
これまでは日本の都市人口の過去の推移を見てきた.総務省には日本の都市人口の推移予測がある.今回はこのデータをグラフにする.
データを可視化するにあたり,重要なのは引き算である.強調すべき系列のみを強調するために,VBA の知識が欠かせない.
グラフの系列にデータラベルを表示する方法にはいくつかある.
eStat でのデータの取得
地域の選択
eStat のトップページから「地域」をクリックする.

「地域選択」画面に遷移する.「特別区部」にチェックを入れて「すべて選択」をクリックする.
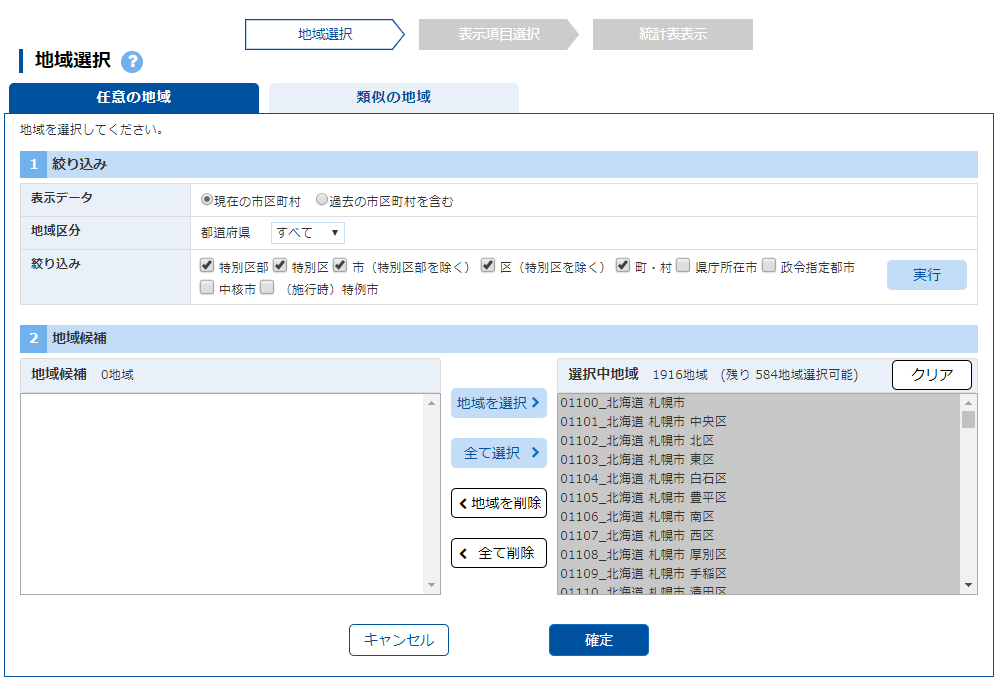
表示項目選択
「表示項目選択」画面に遷移する.「分野」は「A 人口・世帯」,「大分類」は「A1 人口の規模・構造」,「小分類」は「A19 都道府県推計による人口」を選ぶと 2020 年から 2045 年までの将来推計人口が残る.「すべて選択」をクリックする.
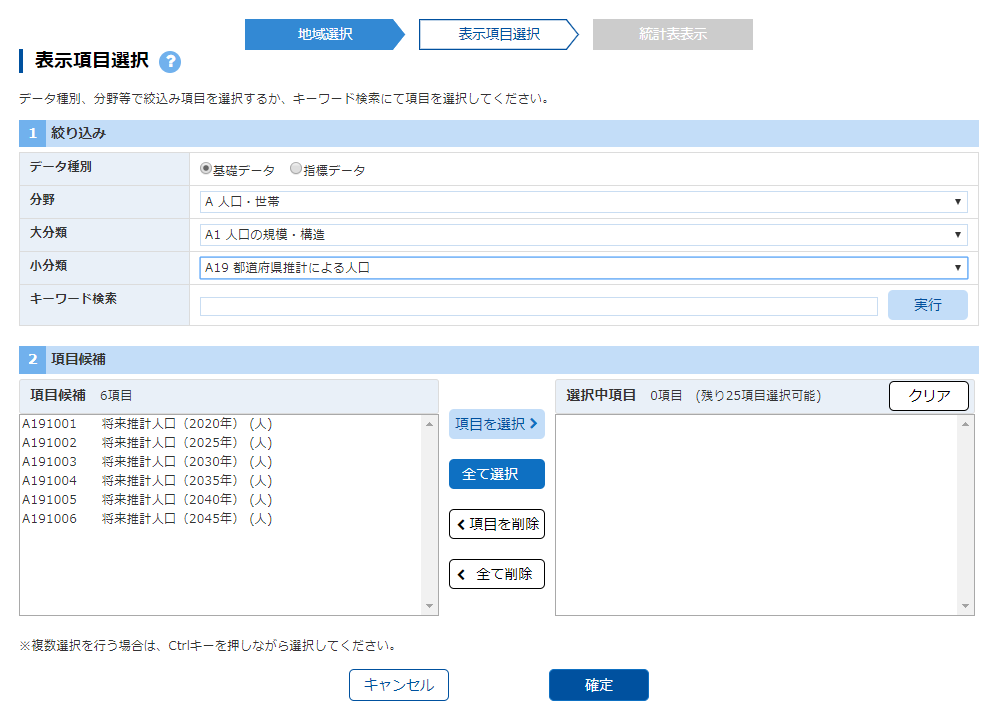
データ表示
「データ表示」画面に遷移する.右上の「ダウンロード」ボタンをクリックする.
