
件の統計は復興庁の全国の避難者の数(所在都道府県別・所在施設別の数にあるが,このページはトップページから辿ることができず,検索からのみ到達できる.時系列でのデータは必須と思われるが,トップページから辿れるのは最新の情報のみであり,これは国民の利益に反する.
SQL Server の RANK 関数,NTILE 関数で順位,四分位を取得する
SQL Server でウィンドウ関数を使い,1行前の行を取得するではウィンドウ関数を用いて1行前の行を取得した.今回は RANK 関数,NTILE 関数を用いて順位,四分位を得る.
eStatの地図で見る統計(統計GIS)データダウンロードから小地域の境界データをダウンロードし,人口密度をQGISで表現する
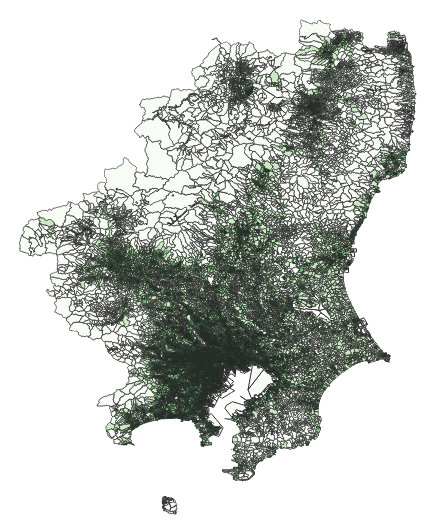
国勢調査をもとに作成された境界データダウンロードサービスがある.市区町村よりも更に細かい,町字の粒度でのGISデータである.今回は関東地方のデータをダウンロードし,QGISで人口密度を可視化する.
“eStatの地図で見る統計(統計GIS)データダウンロードから小地域の境界データをダウンロードし,人口密度をQGISで表現する” の続きを読む
