
国勢調査をもとに作成された境界データダウンロードサービスがある.市区町村よりも更に細かい,町字の粒度でのGISデータである.今回は関東地方のデータをダウンロードし,QGISで人口密度を可視化する.
境界データをダウンロード
総務省のオープンデータの一環である eStat には各種統計が蓄積されている.下図のようにトップページから「地図」「地図上にデータを表示(統計GIS)」をクリックする.

今回は GIS データを取得したいので,「境界データをダウンロード」をクリックする.
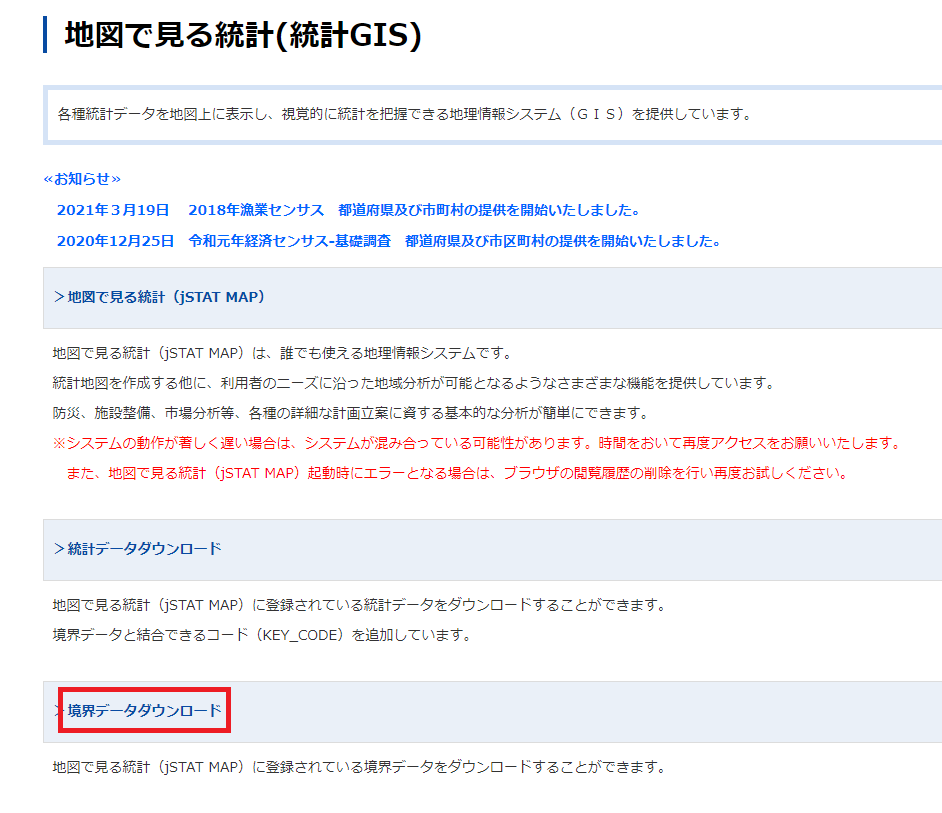
「小地域」をクリックする.