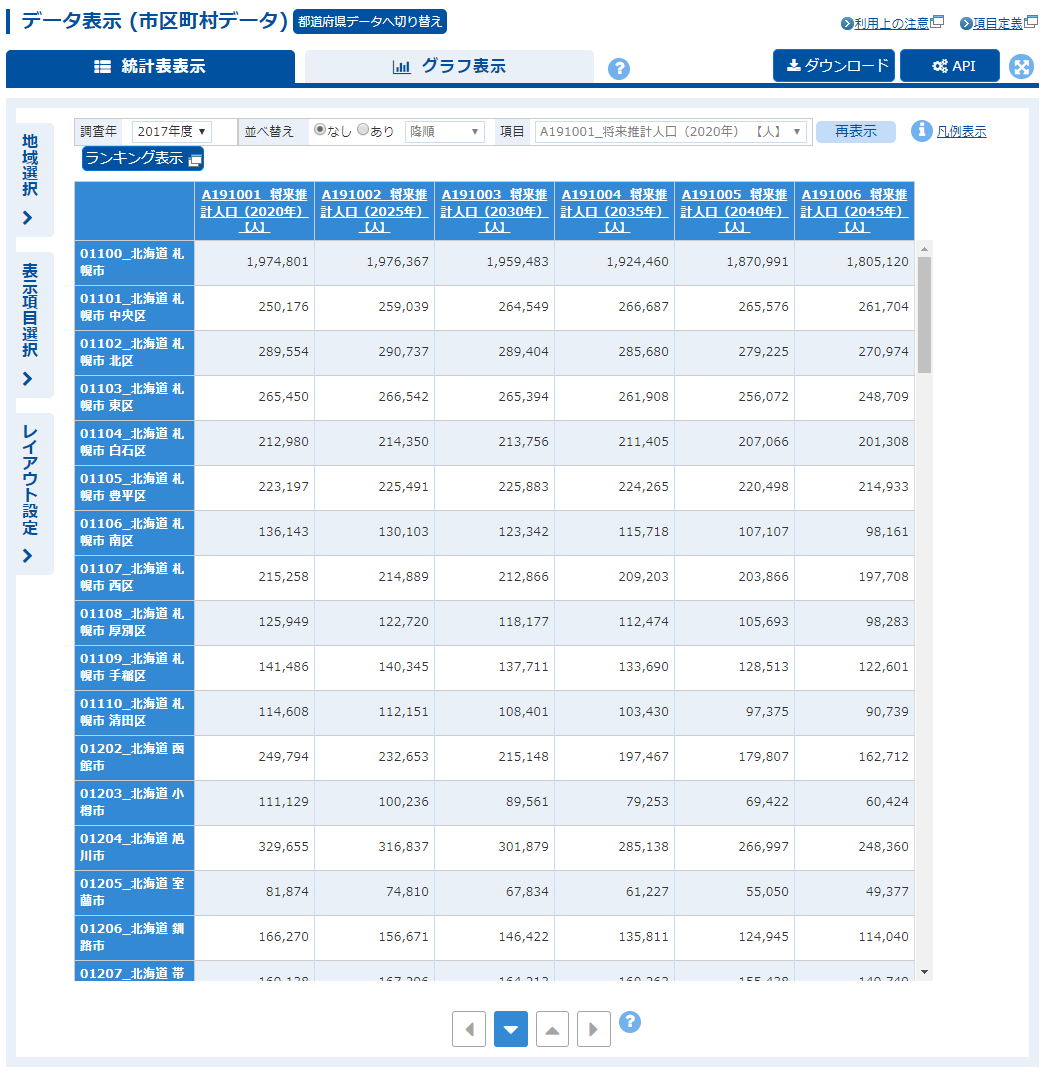
表ダウンロード
「表ダウンロード」ウィンドウが開く.「注釈を表示する」のチェックを外し,「桁区切りを使用しない」をチェックして「ダウンロード」をクリックする.
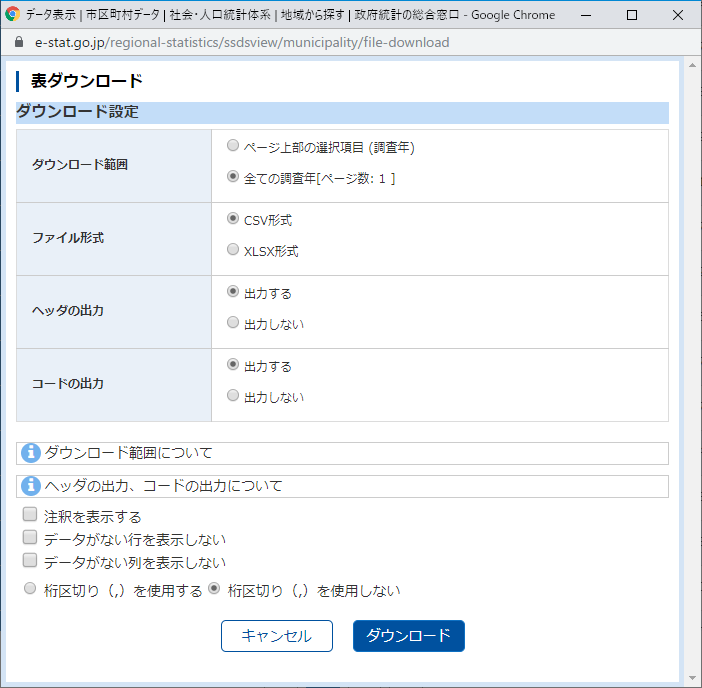
実際のダウンロード画面に推移する.「ダウンロード」をクリックする.
ブラウザのウィンドウ下部にダウンロードされたファイルが見える.

テキストエディタでデータ整形
メモ帳で開く
ダウンロードされたファイルを右クリックして「プログラムから開く」「メモ帳」と進む.

文字列の置換
これ以降実際に使うデータはヘッダ部分以下であるが,エラー文字列を削除しておく必要がある.エディタの置換機能を使う.
一つ目.”***” の文字列を “” に置換する.
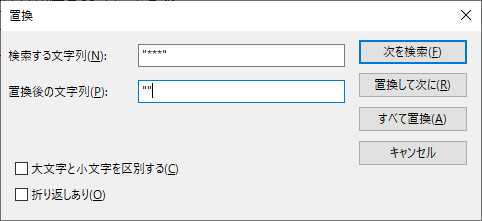
二つ目.”-” を “” に置換する.
