
EXCEL のワークシートに格納できるレコード数は 1,048,576 行である.今回 e-Stat からダウンロードしたファイルをピボット解除したらその上限を超えてしまったのでその記事を書こう.
全国の食料品の物価を知りたい
情報は総務省 e-Stat にある
今回は小売物価統計調査 小売物価統計調査(動向編)のデータをダウンロードすることを目標とする.
データベースから csv ファイルをダウンロード
「ダウンロード」ボタンをクリックすると設定画面が出てくるオプション画面であるが,注意点がいくつかある.
- 「ダウンロード範囲」は「全データ」が最初からチェックされているが,変更しないこと
- 「ファイル形式」は「CSV形式」が最初からチェックされているが,変更しないこと
- 「ヘッダの出力」と「コードの出力」は「出力する」に最初からチェックが入っているが,変更しないこと
- 「注釈を表示する」は外したほうがよい
- 「桁区切りを使用しない」にチェックを入れること
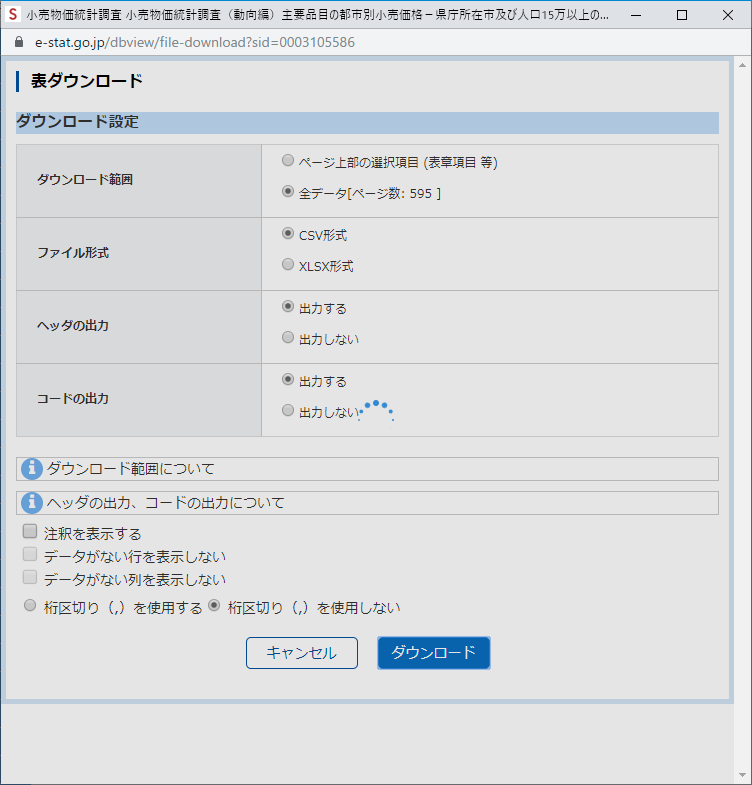
どうしても退治できない DataFormat.Error
ダウンロードしたファイルをそのまま EXCEL から Power Query で開こうとすると,下記のエラーが出て先に進まない.
どうやら原因は数値の入るべきセルに *** とか … とか – などの文字列が入り込んでいるためらしい.
データクレンジング
発想を切り替えてテキストエディタで前処理
Power Query にデータを食わせる前に下ごしらえが必要だ.かと言って EXCEL では余計な型の変換をしでかす可能性もある.ならばテキストエディタを使えばよいではないかと思いついて実行してみたら,上手く行った.
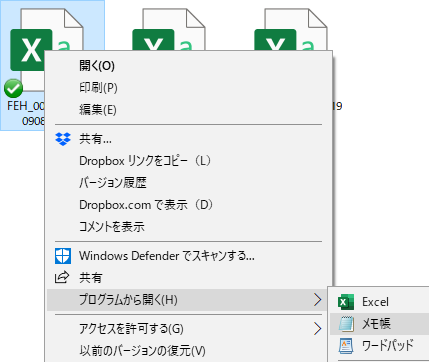
注釈行を削除
上から 10 行を選択したところである.注釈に確かにエラー文字列の注記がある…
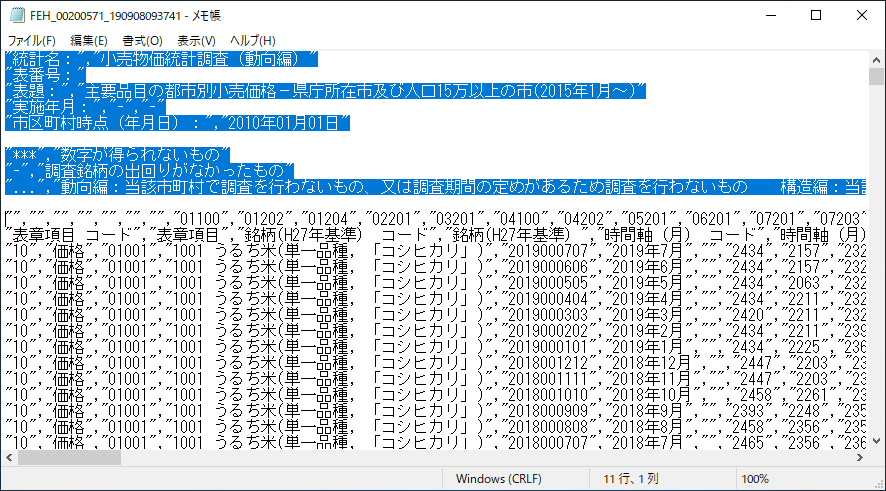
「編集」メニューから「削除」する.