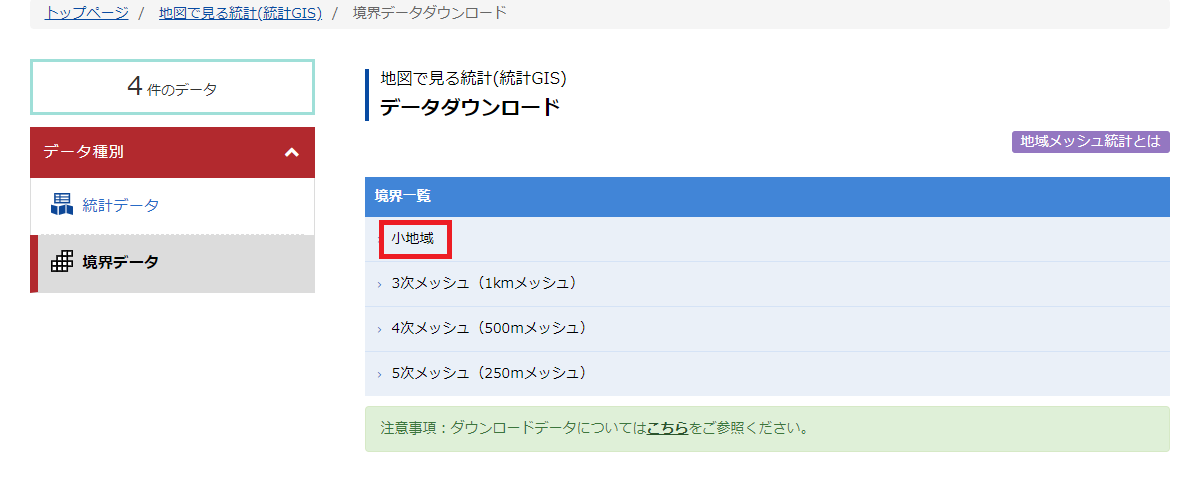
「国勢調査」をクリックする.他にも「事業所・企業統計調査」「経済センサスー基礎調査」「経済センサスー活動調査」「農林業センサス」があるが,今回は割愛する.
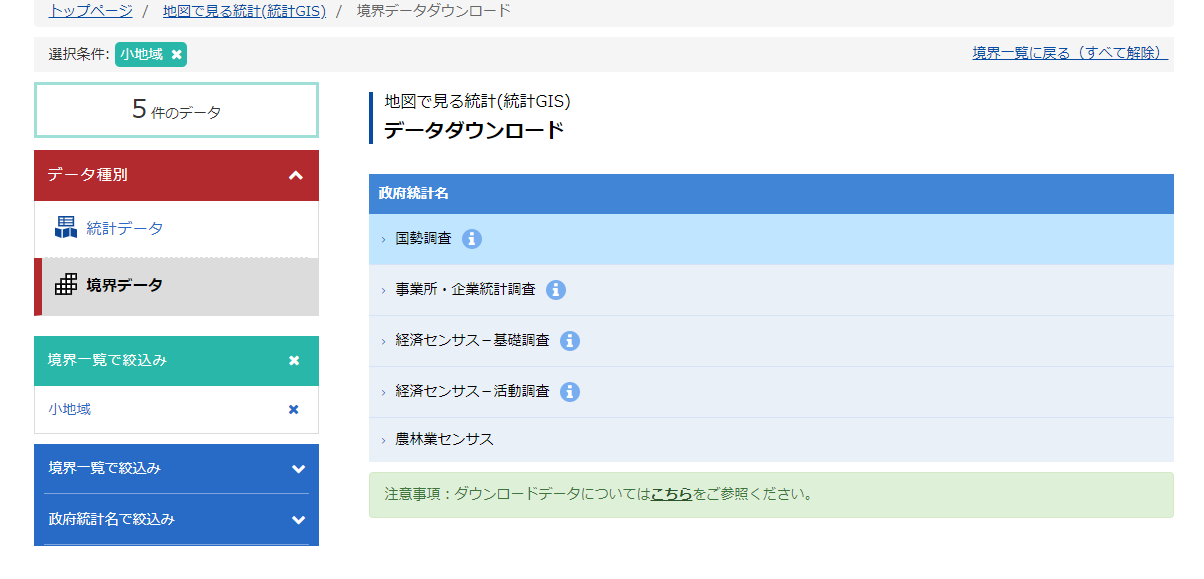
2000 年以降のデータがある.今回は最新の 2015 年を選択する.