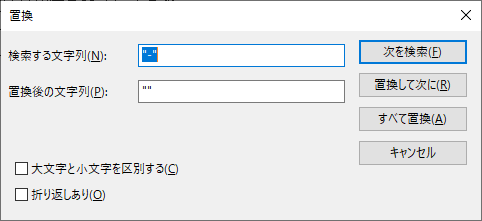
三つ目.”X” を “” に置換する.
不要な文字列の削除
先頭の 8 行が邪魔になるので選択して削除する.なお,eStat の場合は該当しないが,ファイルの末尾にも余計な文字列が付いてくることがあるため,念のため確認しておくとよい.
保存して閉じる.
Power Query での作業
新規作成からデータの取得
今保存した csv ファイルをダブルクリックしてはいけない.必ず EXCEL の空白のブックを新規作成し,「データの取得」からインポートしなくてはならない.
データの変換
ここで「読み込み」ではなく,「データの変換」をクリックして Power Query エディターを起動する.目的はピボットされたデータをピボット解除することである.
ここで不思議に思う人がいるかもしれない.すでに市区町村ごとに経時的なデータ系列ができている.このまま EXCEL のデータ系列として指定すれば,すぐにグラフができるではないかと.
疑問に答えよう.それは,データベースのテーブルは正規化されており,その状態からグラフのデータ系列を作成する方法が最も汎用性が高いから,である.
eStat からダウンロードしたデータは非正規形であり,正規化されていない.人間の認知機能はむしろ非正規形のほうが理解しやすく,正規形は冗長に見える.しかし,ソフトウェアは正規化されたデータベースでないとデータをうまく扱えない.このギャップが問題である.
変更された型を削除
まず,「適用したステップ」で「変更された型」を削除して履歴を戻す.これは Power Query のおせっかい機能の一つだ.今後この作業は明示しないが,都度行っておく.
不要な列の削除
不要な列を削除する.今回は「調査年コード」「調査年」「/項目」である.
列の分割
「地域」の列を「都道府県」と「市区町村」に分割したい.半角スペースがあるのでこれを区切り記号とする.

区切り記号による分割
右クリックして「列の分割」「区切り記号による分割」と進む.
一番左の区切り記号
「区切り記号」は「スペース」が選ばれているので,「分割」のチェックを「一番左の区切り記号」とする.
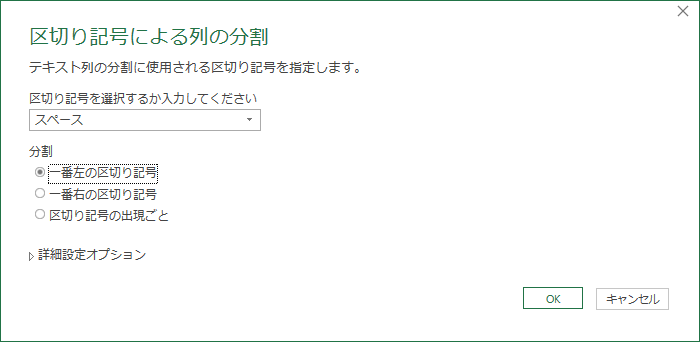
その結果,都道府県と市区町村が分割された.それぞれ列名を「都道府県」「市区町村」と変更する.
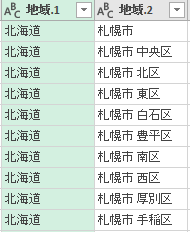
都道府県コードを作りたい
さて,今後の作業のために都道府県コードの列を作っておきたい.「地域コード」の左2桁を参照すればよいのだが,テキスト関数が不慣れでうまく行かないため,カスタム列を作成して地域コードを参照することにした.
カスタム列を追加
「列の追加」タブから「カスタム列」をクリックする.
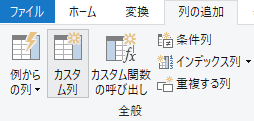
「カスタム列」ダイアログが開くので,「新しい列名」に「都道府県コード」,「カスタム列の式」に「地域コード」を選択して「挿入」する.
文字数で列を分割
右端にカスタム列ができるが,これをドラッグして適当な位置に持ってくる.列名を右クリックして「列の分割」「文字数による分割」と進む.
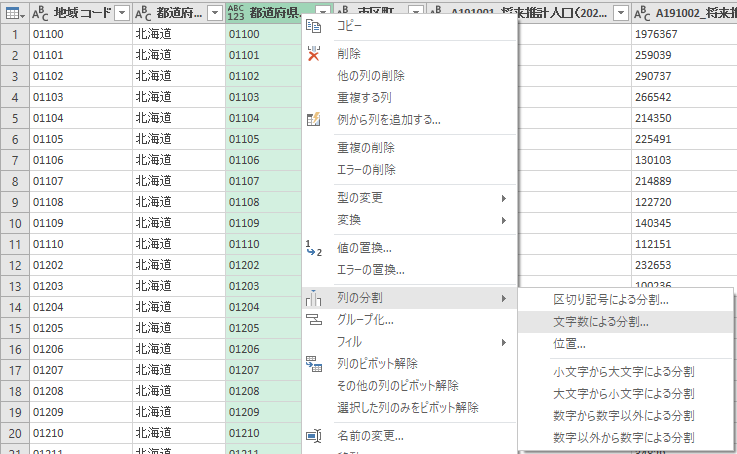
できるだけ左側で1回
「文字数」は 2 とタイプし「分割」は「できるだけ左側で1回」をチェックする.