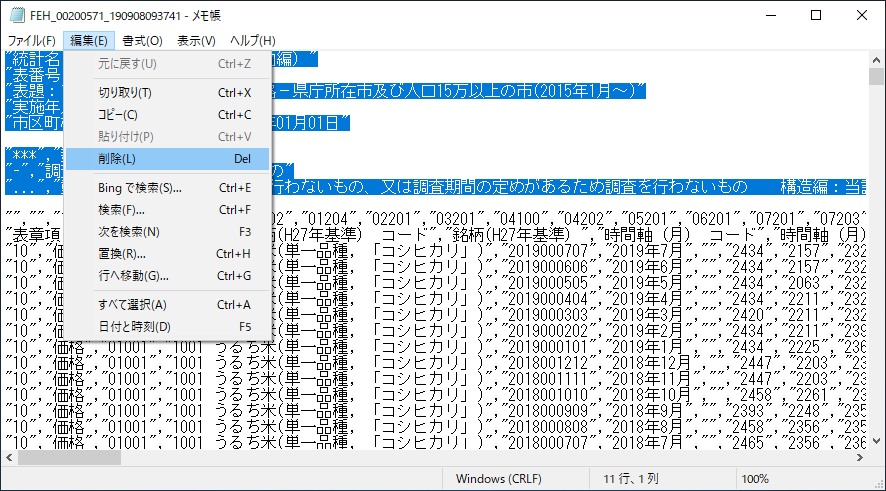
市区町村コードを削除するな!
5 桁の数字が 11 行目にある.これは市区町村コードであり,後で使うので削除してはいけない.
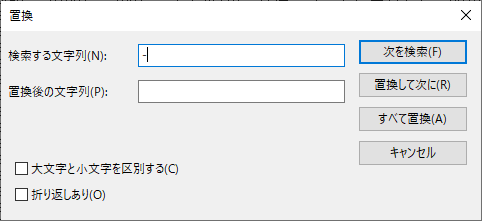
メモ帳の「置換」で文字列を一括削除
続いて「編集」メニューの「置換…」を選ぶ.
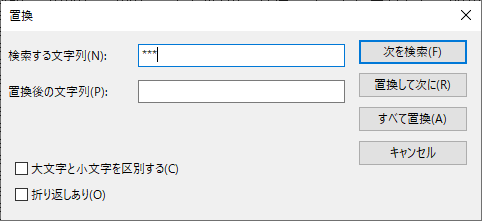
先程注釈にあった ***, …, – の文字列をここで一括削除しておく.
新しいメモ帳に全部のデータをコピペして保存
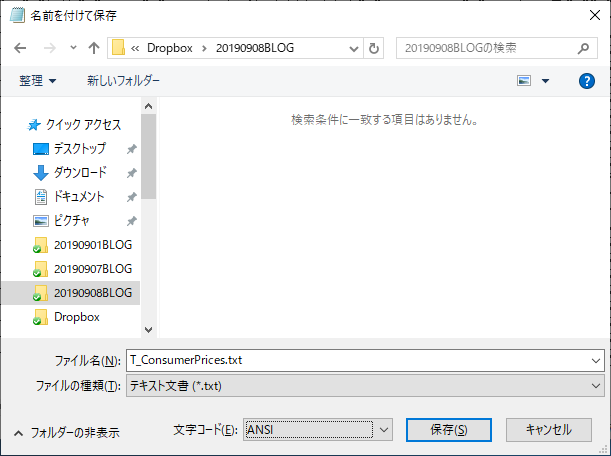
上記の作業を5つのファイル全てに施し,新しくメモ帳のファイルを作成して全データをコピペする.「名前を付けて保存」する.
EXCELでヘッダーを整形
テキストファイルウィザード
EXCEL を起動する.「空白のブック」ではなく,「開く」から「参照」をクリックする.
ファイルの種類を「テキストファイル」に切り替え,先程テキストエディタで保存したテキストファイルを指定する.
テキストファイルウィザードが起動する.
区切り文字はカンマ
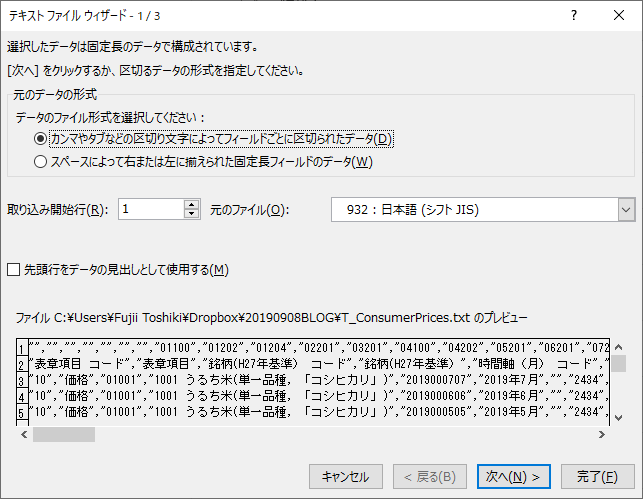
テキストファイルウィザードは 3 段階で設定してファイルを開く仕様になっている.
最初の設定は区切りの種類を指定する.
- 「カンマやタブなどの区切り文字によってフィールドごとに区切られたデータ」
- 「スペースによって右または左に揃えられた固定長フィールドのデータ」
の二択であるが,前者をチェックする.「次へ」をクリックする.
2 つ目はフィールドの区切り文字,つまりデリミタを選択する.「カンマ」にチェックを入れると,プレビューに縦線が入る.「次へ」をクリックする.
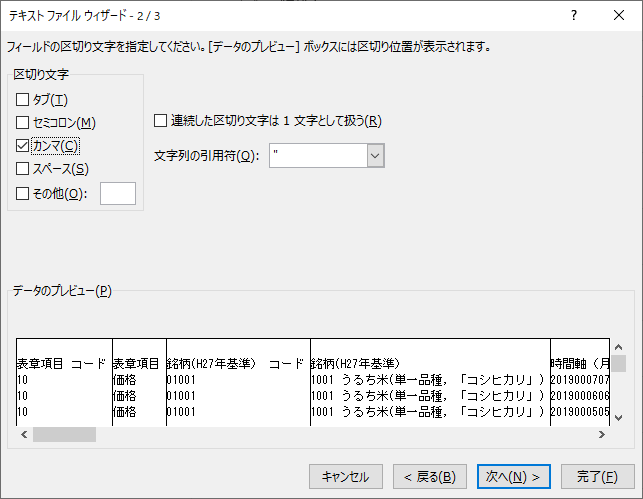
データ形式と削除する項目
3 番目は列のデータ形式,つまりデータ型を指定する.また,ここで取り込まずに削除する列を指定する.