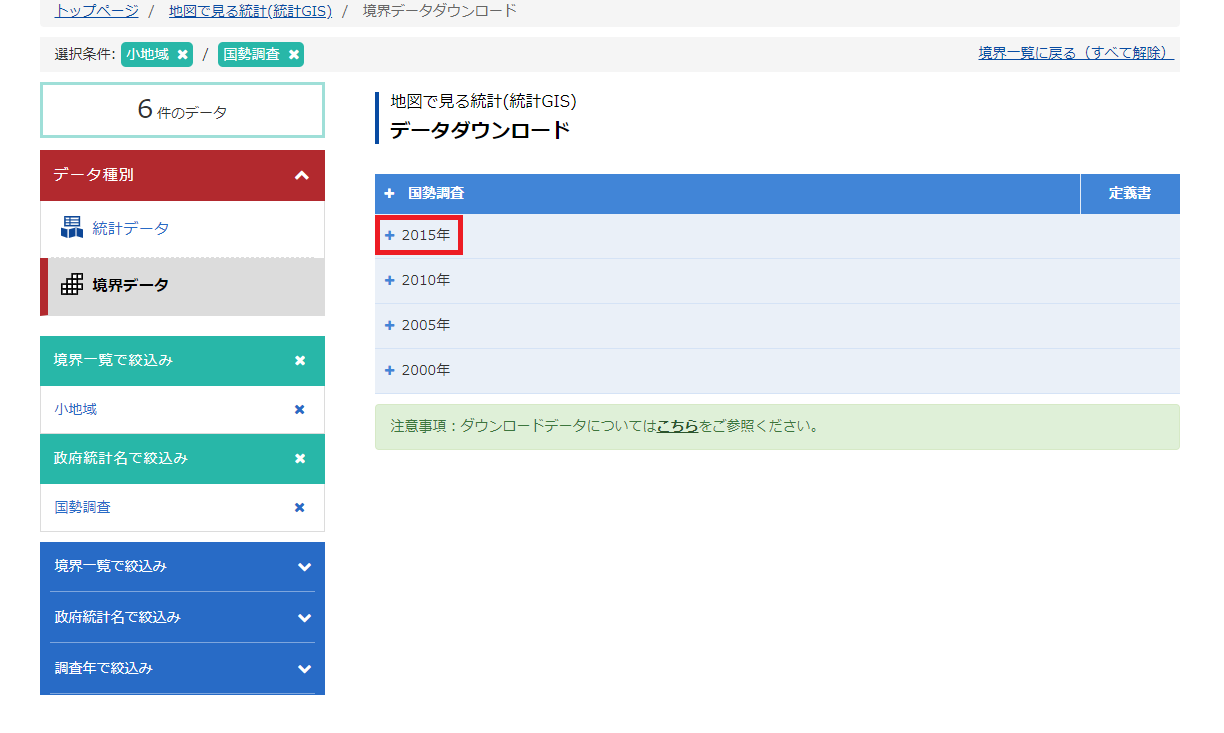
「小地域(町丁・字等別)」をクリックする.
座標参照系を選択する.ここでは「世界測地系緯度経度・Shapefile」を選択する.

都道府県の一覧が出てくる.下図のように必要な都道府県ごとにデータをダウンロードする必要がある.
下図は福島県の例である.最初に県全域のデータがあり,以下市区町村別のデータが列挙されている.このボタンをクリックするとデータを zip ファイルとしてダウンロードできる.
zipファイルを展開する.
都道府県別のレイヤをマージする
QGIS の「レイヤ」「ベクタレイヤの追加」
ダウンロードした zip ファイルをエクスプローラで展開したら,QGIS を起動する.「レイヤ」メニューの「ベクタレイヤの追加」を選ぶ.下図のようにダイアログが開くので,.shp ファイルを選択し「開く」をクリックする.
都道府県ごとに色分けされて表示される.
ベクタレイヤのマージ
このままでは操作がしづらいので,レイヤを一つにまとめてしまおう.「プロセシング」メニューの「ツールボックス」を選ぶ.
「プロセシングツールボックス」の「ベクタ一般」から「ベクタレイヤのマージ」をダブルクリックする.