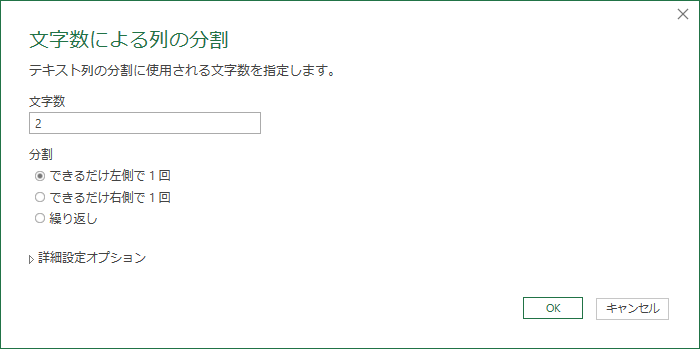
都道府県コードの列を残して削除
2 列に分割されるが,新しく出来た右側の列は不要のため削除する.残した「都道府県コード」列には型の変換が起きているが,これはこのままにしておく.
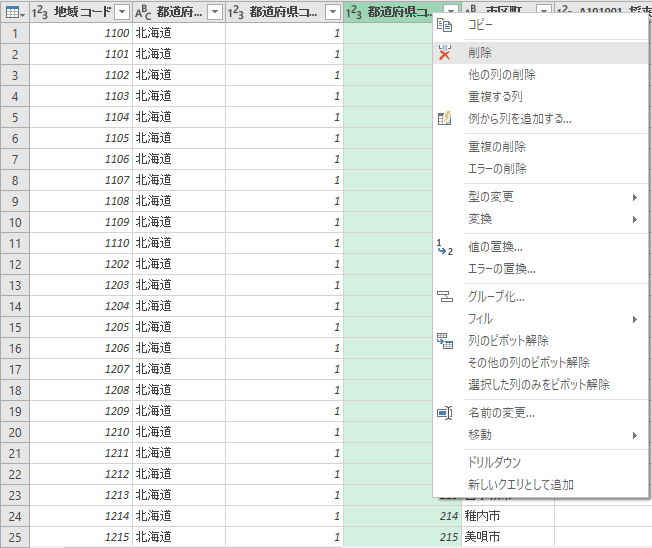
ピボット解除
列名の変更
A191001 から A191006 までの 6 列の列名を変更する.残すのは年である.
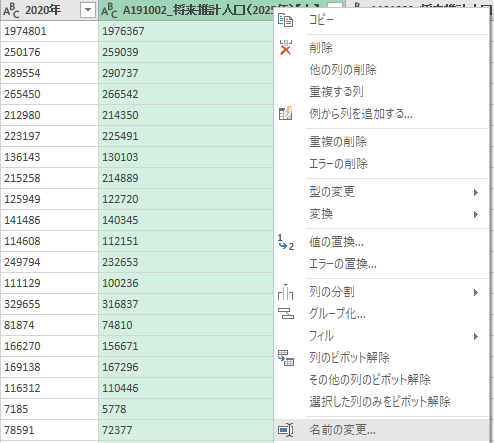
選択した列のみをピボット解除
その 6 列をまとめて選択した状態で「選択した列のみをピボット解除」する.
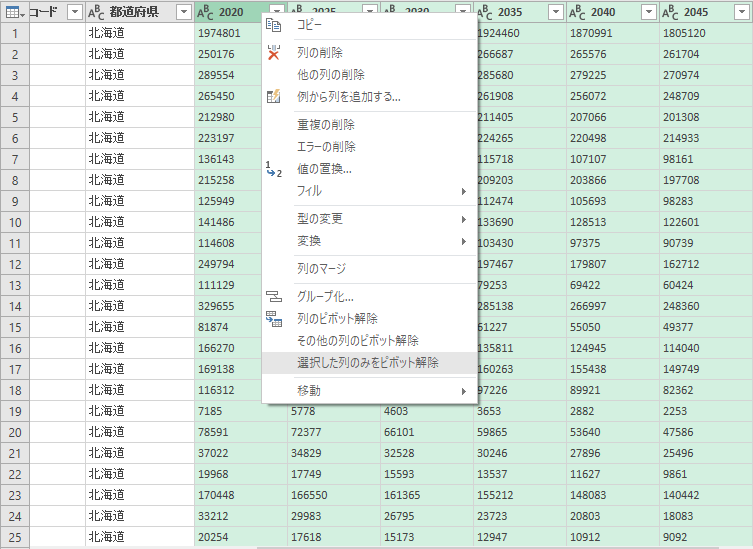
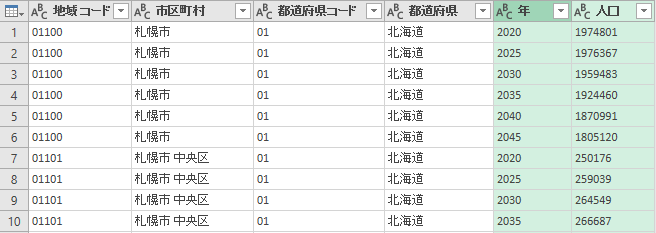
列名を変更
「属性」「値」という列名になるが,それぞれ「年」「人口」と変更する.
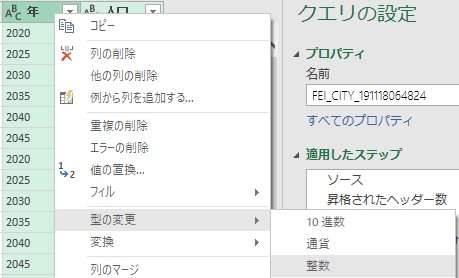
型の変更
さらに型を「整数」に変更する.
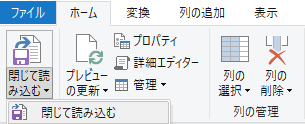
閉じて読み込む
最後に「閉じて読み込む」.
ワークシートでの作業
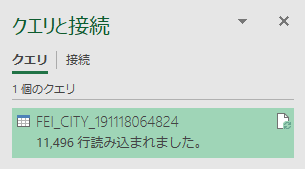
クエリと接続
11,406 行がインポートされた.データはテーブルとしてインポートされている.