削除する列は「表章項目コード」「表章項目」「時間軸(月)コード」「/地域」である.
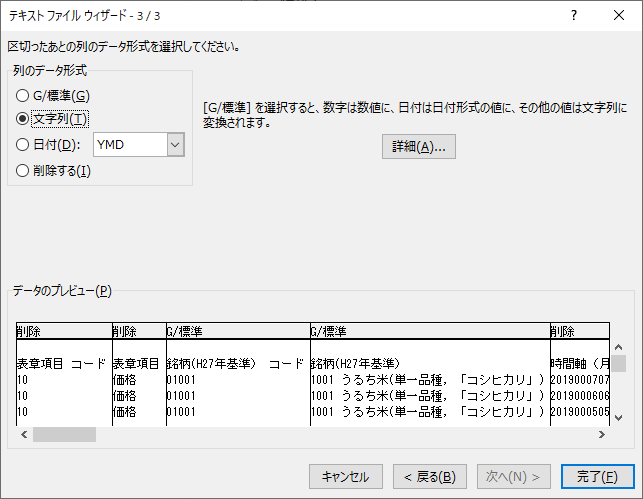
後でピボットの解除を行う列は「文字列」つまりテキスト型にする.理由は市区町村コードの先頭のゼロを消さないためである.「完了」をクリックする.
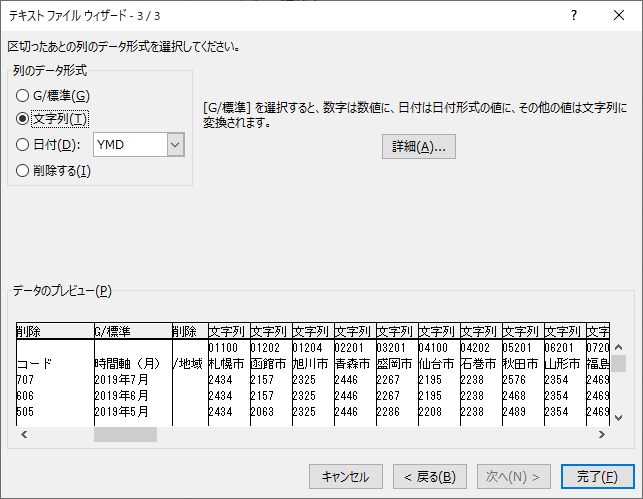
新しいヘッダー行を作る
1行挿入
下図はファイルを開いたところである.1 行目のD 列から右側に市区町村コードがある.この市区町村コードを直下の市区町村名と一旦結合したい.
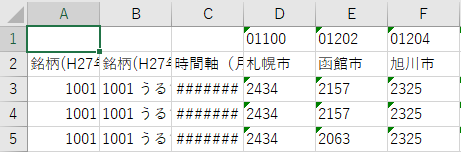
3 行目を選択して「挿入」する.
「セルの書式設定」を「標準」に直しておく
挿入した行をすべて選択して「書式設定」を開き,「表示形式」を「標準」に戻す.これは挿入した行の書式が文字列であり,そのままでは関数の再計算が行われないからである.
「市区町村コード」と「市区町村」を連結
図では逆になっているが,「市区町村コード」「市区町村」の順に & で結合する.後の工程の Power Query で列の分割を行う.
コピーして「値の貼り付け」
2 行目の A – C 列のタイトルはそのまま 3 行目にコピペする.
数式の参照関係を解消するために新しくできたヘッダー行を選択してコピーし,そのまま「値の貼り付け」を行う.
参照元の2行を削除
3 行目が新しいヘッダー行になったので元の 1-2 行目は不要となる.削除しよう.ここでファイルを保存して準備完了だ.
データの取り込み
Power Queryでデータクレンジングの続き
「データの取得」「ファイルから」「テキストまたはCSVから」
「空白のブック」で新しくファイルを作成する.「データの取得」タブから「ファイルから」「テキストまたはCSVから」と進む.
「データの変換」をクリックすると Power Query へ
「データの取り込み」でここまで編集してきたテキストファイルを指定してインポートする.
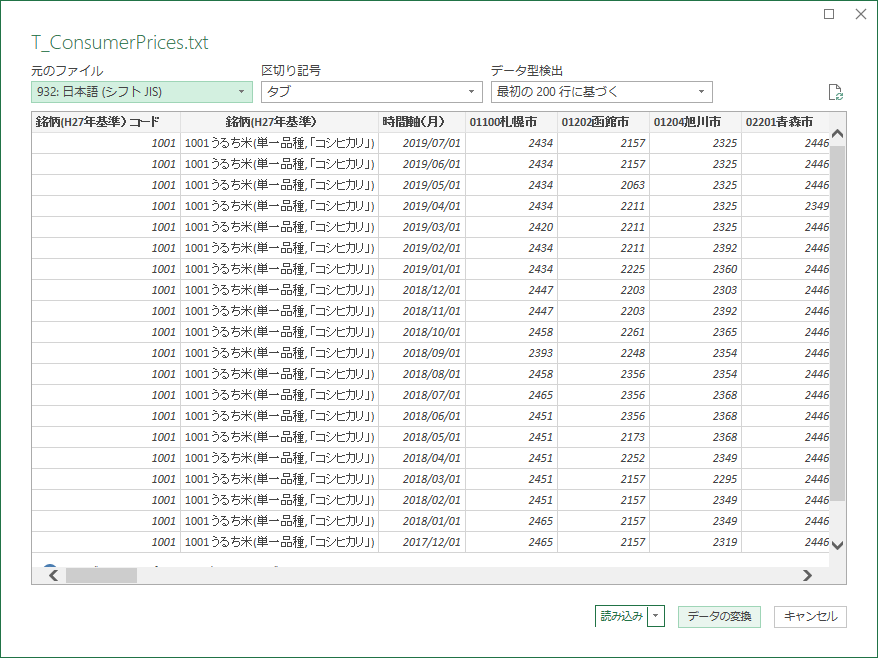
「データの変換」をクリックして Power Query エディターへ移行する.
