既知の情報だったら申し訳ないが,個人的に印象的だったので備忘録として公開する.これまではオブジェクトブラウザーからコピペしていたのだが,公式サイトから Power Query でテーブルをまるごとインポートできるようだ.
Microsoft 公式サイトから列挙体のテーブルをインポートする

Co-evolution of human and technology
既知の情報だったら申し訳ないが,個人的に印象的だったので備忘録として公開する.これまではオブジェクトブラウザーからコピペしていたのだが,公式サイトから Power Query でテーブルをまるごとインポートできるようだ.
Power Query で,あるフォルダ内の同一構造のファイルを一括してインポートする機会は多い.M 言語は未開拓であるが,その一端に触れてみた.
EXCEL ブックであれ csv ファイルであれ,構造化されたデータという観点から見れば,ファイル形式などどうでも良い話である.この抽象化が理解できれば,Power Query への理解が一定程度進むのではないかと思う.
この記事はEXCEL VBA でフォルダ内のブックを開きデータを読み込むと対応する.
多くの空間アプリケーションがカスタム定義の空間機能を組み合わせている.例えば顧客セットの局在と,広く受け入れられた表現の空間データ,地球上の汎用性のある特徴,例えば国や州の境界線,世界の主要都市の局在および主要な道路や鉄道の経路などである.この情報は自分自身で作成するよりも,多くの代替可能な資源が存在しており,そこから普通に使うための空間データを取得して空間アプリケーションに搭載できる.
本章では,そこから一般公開された空間情報を取得できる資源,そこでそのデータが普通に提供されるフォーマットおよびその情報を SQL Server にインポートするのに使える技術を紹介しよう.
“第 6 章 空間データをインポートする (Beginning Spatial with SQL Server 2008)” の続きを読む
空間データをデータベースで扱うにあたりどうしても避けて通れないのが,空間データがデータベース内でどう扱われているかを知ることである.
EXCEL のオブジェクトも本質を知っているわけではないが,プロパティやメソッドを知ることで「どう動いているか」は見当がつく.SQL Server でも同じことである.