都道府県ごとの河川データを1つのcsvファイルに変換する
河川データを都道府県別ではなく,水域別に抽出したい.そんな動機から QGIS と EXCEL の間を行ったり来たりしている.QGISで都道府県ごとの河川データをマージするではかなり無謀なことをやった.今回はもう少し丁寧にデータを扱ってみたい.
アメリカ合衆国の税務情報を送信する

Google AdSense をこのブログで使用しているが,米国租税条約が適用されるため,フォーム W-8BEN から免除を申請した.
QGISで都道府県ごとの河川データをマージする
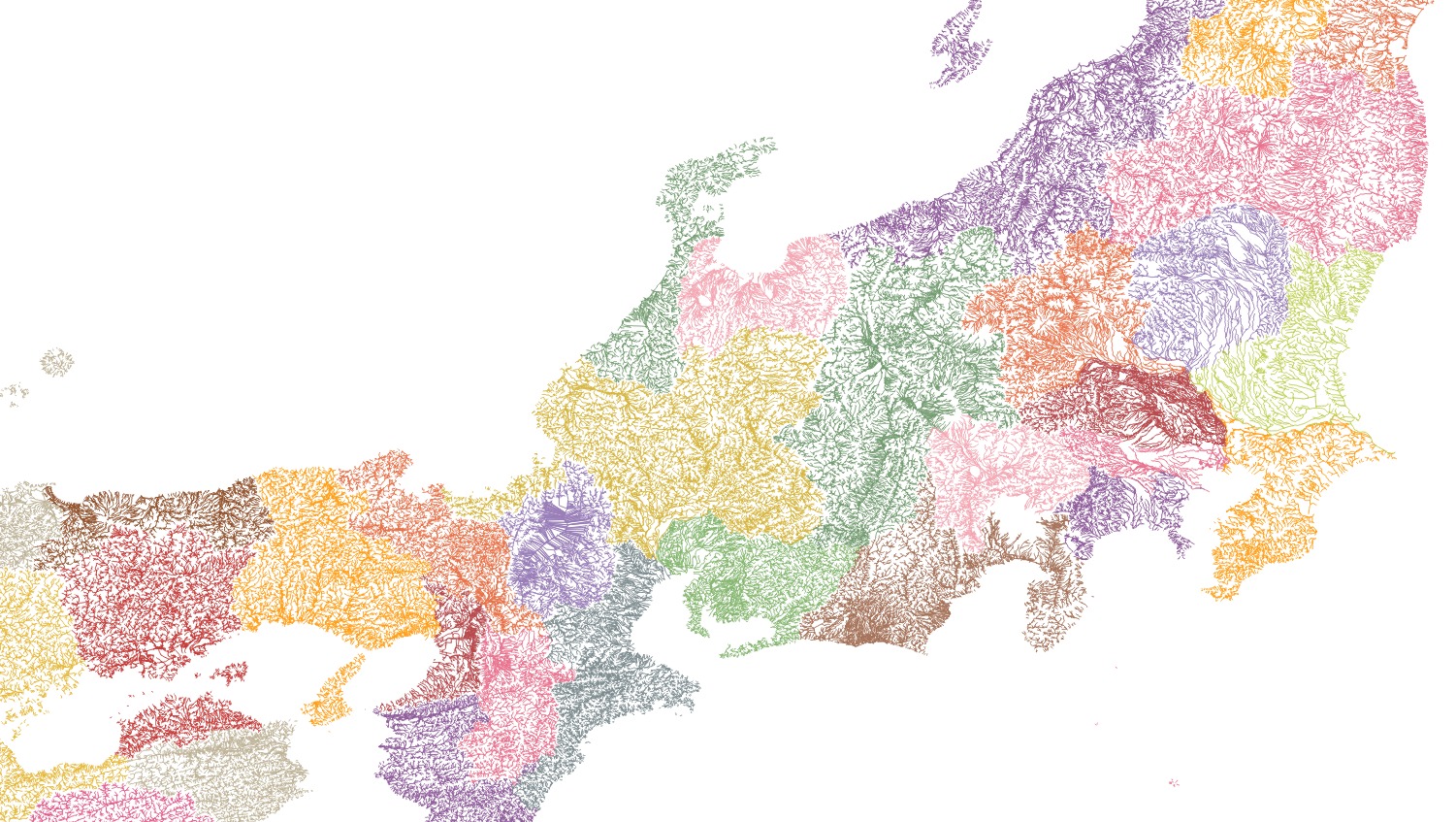
国土数値情報の河川データは都道府県ごとに分かれており,一つのシェープファイルに結合したかった.調べてみると QGIS でできそうだったので実行してみた.
国土数値情報の河川データをダウンロードして SQL Server 2008 R2 にアップロードできなかった話
行政区域データは Polygon であったが,河川データは Line と Point である.河川端点を表現するのに Point が使われている.
