Queryから直でPDFの取り込みができました!GUIにはないけど、空のクエリで打ち込めばよかったんですね。ありがとうございました!
— Akira Takao (@modernexcel7) 2020年4月24日
= Pdf.Tables(File.Contents("C:\データソース\PDF文書.pdf")) https://t.co/7JvDEyBl3g
「データの取得」「その他のデータソースから」「空のクエリ」
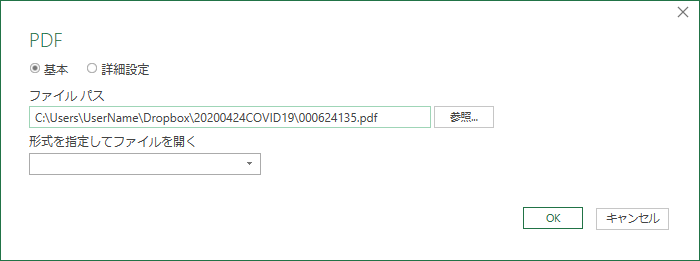
ファイルパスの指定
ファイルパスを指定するよう促されるので入力する.
ファイルパスが正しければ下図のようにファイルのアイコンが示される.
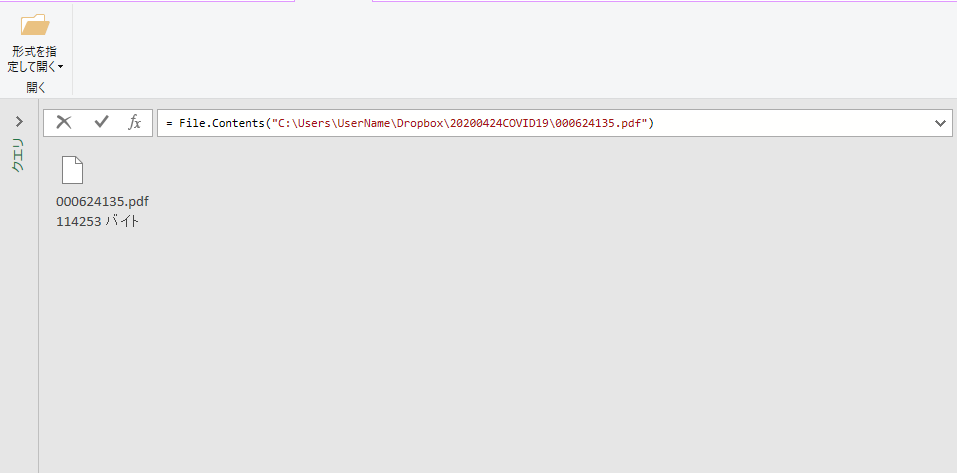
ファイルをダブルクリックして開く
ダブルクリックして開くと見慣れた Power Query 画面へと遷移する.
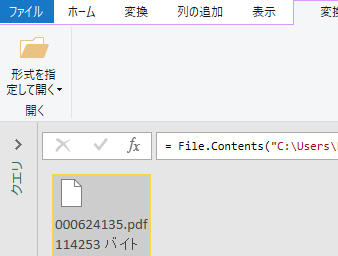
読み込まれるレコード
読み込まれたのは 2 行のみだが,Id 列をよく見ると Page001 および Table001 とある.ここで必要なのはテーブルの方である.

上位1行を削除
「上位の行の削除」で Page001 を削除していく.
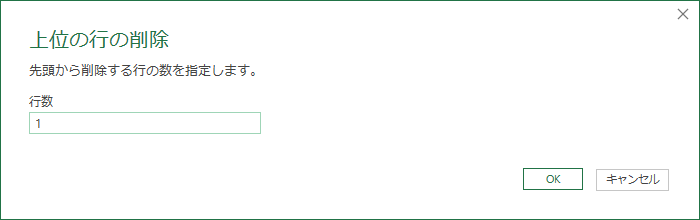
結果として Table001 の行が残る.

Data 列を展開する
Data という名前の列が展開できそうなので,アイコンをクリックしてみる.
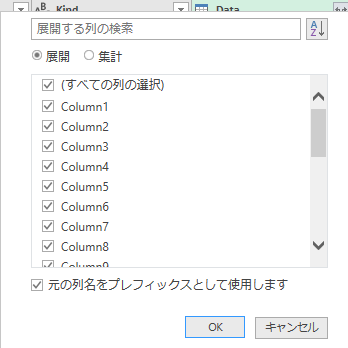
展開された結果である.ここからは定型的な作業になってくる.