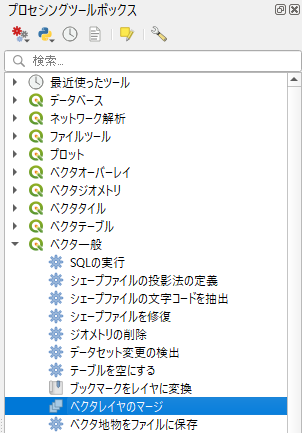
「ベクタレイヤのマージ」ダイアログボックスである.ここでは「入力レイヤ」と「変換先の座標参照系」を指定する.
まず入力レイヤである.下図ではすでに表示されているが,何も表示されていない場合は「ファイルを追加…」ボタンをクリックしてダイアログから追加する.
「すべて選択する」ボタンをクリックするとチェックが入る.「OK」をクリックして入力レイヤの指定を終える.
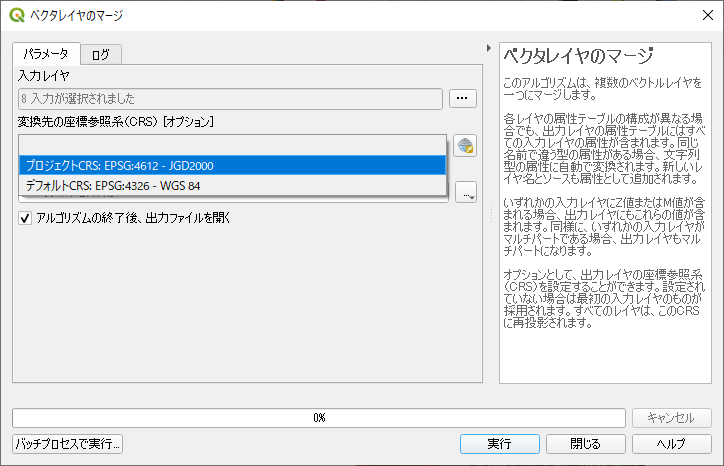
変換先の座標参照系では「プロジェクトCRS: EPSG:4612 – JGD2000」を指定する.
「実行」をクリックすると下図のようにレイヤがマージされ,「出力レイヤ」という名前で表示される.
注意が必要なのだが,この「出力レイヤ」はメモリ上にのみ存在するデータなので,アプリを終了すると消えてしまう.次に行うように「エクスポート」しないと保存されない.
出力レイヤをファイルとして保存
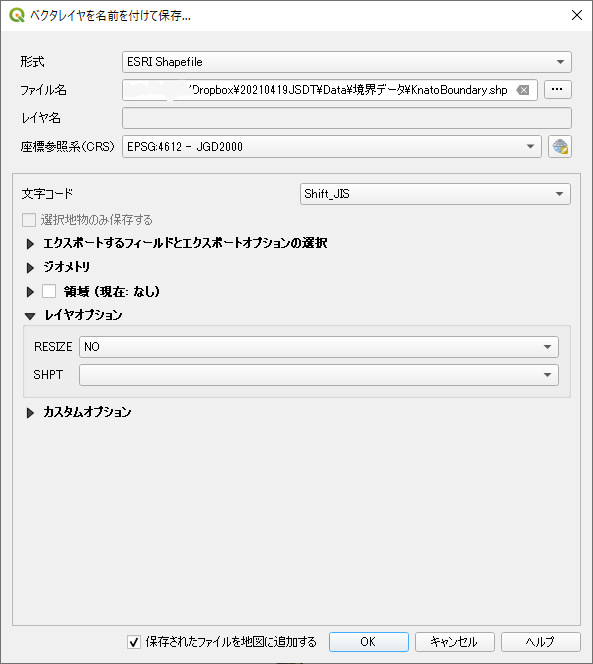
「出力レイヤ」を右クリックして「エクスポート」「新しいファイル名で地物を保存…」と進む.