空白行の削除
震災や他の原因で人口推移予測のない自治体もある.こういった空白のデータ行は集計の邪魔になるため,削除しておきたい.
テーブルのフィルターで(空白セル)のみチェックする.
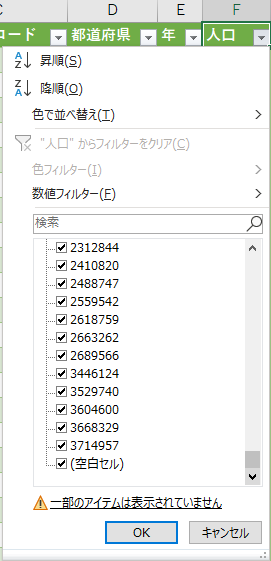
636 件が見つかる.

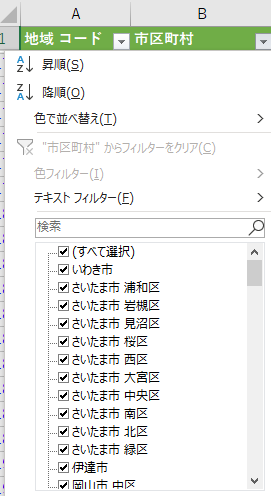
データのない市区町村
その状態で市区町村のフィルターをポップアップすると,データのない自治体が分かる.これらをまとめて削除しておく.
市区町村マスターの作成
マスターを作成するにはいくつか方法がある.最も手っ取り早いのはワークシートを複製してキーの重複を排除し,マスター化する方法である.ここではデータベースに接続してマスターをインポートする方法を採用する.
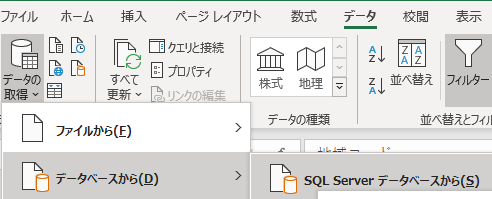
SQL Server への接続
データ,データの取得,データベースから,SQL Server データベースからと進む.
サーバーとデータベースの指定
ダイアログでサーバーとデータベースを指定する.
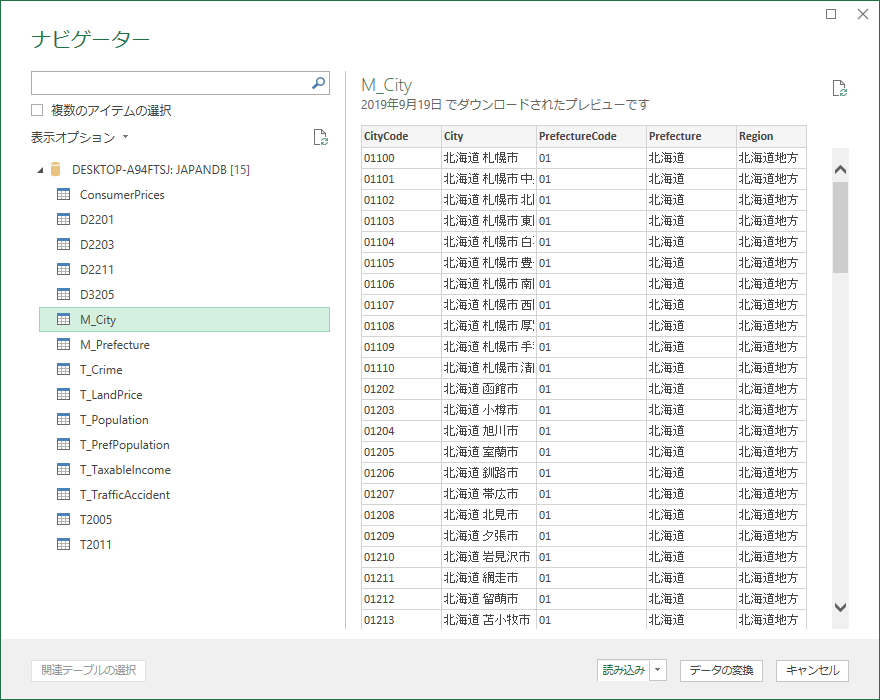
テーブルの指定
M_City というテーブルが市区町村マスターである(筆者環境で作成済み).テーブルは第一正規形になっているのでこのまま読み込む.
インポート結果
1,916 件のデータがインポートされた.結果はテーブルとなる.
ここまでの作業で,ワークシートは全体で 3 枚,Sheet1 は白紙,Sheet2 には 10,860 件のデータ,Sheet3 には 1,916 件のマスターデータが入っているはずである.次の章では Sheet1 に各都道府県のグラフを描いていく.
VBA でのグラフ作成
基本に立ち返る
ここでグラフの基本に立ち返ろう.何を示したいのか?それに適したグラフの種類は何か?
示したいのは都道府県ごとの都市の将来推計人口の経時的推移である.データ系列には時間軸が含まれるから,折れ線グラフが適当である.
認知負荷は必要最小限に

グラフは複雑なデータを視覚的なイメージに変換する.その目的はシグナルをノイズから浮かび上がらせることである.
人間は世界を認知するのに視覚にその多くを頼っている.グラフは視覚に直接訴えかけるものであるが,人間の認知能力には個人差があり,視覚もその例外ではない.
グラフ作成者が考慮すべきなのは,視覚優位ではない人にもデータを理解してもらうことである.そのため,認知負荷は可能な限り取り除かなくてはならない.
認知負荷を下げる方法
認知負荷を下げるにはどのような方法があるか?いくつかある.使用する色を厳選すること.使用するグラフの要素を必要最小限にすること.レイアウトを単純明快にすること.
グラフの要素の中でも,使う色は重要である.グラフの要素で色を指定できないものは存在しない.背景に白,ノイズに無彩色,シグナルに強調色を用いるのが基本である.