これが Power Query エディターの初期画面である.
選択した列をピボット解除 (Table.Unpivot)
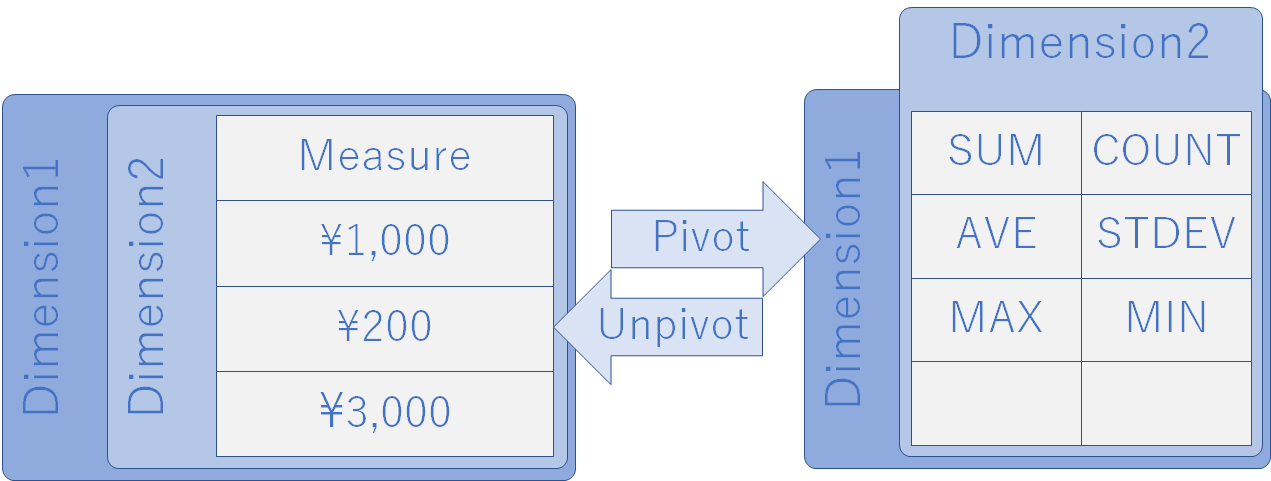
下図をよく見てほしい.4列目より右側の列はすべて「市区町村コード」と「市区町村」を結合したものと,「価格」との繰り返し構造になっている.ここをピボット解除していく.
この繰り返し構造をほどいていくのがピボット解除である.言葉で説明してもよく分からない人が多いだろう.ここでは集約とは逆のプロセスを行っている.ピボットの逆だからピボット解除なのである.
下の模式図は第一正規形(左)がピボットされてピボットテーブル(右)になる矢印と,逆向きの矢印を描いてある.
ディメンションが 2 つなら二次元の平面上に描けるが,3 つの場合もありうる.その場合はピボットテーブルは三次元のキューブになる.四次元以上の多次元キューブも当然ありうる.
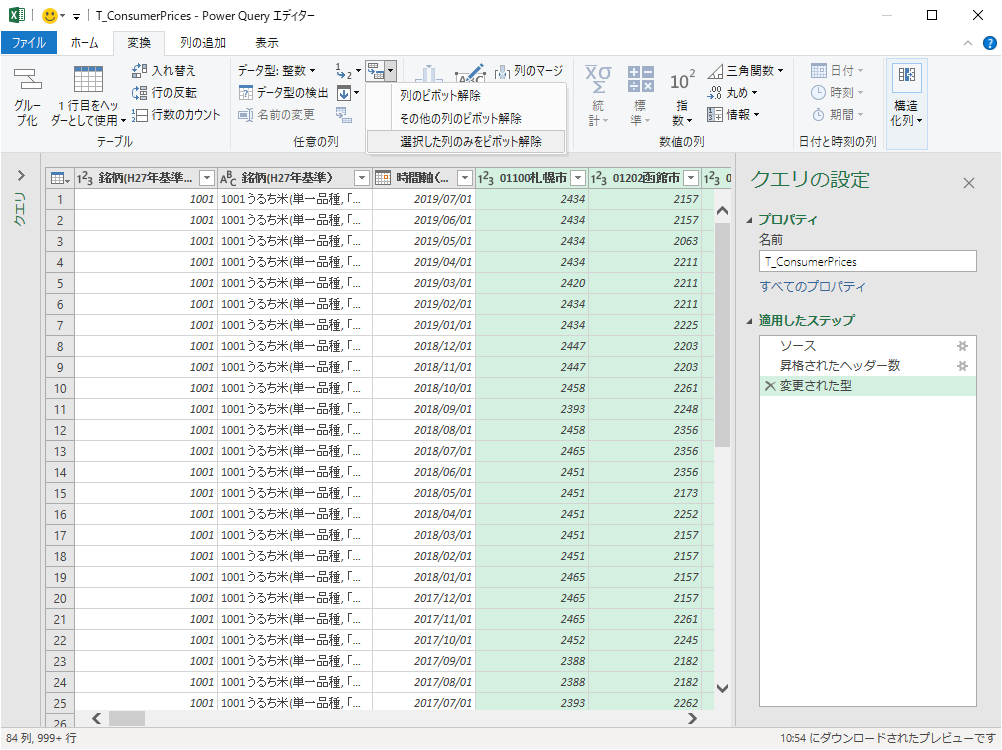
「01100札幌市」の列をまず選択し,シフトキーを押しながら右矢印キーを押しっぱなしにすることで対象の列をすべて選択する.その状態で「選択した列のみをピボット解除」する.