「ベクタレイヤを名前を付けて保存…」ダイアログである.「ファイル名」に直接タイプしてもエラーが発生して弾かれる.右側の「…」ボタンをクリックしてフルパスで指定する必要がある.この辺り,もう少しインターフェースを工夫してもらいたい.
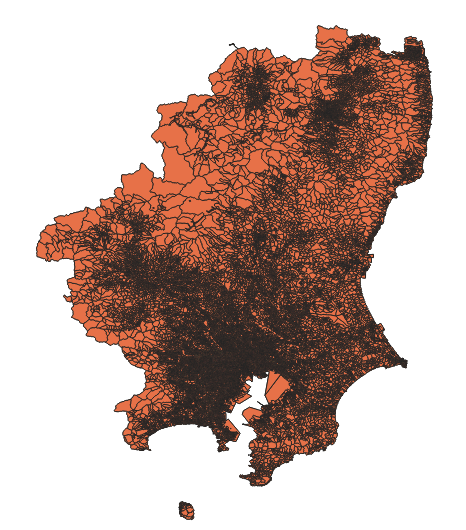
保存されたレイヤが別の色で表示されている.
属性テーブルから人口密度を導出する
ここまでの操作はジオメトリの準備だった.ここからは属性テーブル,つまり .dbf ファイルを操作することになる.境界データの属性テーブルには国勢調査の基本的なデータである人口や面積が付加されており,両者から人口密度を計算できる.面積の単位は平方メートルで与えられているため,平方kmに換算する必要がある.
属性テーブルを開く
マージしたレイヤを右クリックして「属性テーブルを開く」を選ぶ.
メニューバー左端の「編集モード切替」ボタンをクリックする.
フィールド計算機を開く
メニューバー右側に「フィールド計算機を開く」ボタンがあるのでクリックする.

「フィールド計算機」の初期状態.「新しいフィールドを作る」にチェックが入っている.データベースに新しい列を追加するという意味である.
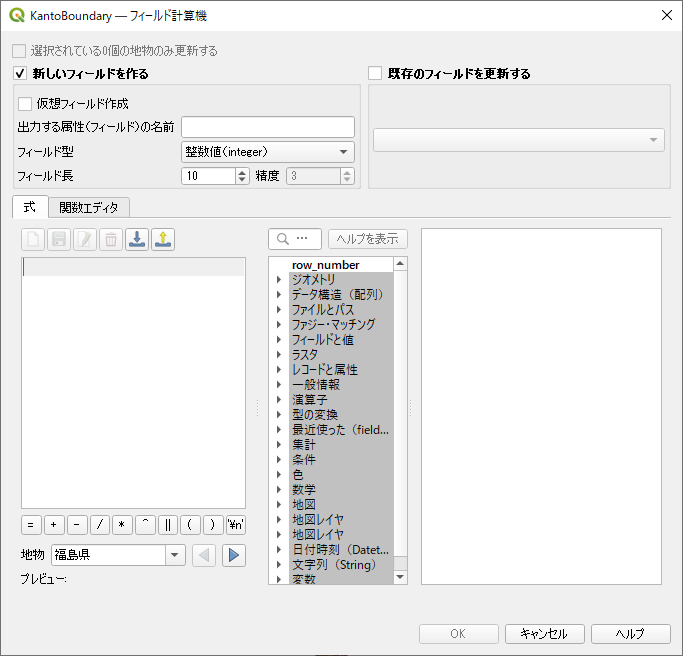
面積の単位を換算
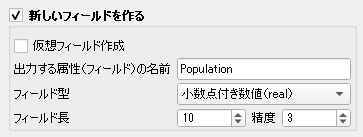
まず,面積を換算する必要がある.具体的には平方メートルを 100 万で割って平方kmとする.下図のようにフィールドの名前,型,長さを指定する.
「フィールドと値」を展開する.
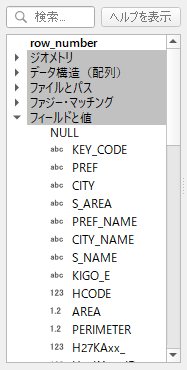
下にスクロールしていくと面積を示す “AREA” が出てくるのでダブルクリックして「式」に追加する.