使用するグラフの要素は必要最小限に絞り込む.最低でもデータ系列,項目軸の項目,値軸の値,タイトルがあればよい.
単純明快なレイアウトとは,プロットエリアがグラフエリアの中央で広い面積を占めており,使用するフォントが控えめで品位のあるものであり,それでいて伝えたいメッセージが明確であるものである.
では,コードを見ていこう.
基本コード
VBE を起動して標準モジュールを挿入し,下記のコードを入力する.このコードはグラフの基本骨格であるデータをテーブルから取得して入力する.
Option Explicit
Sub PopulationChart()
Dim mySht1 As Worksheet
Dim mySht2 As Worksheet
Dim mySht3 As Worksheet
Dim myLstObj2 As ListObject
Dim myLstObj3 As ListObject
Set mySht1 = Worksheets("Sheet1")
Set mySht2 = Worksheets("Sheet2")
Set mySht3 = Worksheets("Sheet3")
Set myLstObj2 = mySht2.ListObjects.Item(mySht2.ListObjects.Count)
Set myLstObj3 = mySht3.ListObjects.Item(mySht3.ListObjects.Count)
Dim myRng1 As Range
Dim myRng2 As Range
Dim myRng3 As Range
Dim myCht As Chart
Dim i As Long
Dim myPrefCode As String
Dim myPref As String
Dim j As Long
Dim myXValue() As Long
Dim myValue() As Long
Dim myCity As String
Dim mySeries As Series
With mySht1
For i = 1 To 47
'Debug.Print i, (i - 1) Mod 6, (i - 1) \ 6
Set myCht = .Shapes.AddChart2(Style:=-1, _
XlChartType:=xlXYScatterLines, _
Left:=200 * ((i - 1) Mod 6), _
Top:=200 * ((i - 1) \ 6), _
Width:=200, _
Height:=200).Chart
With myLstObj3
myPrefCode = WorksheetFunction.Text(i, "00")
'Debug.Print i, myPrefCode
.Range.AutoFilter field:=3, Criteria1:=myPrefCode
Set myRng1 = Intersect(.DataBodyRange, _
.Range.SpecialCells(xlCellTypeVisible), _
.ListColumns("CityCode").Range)
'Debug.Print i, myRng1.Address
myPref = myRng1.Offset(0, 3).Resize(1).Value
'Debug.Print i, myPref
For Each myRng2 In myRng1
'Debug.Print myRng2.Address
With myLstObj2
.Range.AutoFilter field:=1, Criteria1:=myRng2.Value
Set myRng3 = Intersect(.DataBodyRange, _
.Range.SpecialCells(xlCellTypeVisible))
If myRng3 Is Nothing Then
Else
'Debug.Print myRng3.Address
For j = 0 To myRng3.Rows.Count - 1
'Debug.Print j
ReDim Preserve myXValue(j)
ReDim Preserve myValue(j)
myCity = myRng3.Cells(j + 1, 2)
myXValue(j) = myRng3.Cells(j + 1, 5)
myValue(j) = myRng3.Cells(j + 1, 6)
'Debug.Print j, myCity, myXValue(j), myValue(j)
Next j
'(1)■
'Debug.Print myCht.SeriesCollection.Count
If myCht.SeriesCollection.Count = 255 Then Exit For
Set mySeries = myCht.SeriesCollection.NewSeries
'Debug.Print mySeries.PlotOrder
With mySeries
.Name = myCity
.XValues = myXValue
.Values = myValue
'(4)■
'(1)■
End With
End If
.Range.AutoFilter field:=1
End With
Next myRng2
.Range.AutoFilter field:=3
End With
'(2)■
Next i
End With
End Sub
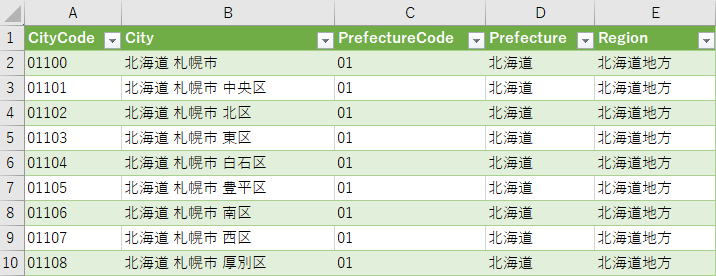
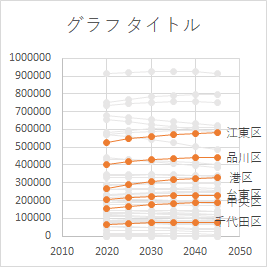
悪い見本
下図が上記の基本コードで作成したままのグラフである.「よく見る」グラフだと思う.だが,これは悪い見本だ.理由を挙げる.
データ系列が絵の具のパレット
一つの系列に一つの色を割り当てた結果,プロットエリアが絵の具をすべてぶちまけたパレットになってしまっている.ノイズは無彩色の灰色に統一すべきだ.
都市名が分からない
都道府県によっては 100 を超える市区町村を有しており,全てを表記することはできない.ましてや凡例など表示しようものなら,グラフエリアが凡例で埋め尽くされてしまう.
都市名はデータラベルに系列名で示すが,厳選する必要がある.方法は後述する.
項目軸・値軸の数値が大きすぎる
項目軸は年であるから 4 桁に収まっているが,本来データのない 2010 年や 2050 年まで表示されている.切りよく 2020 から始まり,2045 で終わるようにすべきだ.
また値軸は 10 万の単位でゼロが何個も並んでおり,ごちゃごちゃした印象を与える.表示単位を万に統一して数字の個数を減らすべきだ.その分,プロットエリアを広げることができる.
また,値軸に表示されている値の個数も多すぎる.最大値が 100 万なら,せいぜい 20 万刻みだろう.
もっと言うと,軸の表示自体が不要だ.
目盛線は必要か?