ピボット解除された状態.この時点でデータ数は当初の 32,000 件あまりから 180 万件あまりへと大幅に増える.
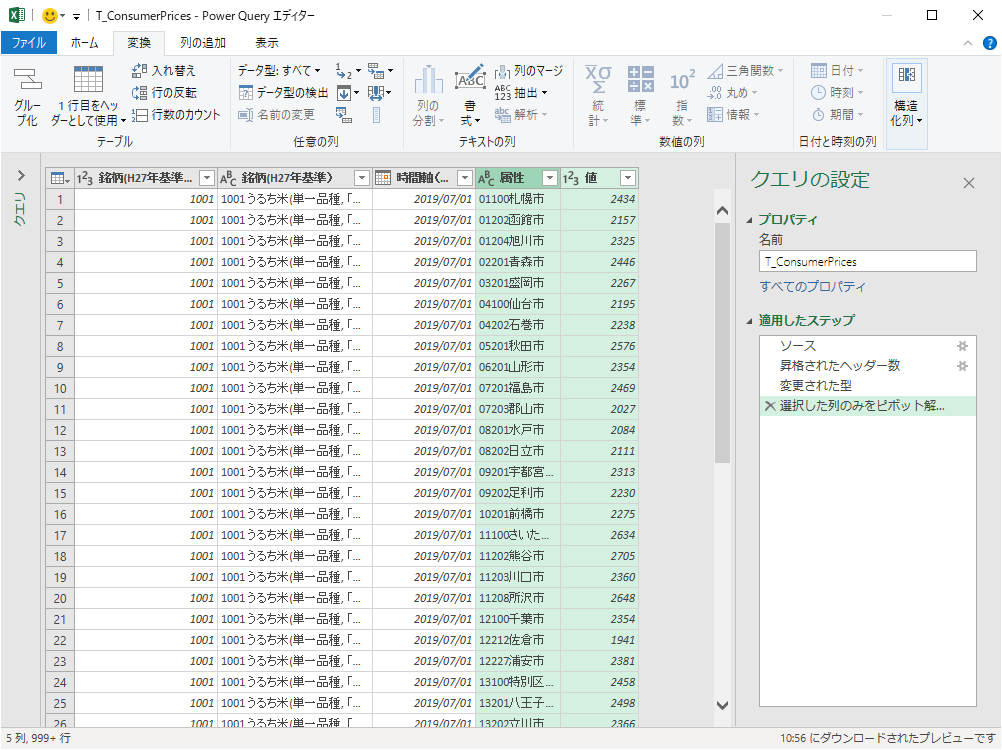
「列の分割」とは配列型を原子値に戻すこと (Table.SplitColumn)
「属性」ととりあえず列名のついた列は,元々「市区町村コード」と「市区町村」を結合したものであった.これを分割する作業をここで行う.これはリレーショナルデータベースにおいて配列型を原子値に戻すという,非常に重要な作業である.
「市区町村コード」「市区町村」の列を選択して「列の分割」「文字数による分割」と進む.
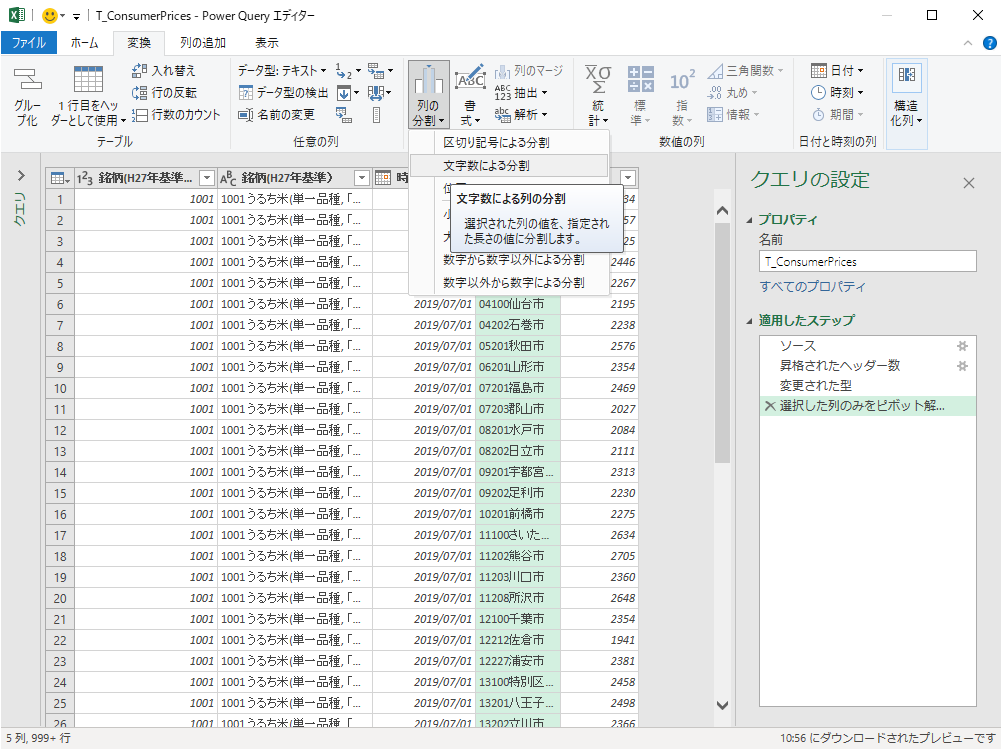
「文字数による列の分割」で文字数を 5 にする.市区町村コードを先にしておいたのがここで効いている.「分割」は「繰り返し」となっているが,正解は「できるだけ左側で 1 回」である.