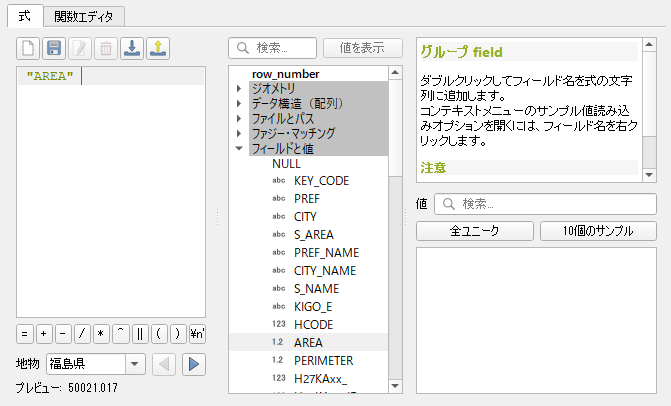
スラッシュを入力し,1000000 とタイプする.OK をクリックすると計算が実行される.
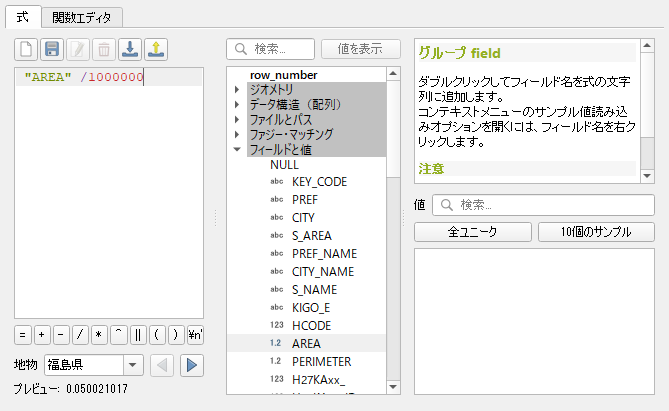
人口密度を算出
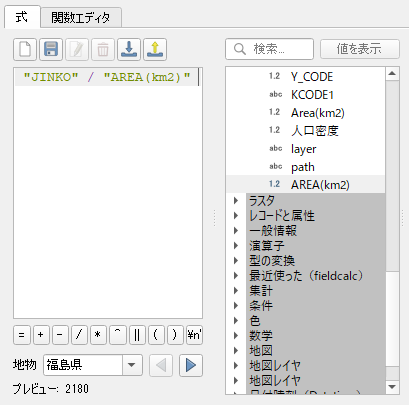
ついで人口密度を算出する.ESRI の Shapefile にはフィールド名が半角 10 文字までという制約がある.全角も弾かれやすいため半角がベターである.
人口を面積で除算する.OK をクリックすると計算が実行される.
「編集モード切替」ボタンをクリックすると保存するよう促される.
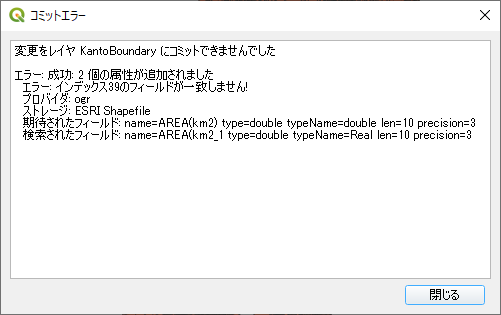
コミットエラーが出るが,実用上問題はなさそうである.
人口密度に応じて小地域を塗り分ける
人口密度が計算できたところで,今度は小地域をそれに応じて塗り分ける作業となる.関東全域を対象とするため,どうしても東京に引きずられやすい.各県ごとに作成する場合にはもう少し細かい変化を追えるだろう.5 段階というのは人間の認知上,絶妙な設定だと思われる.10 段階では細かすぎて変化を識別しづらいだろう.