軸と同様,目盛線は認知負荷を与える.日本人は表の罫線が大好きだが,それと同様のこだわりを感じる.これも不要だ.
タイトルの位置と大きさ
グラフタイトルの位置はデフォルトで中央になっている.好みの問題かも知れないが,左端に寄せたほうがよい.タイトルのフォントのサイズも全体のバランスの中で考える必要がある.
勝ち組を探せ
強調すべきデータ系列(シグナル)と,そうでない系列(ノイズ)とを分ける基準は何か?今回は「人口が増加し続けること」を条件とする.
具体的には 2020 年人口よりも 2025 年人口が大きく,2025 年人口よりも 2030 年人口が大きく…という条件式を AND で接続する.
ちょっと考えれば分かるが,この条件を満たす都市は非常に少ない.いわば「勝ち組」を抽出しているのである.
人口が減少し衰退していく都市と今後も人口が増え続けて繁栄していく都市を区別するには,データ系列を色で塗り分けるのが最善だと考えられる.
という目で上記の基本コードを眺める.コメントアウトした (1) の箇所にその具体的なコードを記述する.
条件式
myBool という Boolean 型の変数を定義する.False で初期化し,先の条件を満たした場合に限って True に変更する.
pre タグ内では > という表記が > と表示される.各自で読み替えてほしい.
'(1)
Dim myBool As Boolean
myBool = False
If (myValue(j - 1) > myValue(j - 2)) _
And (myValue(j - 2) > myValue(j - 3)) _
And (myValue(j - 3) > myValue(j - 4)) _
And (myValue(j - 4) > myValue(j - 5)) _
And (myValue(j - 5) > myValue(j - 6)) _
Then
myBool = True
End If
データ系列を塗り分ける
強調すべき系列には色彩を与え,それ以外は無彩色の灰色とする.理由は不明だが,Color オブジェクトの .ObjectThemeColor プロパティに定数を指定できなかったため,RGB プロパティに RGB 関数で指定している.
With mySeries
.Name = myCity
.XValues = myXValue
.Values = myValue
'(1)■
If myBool Then
With .Format.Fill
.ForeColor.RGB = RGB(237, 125, 49)
.BackColor.RGB = RGB(237, 125, 49)
.Transparency = 0
End With
With .Format.Line
.ForeColor.RGB = RGB(237, 125, 49)
.Transparency = 0
.Weight = 0.5
End With
Else
With .Format.Fill
.ForeColor.RGB = RGB(231, 230, 230)
.BackColor.RGB = RGB(231, 230, 230)
.Transparency = 0
End With
With .Format.Line
.ForeColor.RGB = RGB(231, 230, 230)
.Transparency = 0
.Weight = 0.25
End With
End If
End With
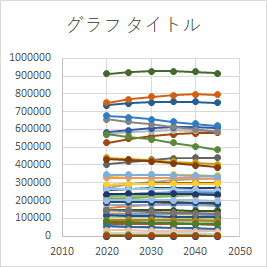
データ系列の順番を入れ替える
上記のグラフでは強調したい系列がそうでない系列の下に埋もれてしまっている.この場合は .PlotOrder プロパティを変更して系列の順番を入れ替える.
.PlotOrder プロパティは大きいほど前面に出てくる.逆に,ある系列の .PlotOrder プロパティを 1 にすれば,それは最後面に引っ込む(9 行目).
With mySeries
.Name = myCity
.XValues = myXValue
.Values = myValue
'(1)■
If myBool Then
Else
.PlotOrder = 1
End If
End With
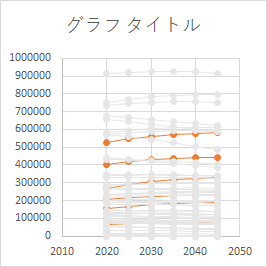
しかし,ここは本来なら,Series オブジェクトの最終ポイントの値で降順ソートすべきところだと思う.
データラベルで系列名を表示する
系列のデータラベルを表示するには,まず .HasDataLabels プロパティを有効にする(9 行目).そして系列名を表示するオプションを有効にする(13 行目).さらに,デフォルトで系列の値を表示する設定なので,変更して値を消す(18 – 20 行目).
myBool の真理値はここで .HasDataLabels プロパティに引き継がれる.
データラベルが重なって表示されている.計算で .Top プロパティを設定してもよいが,ここでは最後に手動で調整することにする.
データラベルの .Top プロパティを計算して調整するためには,データ系列の順番を最終ポイントの値で並び替える必要がある.しかし,ここに手をつけるにはオブジェクトのソートに挑戦する必要がある.VBA にはオブジェクトをソートするメソッドが用意されていないためである.これは別項で扱ったほうがよいだろう.
Dim myDataLabel As DataLabel
With mySeries
.Name = myCity
.XValues = myXValue
.Values = myValue
'(1)■
If myBool Then
.HasDataLabels = True
'Debug.Print .DataLabels.Count
Set myDataLabel = .Points.Item(.Points.Count).DataLabel
With myDataLabel
.ShowSeriesName = True
.Format.TextFrame2.WordWrap = msoFalse
'.Format.TextFrame2.AutoSize = msoAutoSizeShapeToFitText
'Debug.Print myDataLabel.Position
End With
For Each myDataLabel In .DataLabels
myDataLabel.ShowValue = False
Next myDataLabel
Else
.PlotOrder = 1
End If
End With
グラフの各要素を変更する
上記基本コードの (2) に該当する部分に下記のコードを置いていく.変更を加える要素としては軸,目盛り,タイトル,プロットエリア,フォントオブジェクトなどである.
軸
横軸と縦軸をそれぞれ設定する.横軸では境界値の最大値と最小値を設定し,不可視としている.
縦軸は表示単位を万に変更してラベルを消し,軸そのものを不可視にしている.その後 (3) に挿入するコードを紹介する.