その結果,第一正規形が完成した.後は列名の修正だけだ.
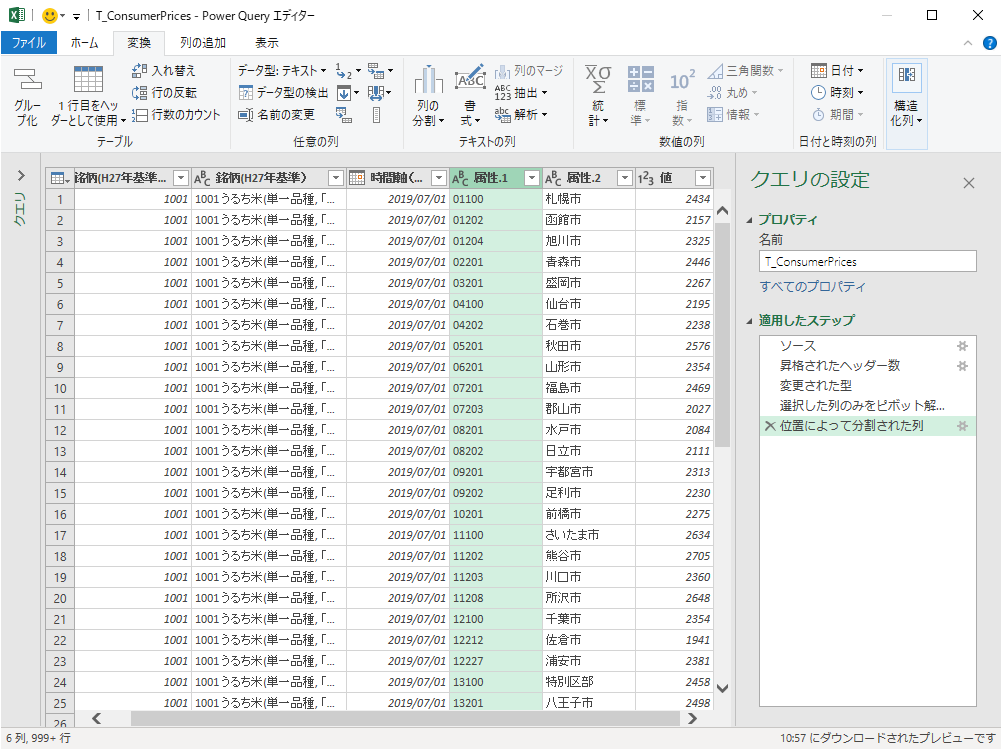
列名を右クリックして「名前の変更…」(Table.RenameColumns)
列名を右クリックして「名前の変更…」を選ぶ.
列名はそれぞれ「銘柄コード」「銘柄」「年月」「市区町村コード」「市区町村」「価格」となる.
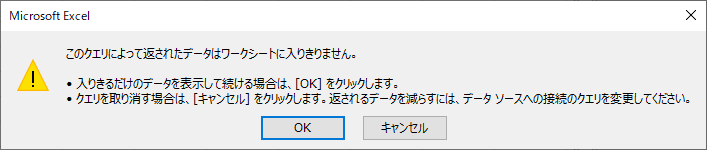
「閉じて読み込む」が,失敗する
「閉じて読み込む」.
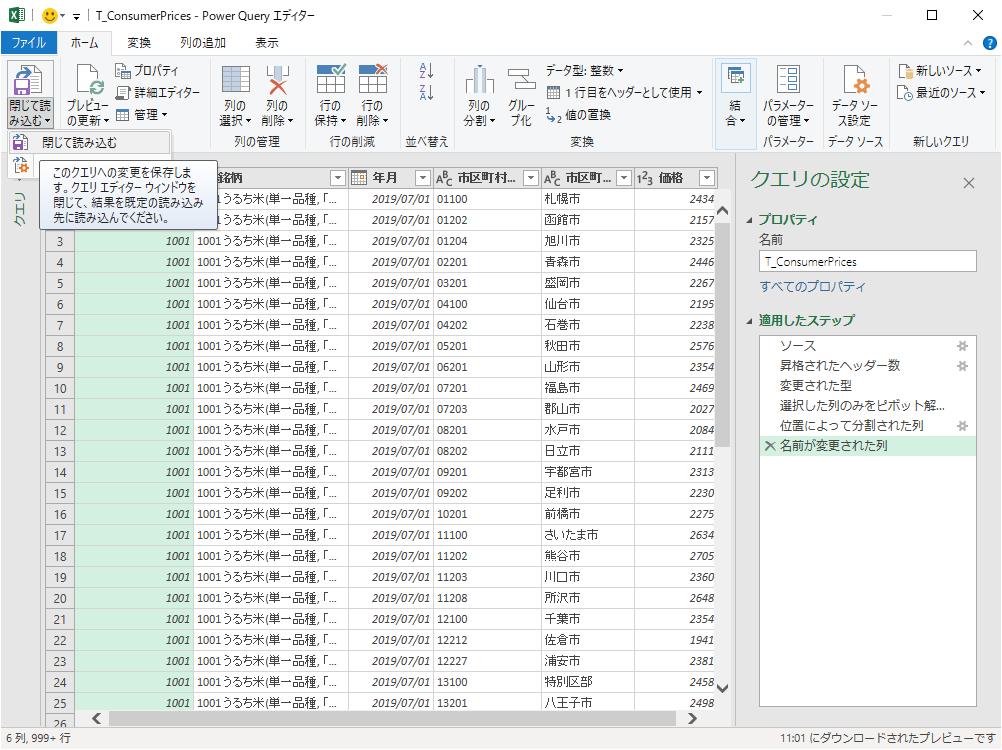
しかし,データ件数が多すぎてオーバーフローする.「キャンセル」をクリックして接続クエリを変更することにしよう.