“第 1 章 空間情報を定義する (Beginning Spatial with SQL Server 2008)” の続きを読む
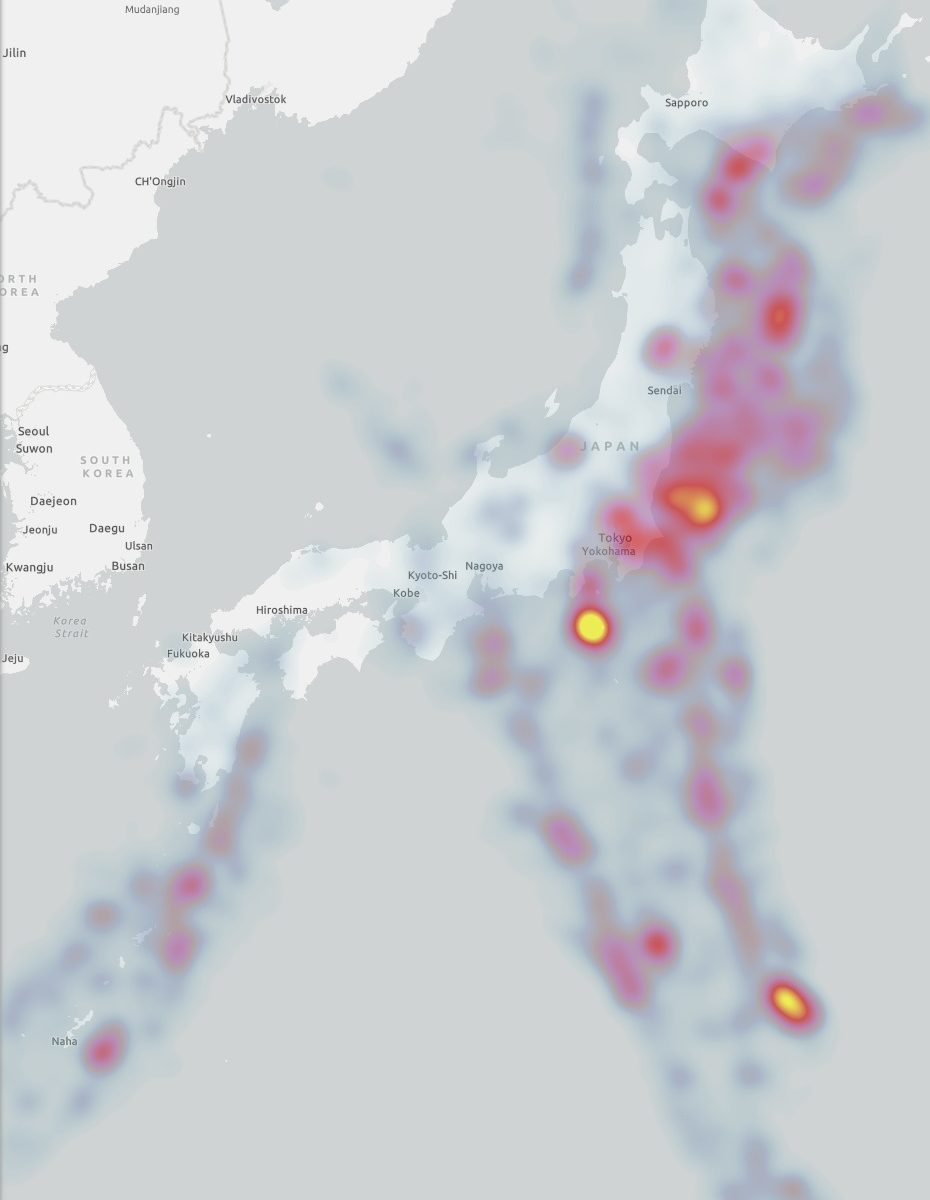
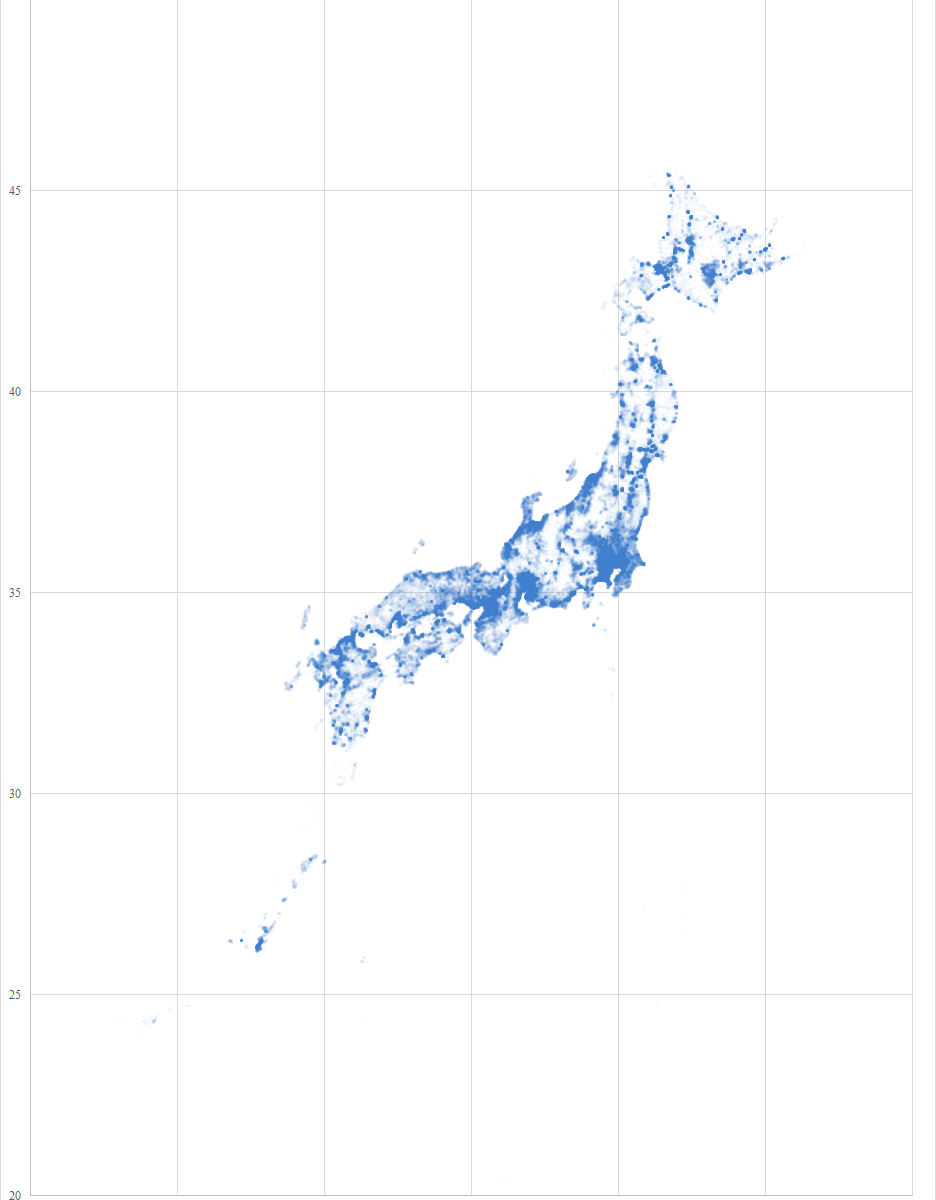
国土交通省のサービスの一つに位置参照情報ダウンロードサービスがある.何気なくファイルをダウンロードして,思いがけない発見があったため,記事を書くことにした.
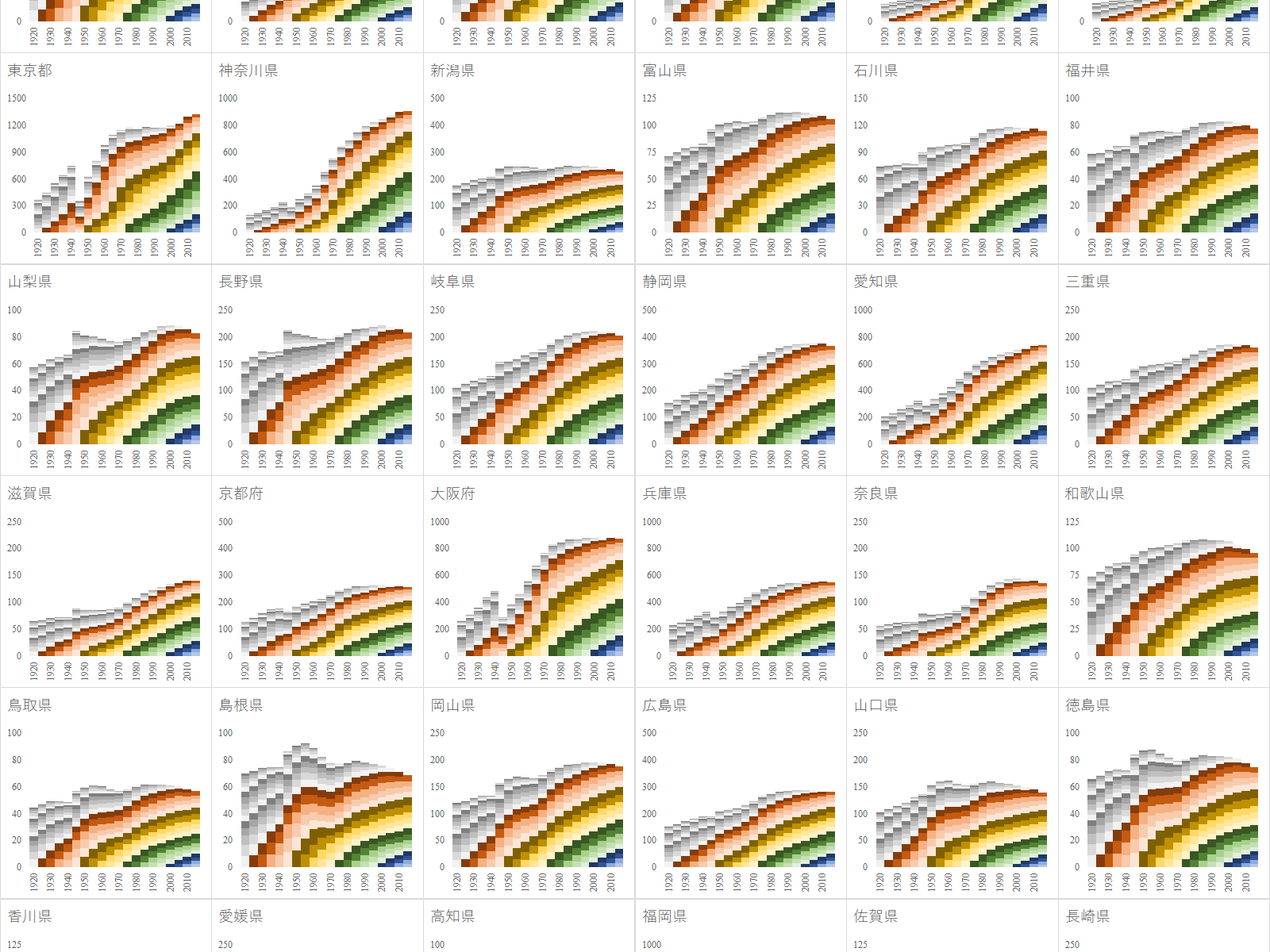
e-Stat を渉猟していると面白いファイルを見つけた.国勢調査は 1920 年から開始されており, 2020 年 3 月現在では最新の調査結果は 2015 年のものである.20 回分の人口データが一つのファイルにまとめられており,グラフ化するには格好のデータである.
年齢(5歳階級),男女別-都道府県(大正9年~平成27年)というファイルである.リンク先のページにはファイルが 3 つあるが,最後のものが最も粒度が細かいので,これをグラフ化する.