“国土数値情報の河川データをダウンロードして SQL Server 2008 R2 にアップロードできなかった話” の続きを読む
位置参照情報ダウンロードサービスから見る国土の形
国土交通省のサービスの一つに位置参照情報ダウンロードサービスがある.何気なくファイルをダウンロードして,思いがけない発見があったため,記事を書くことにした.
1920年から2015年までの都道府県別の5歳階級別人口推移
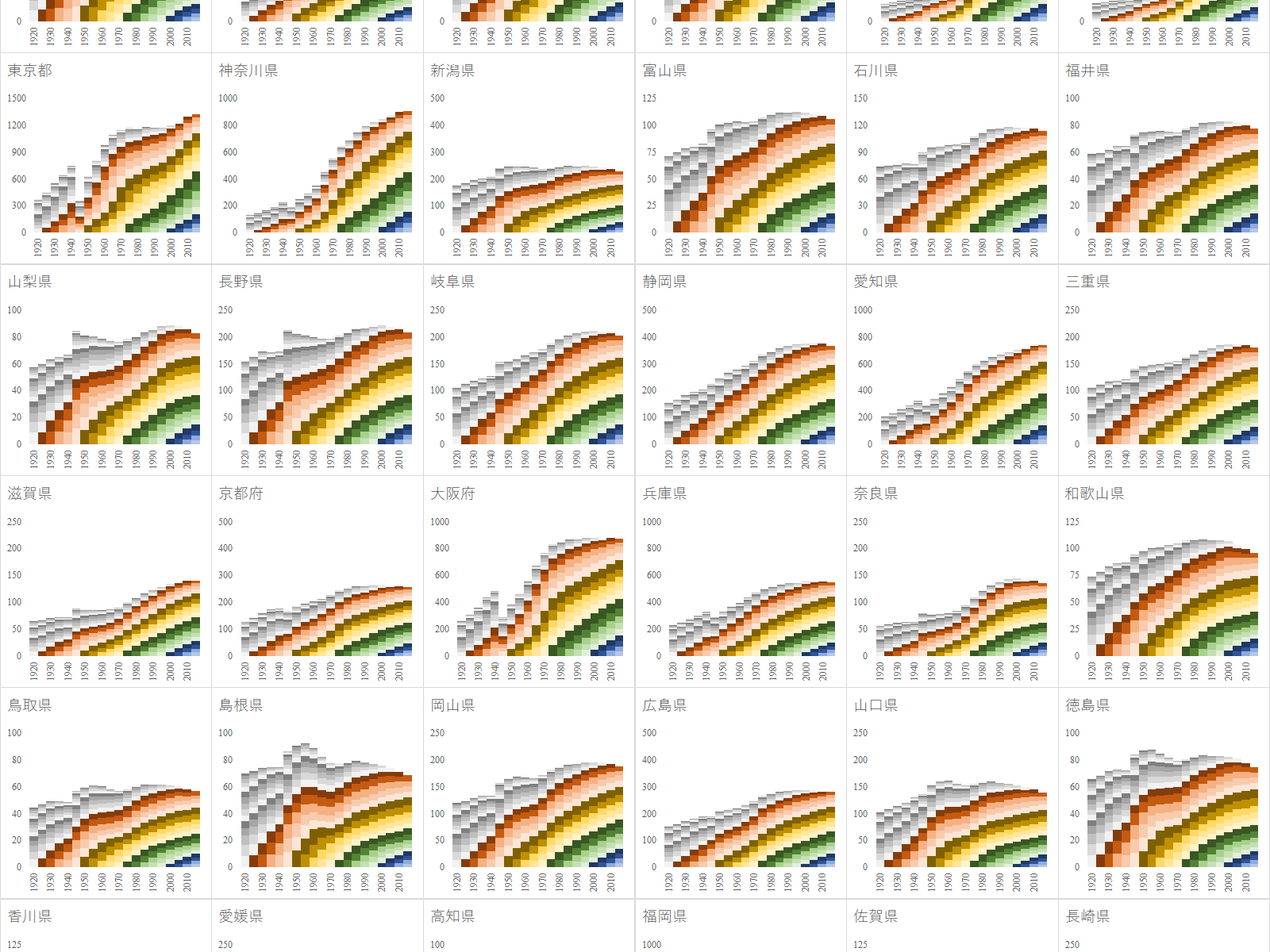
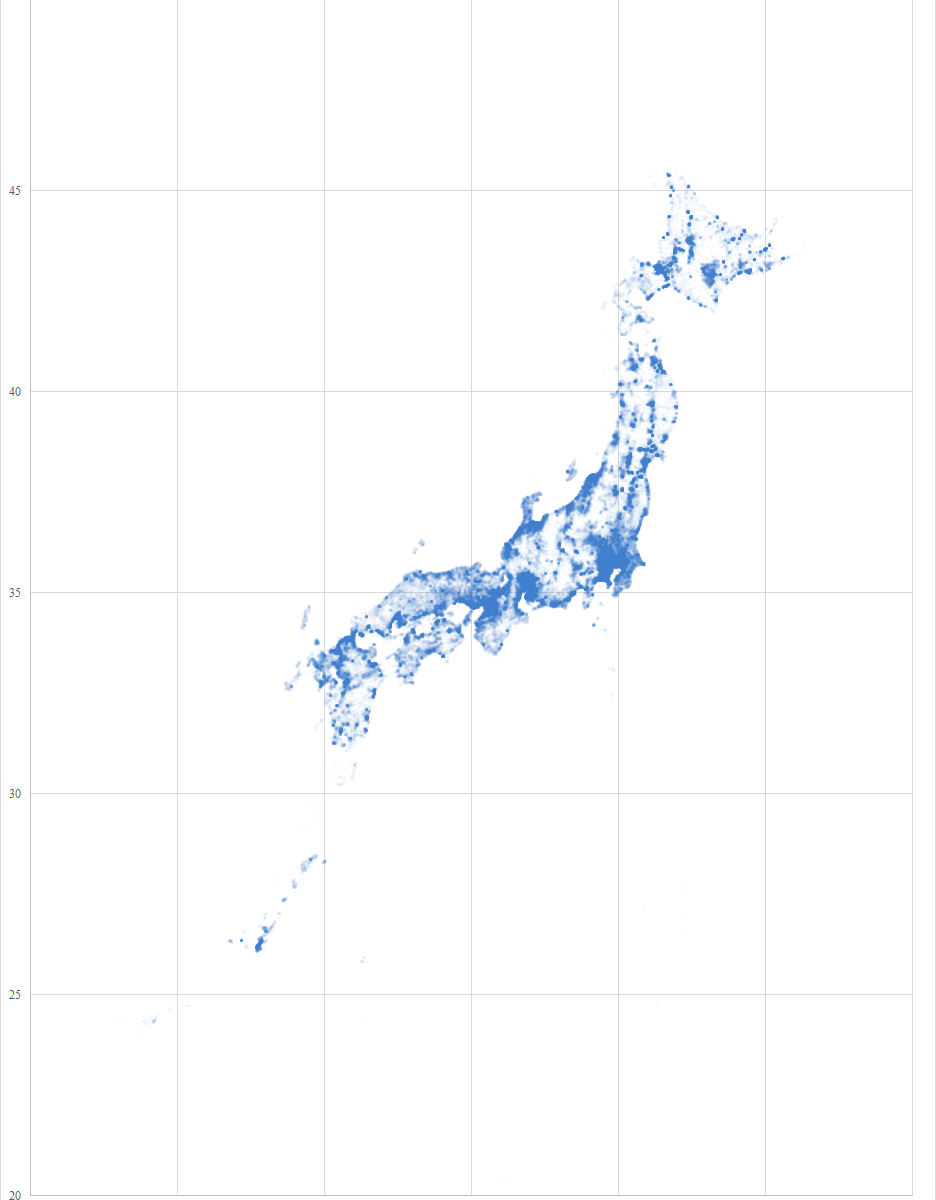
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
厚労省「地域ごとのまん延の状況に関する指標等」の PDF から Power BI Desktop でデータを抽出し EXCEL のグラフに表現する
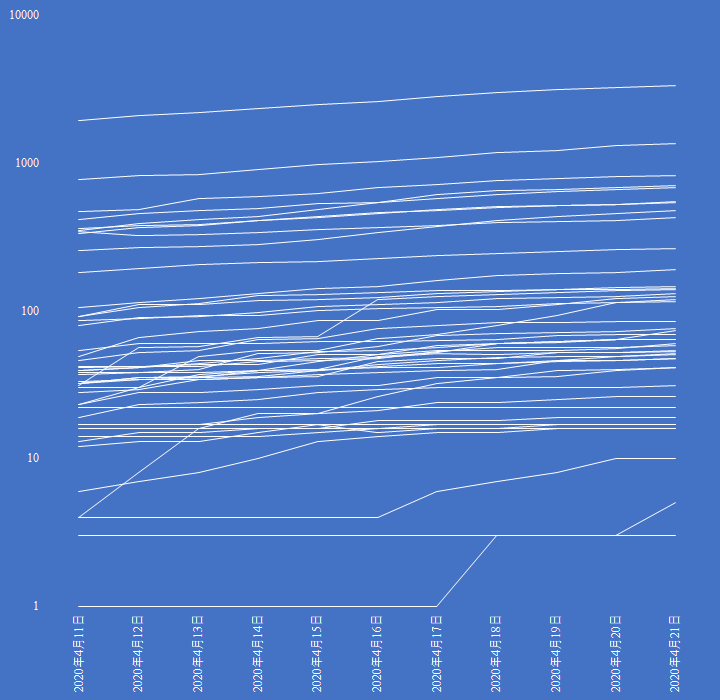
新型コロナウイルスのパンデミック宣言以降,Twitter でフォローしているアカウントに自然と相互協調の動きがみられる.
厚労省が「地域ごとのまん延の状況に関する指標等」の公表を開始。
— にゃんこそば (@ShinagawaJP) 2020年4月23日
都道府県ごとの①確定患者数、②リンクが不明な患者数、③相談件数、④PCR検査の実施数…と、必要な情報を一通り網羅しています。
が、ファイルはまさかのPDF形式。ExcelかCSVも提供してくれれば…https://t.co/Ox5rU6m1Xo
このツイートから始まった一連のやりとりで,厚労省の発表した PDF からテーブルを抽出するくだりに注目した.
失礼します。今、マクロソフト Power BI デスクトップを使用したところ無事PDFを読み込めました。また、列のピボット解除という機能を使うことで、クロス集計表を添付のような集計用フォーマットに加工できます。 pic.twitter.com/FEV0SBSito
— Akira Takao (@modernexcel7) 2020年4月23日
今回はここを画像つきで実施してみた.
“厚労省「地域ごとのまん延の状況に関する指標等」の PDF から Power BI Desktop でデータを抽出し EXCEL のグラフに表現する” の続きを読む