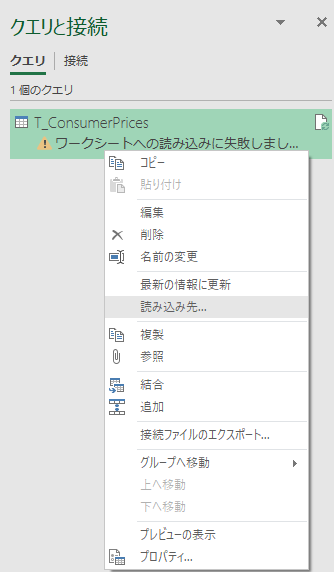
クエリと接続
「読み込み先…」
「クエリと接続」パネルに今の接続クエリを記述した箇所が表示されているので,右クリックして「読み込み先…」を選択する.
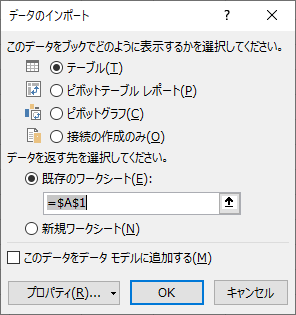
「接続の作成のみ」と「このデータをデータモデルに追加する」
「データのインポート」は初期状態で下図のようになっている.
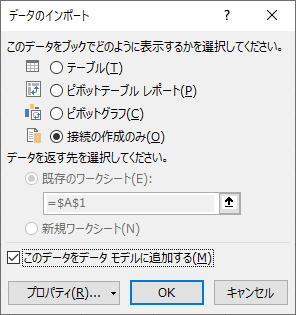
「テーブル」に入ったチェックを「接続の作成のみ」に変更し,「このデータをデータモデルに追加する」のチェックをオンにする.
読み込みに成功
OK をクリックすると接続に成功し,180 万件あまりのデータが読み込まれる.
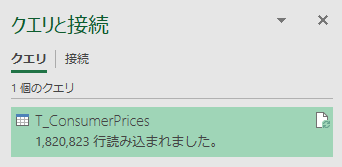
ファイルのプロパティを見てみると確かに大きなファイルサイズとなっている.
DAX
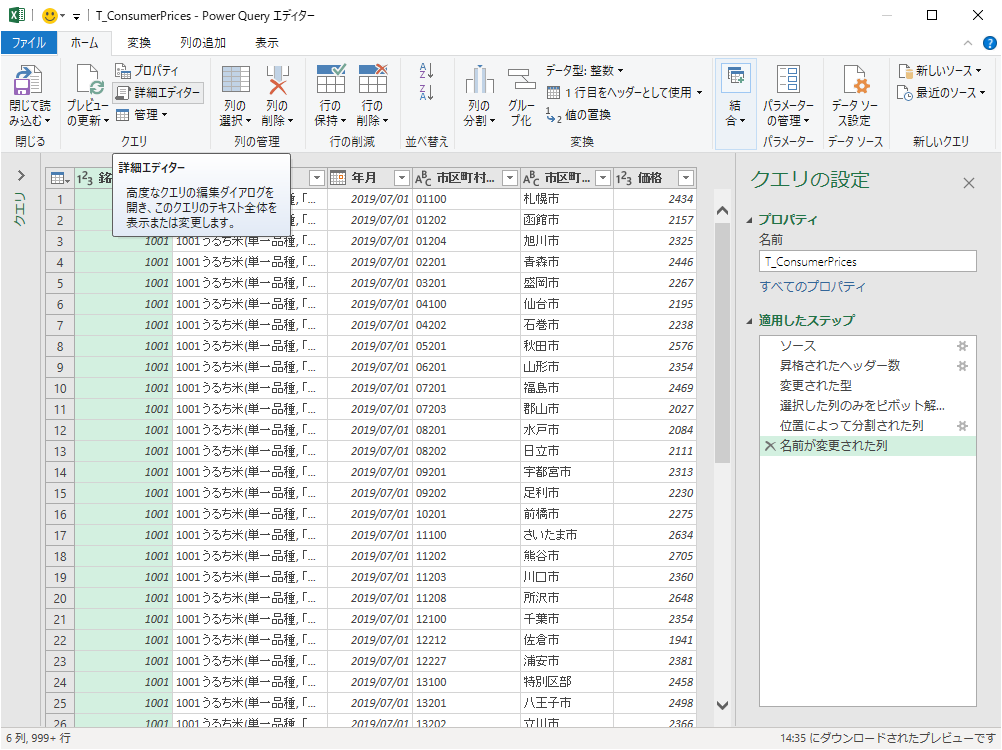
Power Query エディターの「詳細エディター」
EXCEL に VBA, リレーショナルデータベースに SQL という言語があるように,Power Query にも言語がある.DAX と言われるものである.「詳細エディター」で確認できる.
DAXを確認する
前半は定義部分,後半は行った作業について記述してあるように見える.
定義部分では列名とデータ型を定義し {} でくくってある.作業は Table.PromoteHeaders, Table.TransformColumnTypes, Table.Unpivot や Table.SplitColumn, Table.RenameColumns などのテーブルに対する関数で記述してある.