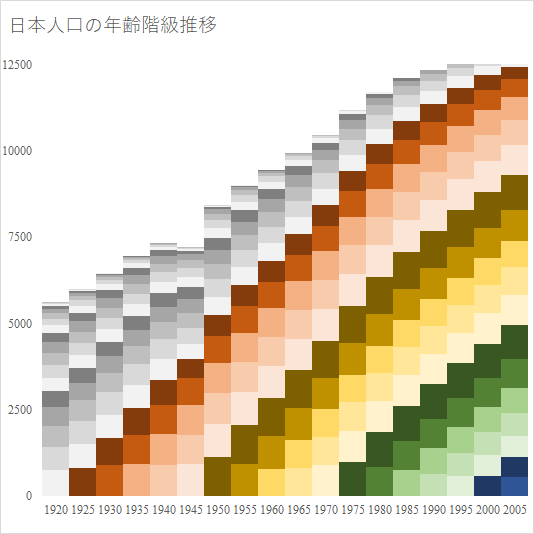
人口統計は最も重要な基幹統計の一つである.総務省の e-Stat は確かに有用であるが,かゆいところに手が届かない.例えば「市区町村ごと,年齢5歳階級ごとの人口構成の国勢調査ごとの推移を知りたい」という要求には全く無力である.
主として技術的な理由によるものと,統計調査の粒度の細かさによる.技術的な理由としては,データベースの画面表示セル数の上限を容易に超えてしまうデータ量になってしまうことである.しかし,根本的な理由は調査の粒度の細かさである.
2005 年以前と 2010 年以降とでは調査の精度が違う.今後は高精度なデータファイルが e-Stat に掲載されていくものと思われるが,2005 年以前に関しては都道府県より細かい粒度は存在しない.そこを求めると手作業になってしまい,現実的ではない.国立社会保障・人口問題研究所ならデータを持っているかもしれない.
2020 年は国勢調査の年にあたる.総務省にはできるだけ細かい粒度でのデータ掲載を望むものである.