レイヤのプロパティからシンボロジを編集する
レイヤを右クリックして「プロパティ…」を選ぶ.
「シンボロジ」を選ぶと下図のように「単一定義」が初期値として表示されている.これを変更していく.
クリックすると「シンボルなし」「単一定義」「カテゴリ値による定義」「連続値による定義」「ルールによる定義」「結合済み地物」「反転ポリゴン」「2.5D」がポップアップする.「連続値による定義」を選ぶ.
「値」は空白で未定義であり,これから定義する.「カラーランプ」は赤が選ばれており,好みに応じて変更する.
先程定義した人口密度である Population を選択する.
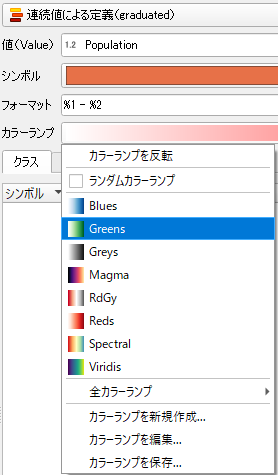
「カラーランプ」には Blues, Greens, Magma, RdGy, Reds, Spectral, Viridis があり,ここでは Greens を選ぶ.
自然分類で塗り分けてみる
「モード」の初期値は「丸め間隔」である.

まず「自然分類」を選んでみる.
「クラス」に境界値が表示される.
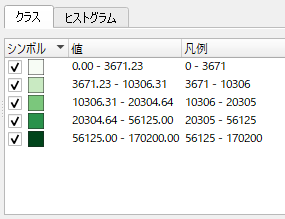
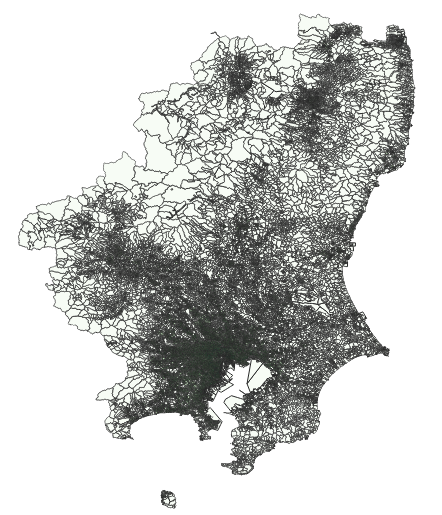
実行結果は中間階調に乏しく,ビジュアル的にはあまり良いとは言えない.
等量分類で塗り分けてみる
ここからは試行錯誤である.「等量分類」に変更してみる.
クラスの境界値がより小さい方にシフトしたように見える.
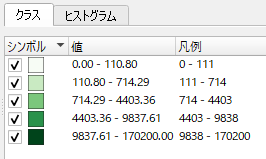
結果として中間階調が鮮明となった.人の目にはこれが自然に感じられるが,分布を「ヒストグラム」で確認しておいたほうが良いだろう.すでにこの時点で「歪んで」いる.
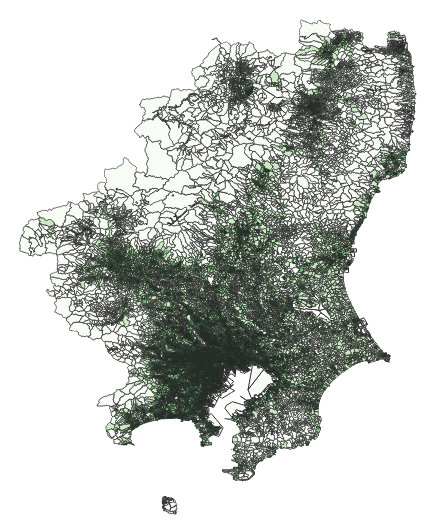
そういえば,エラーが出ない
QGISで国土数値情報のシェープファイルを修正するで述べたように,今回扱った eStat の境界データは修正する必要がなかった.後日,全国のデータをマージしてみたが,全く修正の必要がなかった.さすがに頻用されるデータだけはある.本来ならすべての国の公開するデータはここまでのレベルに仕上げておいてほしいものである.