let
ソース = Csv.Document(File.Contents("C:\Users\UserName\Dropbox\20190908BLOG\T_ConsumerPrices.txt"),[Delimiter=" ", Columns=84, Encoding=932, QuoteStyle=QuoteStyle.None]),
昇格されたヘッダー数 = Table.PromoteHeaders(ソース, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"銘柄(H27年基準) コード", Int64.Type}, {"銘柄(H27年基準)", type text}, {"時間軸(月)", type date}, {"01100札幌市", Int64.Type}, {"01202函館市", Int64.Type}, {"01204旭川市", Int64.Type}, {"02201青森市", Int64.Type}, {"03201盛岡市", Int64.Type}, {"04100仙台市", Int64.Type}, {"04202石巻市", Int64.Type}, {"05201秋田市", Int64.Type}, {"06201山形市", Int64.Type}, {"07201福島市", Int64.Type}, {"07203郡山市", Int64.Type}, {"08201水戸市", Int64.Type}, {"08202日立市", Int64.Type}, {"09201宇都宮市", Int64.Type}, {"09202足利市", Int64.Type}, {"10201前橋市", Int64.Type}, {"11100さいたま市", Int64.Type}, {"11202熊谷市", Int64.Type}, {"11203川口市", Int64.Type}, {"11208所沢市", Int64.Type}, {"12100千葉市", Int64.Type}, {"12212佐倉市", Int64.Type}, {"12227浦安市", Int64.Type}, {"13100特別区部", Int64.Type}, {"13201八王子市", Int64.Type}, {"13202立川市", Int64.Type}, {"13206府中市", Int64.Type}, {"14100横浜市", Int64.Type}, {"14130川崎市", Int64.Type}, {"14150相模原市", Int64.Type}, {"14201横須賀市", Int64.Type}, {"15100新潟市", Int64.Type}, {"15202長岡市", Int64.Type}, {"16201富山市", Int64.Type}, {"17201金沢市", Int64.Type}, {"18201福井市", Int64.Type}, {"19201甲府市", Int64.Type}, {"20201長野市", Int64.Type}, {"20202松本市", Int64.Type}, {"21201岐阜市", Int64.Type}, {"22100静岡市", Int64.Type}, {"22130浜松市", Int64.Type}, {"22210富士市", Int64.Type}, {"23100名古屋市", Int64.Type}, {"23201豊橋市", Int64.Type}, {"24201津市", Int64.Type}, {"24204松阪市", Int64.Type}, {"25201大津市", Int64.Type}, {"26100京都市", Int64.Type}, {"27100大阪市", Int64.Type}, {"27140堺市", Int64.Type}, {"27210枚方市", Int64.Type}, {"27227東大阪市", Int64.Type}, {"28100神戸市", Int64.Type}, {"28201姫路市", Int64.Type}, {"28204西宮市", Int64.Type}, {"28207伊丹市", Int64.Type}, {"29201奈良市", Int64.Type}, {"30201和歌山市", Int64.Type}, {"31201鳥取市", Int64.Type}, {"32201松江市", Int64.Type}, {"33100岡山市", Int64.Type}, {"34100広島市", Int64.Type}, {"34207福山市", Int64.Type}, {"35202宇部市", Int64.Type}, {"35203山口市", Int64.Type}, {"36201徳島市", Int64.Type}, {"37201高松市", Int64.Type}, {"38201松山市", Int64.Type}, {"38202今治市", Int64.Type}, {"39201高知市", Int64.Type}, {"40100北九州市", Int64.Type}, {"40130福岡市", Int64.Type}, {"41201佐賀市", Int64.Type}, {"42201長崎市", Int64.Type}, {"42202佐世保市", Int64.Type}, {"43100熊本市", Int64.Type}, {"44201大分市", Int64.Type}, {"45201宮崎市", Int64.Type}, {"46201鹿児島市", Int64.Type}, {"47201那覇市", Int64.Type}}),
選択した列のみをピボット解除しました = Table.Unpivot(変更された型, {"01100札幌市", "01202函館市", "01204旭川市", "02201青森市", "03201盛岡市", "04100仙台市", "04202石巻市", "05201秋田市", "06201山形市", "07201福島市", "07203郡山市", "08201水戸市", "08202日立市", "09201宇都宮市", "09202足利市", "10201前橋市", "11100さいたま市", "11202熊谷市", "11203川口市", "11208所沢市", "12100千葉市", "12212佐倉市", "12227浦安市", "13100特別区部", "13201八王子市", "13202立川市", "13206府中市", "14100横浜市", "14130川崎市", "14150相模原市", "14201横須賀市", "15100新潟市", "15202長岡市", "16201富山市", "17201金沢市", "18201福井市", "19201甲府市", "20201長野市", "20202松本市", "21201岐阜市", "22100静岡市", "22130浜松市", "22210富士市", "23100名古屋市", "23201豊橋市", "24201津市", "24204松阪市", "25201大津市", "26100京都市", "27100大阪市", "27140堺市", "27210枚方市", "27227東大阪市", "28100神戸市", "28201姫路市", "28204西宮市", "28207伊丹市", "29201奈良市", "30201和歌山市", "31201鳥取市", "32201松江市", "33100岡山市", "34100広島市", "34207福山市", "35202宇部市", "35203山口市", "36201徳島市", "37201高松市", "38201松山市", "38202今治市", "39201高知市", "40100北九州市", "40130福岡市", "41201佐賀市", "42201長崎市", "42202佐世保市", "43100熊本市", "44201大分市", "45201宮崎市", "46201鹿児島市", "47201那覇市"}, "属性", "値"),
位置によって分割された列 = Table.SplitColumn(選択した列のみをピボット解除しました, "属性", Splitter.SplitTextByRepeatedLengths(5), {"属性.1", "属性.2"}),
#"名前が変更された列 " = Table.RenameColumns(位置によって分割された列,{{"属性.1", "市区町村コード"}, {"属性.2", "市区町村"}, {"値", "価格"}, {"銘柄(H27年基準) コード", "銘柄コード"}, {"銘柄(H27年基準)", "銘柄"}, {"時間軸(月)", "年月"}})
in
#"名前が変更された列 "
まとめ
総務省のデータベース e-Stat から小売物価統計調査 小売物価統計調査(動向編)のデータをダウンロードし,EXCEL のデータモデルにインポートした.
集約されたデータファイルを第一正規形に変換するには Power Query のピボット解除が必須であった.
ヘッダーの修正とデータの置換にテキストエディタが有用であった.
テーブルに収まりきらないデータでもデータモデルに格納することで EXCEL で扱うことができた.
このデータモデルからデータをどう取り出すかが今後の課題である.
“180万件のデータをPower Queryで処理してEXCELがオーバーフローした話” への1件の返信