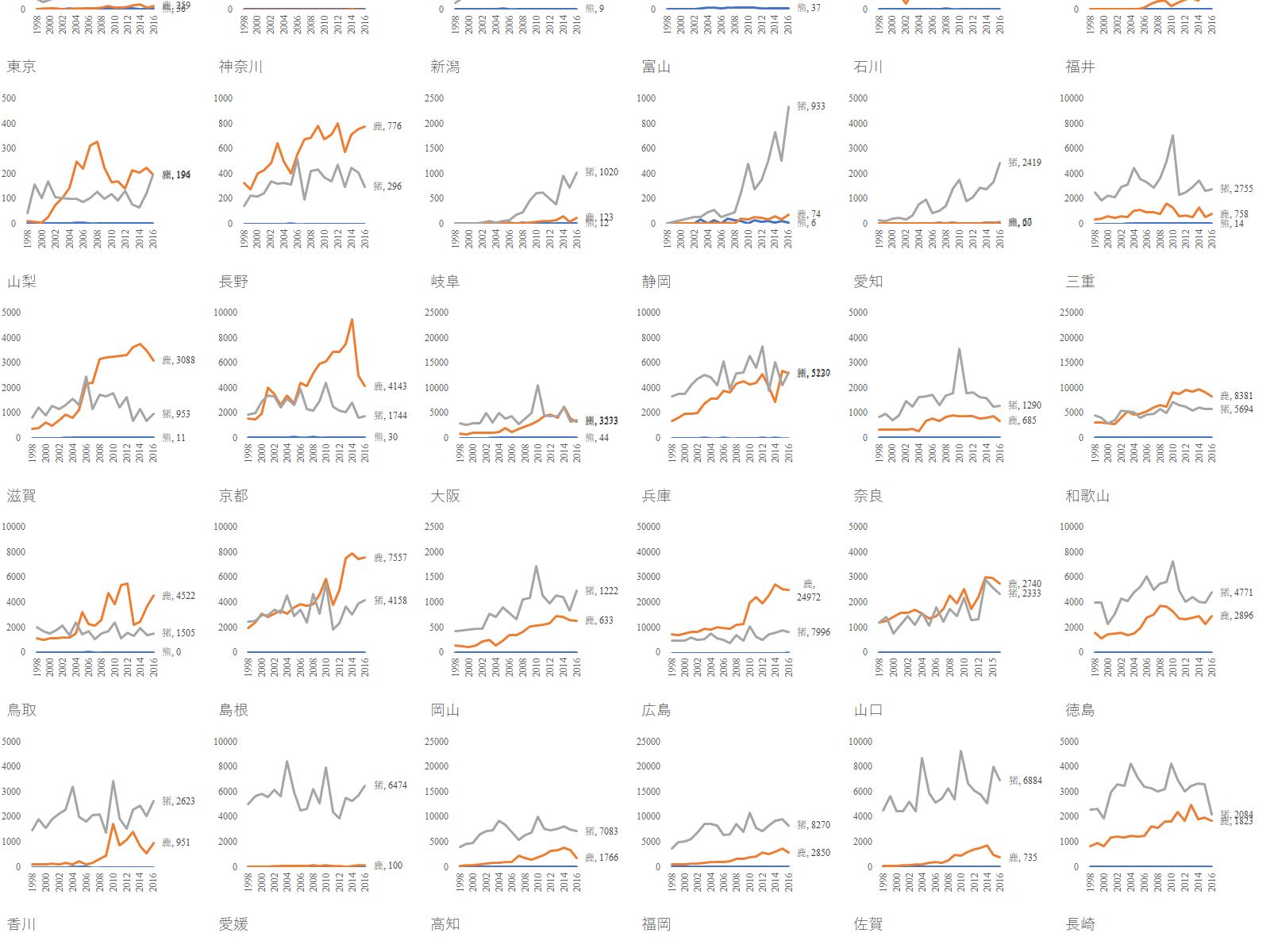
また面倒な統計を見つけてしまった.Power Query に食わせれば早いのかも知れないが,どうにも埒が明かないので手動でデータを整形することになった.頼むから第一正規形で公開してくれ…
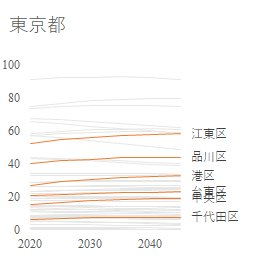
これまでは日本の都市人口の過去の推移を見てきた.総務省には日本の都市人口の推移予測がある.今回はこのデータをグラフにする.
データを可視化するにあたり,重要なのは引き算である.強調すべき系列のみを強調するために,VBA の知識が欠かせない.
グラフの系列にデータラベルを表示する方法にはいくつかある.