データの加工
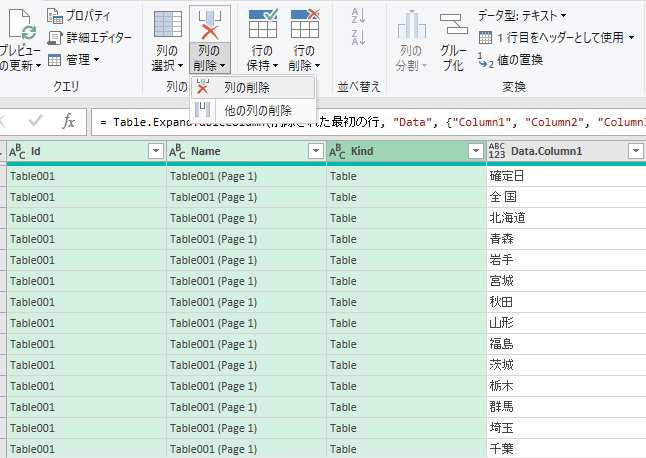
ID, Name, Kind の3列は不要なので削除する.
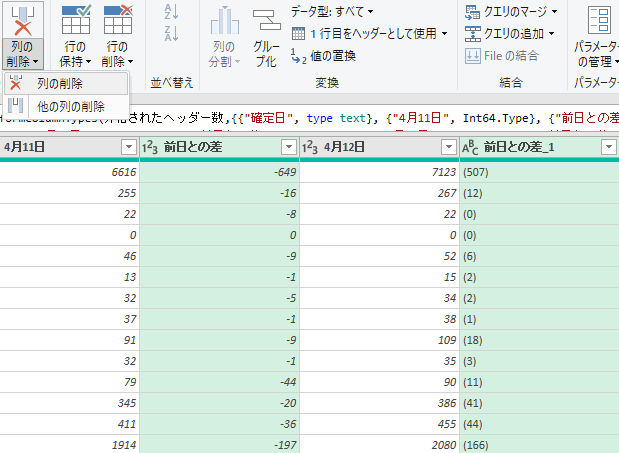
「前日との差」という列も不要なので削除する.
このあたりまで来ると見慣れた画面になってくる.「その他の列のピボット解除」を行う.
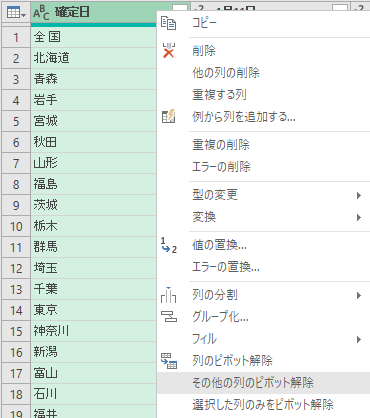
ピボット解除後の状態だが,列名がおかしいので修正しておく.
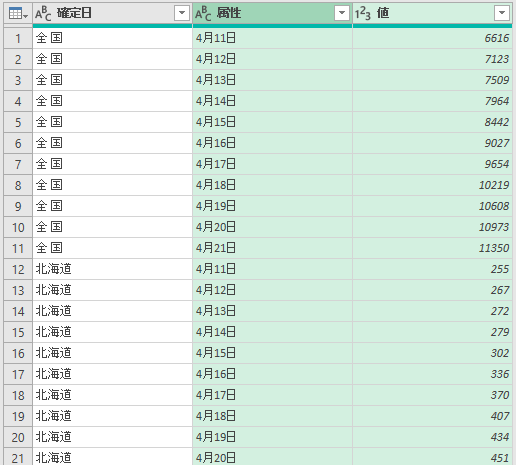
最後に「閉じて読み込む」と結果はこうなる.
詳細クエリ
let
ソース = Pdf.Tables(File.Contents("C:\Users\UserName\Dropbox\20200424COVID19\000624135.pdf")),
削除された最初の行 = Table.Skip(ソース,1),
#"展開された Data" = Table.ExpandTableColumn(削除された最初の行, "Data", {"Column1", "Column2", "Column3", "Column4", "Column5", "Column6", "Column7", "Column8", "Column9", "Column10", "Column11", "Column12", "Column13", "Column14", "Column15", "Column16", "Column17", "Column18", "Column19", "Column20", "Column21", "Column22", "Column23"}, {"Data.Column1", "Data.Column2", "Data.Column3", "Data.Column4", "Data.Column5", "Data.Column6", "Data.Column7", "Data.Column8", "Data.Column9", "Data.Column10", "Data.Column11", "Data.Column12", "Data.Column13", "Data.Column14", "Data.Column15", "Data.Column16", "Data.Column17", "Data.Column18", "Data.Column19", "Data.Column20", "Data.Column21", "Data.Column22", "Data.Column23"}),
削除された列 = Table.RemoveColumns(#"展開された Data",{"Id", "Name", "Kind"}),
昇格されたヘッダー数 = Table.PromoteHeaders(削除された列, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"確定日", type text}, {"4月11日", Int64.Type}, {"前日との差", Int64.Type}, {"4月12日", Int64.Type}, {"前日との差_1", type text}, {"4月13日", Int64.Type}, {"前日との差_2", Int64.Type}, {"4月14日", Int64.Type}, {"前日との差_3", Int64.Type}, {"4月15日", Int64.Type}, {"前日との差_4", Int64.Type}, {"4月16日", Int64.Type}, {"前日との差_5", type text}, {"4月17日", Int64.Type}, {"前日との差_6", Int64.Type}, {"4月18日", Int64.Type}, {"前日との差_7", type text}, {"4月19日", Int64.Type}, {"前日との差_8", Int64.Type}, {"4月20日", Int64.Type}, {"前日との差_9", Int64.Type}, {"4月21日", Int64.Type}, {"前日との差_10", Int64.Type}}),
削除された列1 = Table.RemoveColumns(変更された型,{"前日との差", "前日との差_1", "前日との差_2", "前日との差_3", "前日との差_4", "前日との差_5", "前日との差_6", "前日との差_7", "前日との差_8", "前日との差_9", "前日との差_10"}),
ピボット解除された他の列 = Table.UnpivotOtherColumns(削除された列1, {"確定日"}, "属性", "値"),
#"名前が変更された列 " = Table.RenameColumns(ピボット解除された他の列,{{"確定日", "都道府県"}, {"属性", "確定日"}, {"値", "確定患者数"}})
in
#"名前が変更された列 "