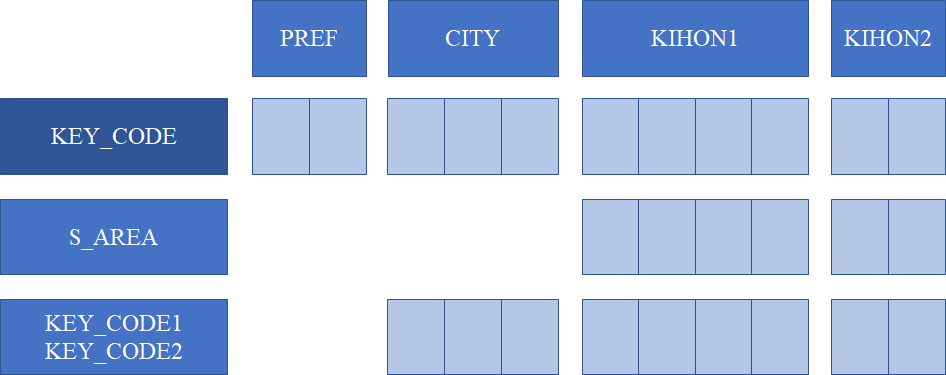
属性テーブルの主キーとは
レイヤのプロパティをスクロールしていくと,下図のように属性が見えてくる.
| Field | Type | Length |
|---|---|---|
| KEY_CODE | String | 11 |
| PREF | String | 2 |
| CITY | String | 3 |
| S_AREA | String | 6 |
| PREF_NAME | String | 12 |
| CITY_NAME | String | 14 |
| S_NAME | String | 96 |
| KIGO_E | String | 3 |
| HCODE | String | 4 |
| AREA | Real | 18,3 |
| PERIMETER | Real | 18,3 |
| H27KAxx_ | Integer | 6 |
| H27KAxx_ID | Integer | 6 |
| KEN | String | 2 |
| KEN_NAME | String | 12 |
| SITYO_NAME | String | 22 |
| GST_NAME | String | 14 |
| CSS_NAME | String | 14 |
| KIHON1 | String | 4 |
| DUMMY1 | String | 1 |
| KIHON2 | String | 2 |
| KEYCODE1 | String | 9 |
| KEYCODE2 | String | 9 |
| AREA_MAX_F | String | 1 |
| KIGO_D | String | 2 |
| N_KEN | String | 2 |
| N_CITY | String | 3 |
| KIGO_I | String | 1 |
| MOJI | String | 96 |
| KBSUM | Integer | 4 |
| JINKO | Integer64 | 10 |
| SETAI | Integer64 | 10 |
| X_CODE | Real | 18,5 |
| Y_CODE | Real | 18,5 |
| KCODE1 | String | 7 |
| layer | String | 254 |
| path | String | 254 |
| Areakm2 | Real | 10,3 |
| Population | Real | 10,3 |
eStat には他にも csv ファイルで提供される統計データがある.しかし QGIS には制約がある.つまり,テーブル結合のフィールドは一つしか指定できないため,それらと境界データを結合するには主キーを知っておく必要がある.KEY_CODE は 11 桁と定義されているが,実際の属性テーブルを見てみると 9 桁や 7 桁のデータがあって難渋することになる.これらはおそらく集計行であると思われるが,データベースの第一正規形を満たしておらず,総務省には善処をお願いしたい.
まとめ
eStat の境界データをダウンロードし,QGIS で人口密度を小地域ごとに塗り分けた.全国の都道府県のデータをマージする際,修正の必要はなかった.
しかし,データベース内に本来は不要である集計行が紛れ込んでおり,総務省には対応をお願いしたい.
他の統計データとの結合は今後の課題である.