'(2)■
Dim myAxis As Axis
'(2)■
With myCht
Set myAxis = .Axes(xlCategory)
With myAxis
.Format.Line.Visible = msoFalse
.MinimumScale = "2020"
.MaximumScale = "2045"
.MajorGridlines.Format.Line.Visible = msoFalse
End With
Set myAxis = .Axes(xlValue)
With myAxis
.Format.Line.Visible = msoFalse
.DisplayUnit = xlTenThousands
.HasDisplayUnitLabel = False
.MajorGridlines.Format.Line.Visible = msoFalse
'(3)■
End With
End With
'(2)■
タイトルの位置
タイトル位置を左端に寄せ,キャプションを都道府県名としている.
'(2)■
With myCht
.HasTitle = True
With .ChartTitle
.Caption = myPref
.Left = 0
End With
End With
'(2)■
プロットエリアの位置と大きさ
縦軸の文字数が減ったのでプロットエリアの位置と大きさを変更する余地ができた.
'(2)■
With myCht
With .PlotArea
.Format.Fill.Visible = msoFalse
.Format.Line.Visible = msoFalse
'Debug.Print .Left, .InsideLeft, .Width, .InsideWidth
.Left = -10
.Width = 150
'Debug.Print .Left, .InsideLeft, .Width, .InsideWidth
End With
End With
'(2)■
Font2 オブジェクト
フォント (Font2) はグラフエリアから一括して取得する.日本語フォントと英語フォントを別に設定する必要はあるが,数字を上品にしたいだけなのでこのままでよい.各自で好みのフォントに設定したらよいだろう.
'(2)■
With myCht
With .ChartArea
.Format.Fill.ForeColor.ObjectThemeColor = msoThemeColorBackground1
.Format.Line.Visible = msoFalse
.Format.TextFrame2.TextRange.Font.Name = "TimesNewRoman"
End With
End With
'(2)■
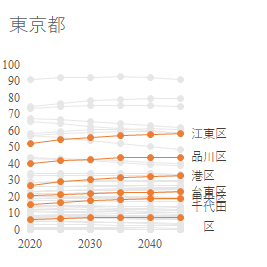
Series オブジェクト,再び
オブジェクトの書式設定には優先順位がある.明確に文書で書かれているわけではないが,試行錯誤の結果そう確信するに至った.
白紙のグラフには先にデータ系列を与えてからでないと,プロットエリアの書式を設定できない.データ系列のないグラフは,ただの Shape オブジェクトである.
また,特に大きさに関しては,プロットエリアの書式を設定した後でないと,先にデータラベルの書式を設定しても反映されない.
そのため,データ系列を与えた直後にデータラベルの書式を設定することはできず,まずすべてのデータ系列を与え,次にプロットエリアの書式を設定して,やっとデータラベルの書式を設定することができる.コード記述の順序もそれに従う.
'(2)-1■
For Each mySeries In .SeriesCollection
With mySeries
If .HasDataLabels Then
Set myDataLabel = .Points.Item(.Points.Count).DataLabel
With myDataLabel
'Debug.Print .Caption, .Width
'Debug.Print .Width, .Format.TextFrame2.HorizontalAnchor
.Width = 50
.Format.TextFrame2.WordWrap = msoFalse
.Format.TextFrame2.AutoSize = msoAutoSizeShapeToFitText
End With
End If
End With
Next mySeries
'(2)-1■
軸,再び
境界値の最大値に応じて .MaximumScale を変更し, .MajorGridlines が 5 段階になるように .MajorUnit を変更している.'(3)■に挿入するコードを紹介している.
'(3)■
Select Case .MaximumScale
Case 100000 To 250000
.MaximumScale = 250000
Case 250000 + 1 To 500000
.MaximumScale = 500000
Case 500000 + 1 To 1000000
.MaximumScale = 1000000
Case 1000000 + 1 To 2500000
.MaximumScale = 2500000
Case 2500000 + 1 To 5000000
.MaximumScale = 5000000
Case Else
End Select
.MajorUnit = .MaximumScale / 5
'(3)■
興味深い現象だが,Case 100000 To 250000 の記述をCase 10 * 10000 To 25 * 10000 のように書き換えるとオーバーフローしてエラーとなる..MaximumScale = 25 * 10000 としてもやはりオーバーフローする.
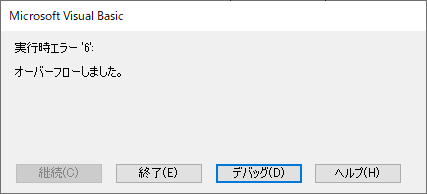
逆に式の左辺で計算を行って真偽判定してもエラーにならない.どちらも等号記号を使っているが,真偽判定と値の代入とでは振る舞いが違う,ということなのだろう.
'(3)■
Select Case .MaximumScale / 10000
Case 10 To 25
.MaximumScale = 250000
Case 25 + 0.0001 To 50
.MaximumScale = 500000
Case 50 + 0.0001 To 100
.MaximumScale = 1000000
Case 100 + 0.0001 To 250
.MaximumScale = 2500000
Case 250 + 0.0001 To 500
.MaximumScale = 5000000
Case Else
End Select
'(3)■
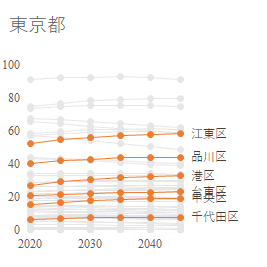
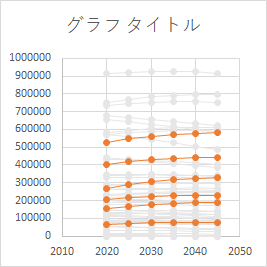
Point オブジェクト
データ系列の点が気になる.この点はない方がすっきりする.下記コードは myBool による判定の結果に関わらず適用したいので,データラベルを設定した With mySeries 句内に記述する.
'(4)■
Dim myPoint As Point
For Each mySeries In .SeriesCollection
With mySeries
'(4)■
For Each myPoint In .Points
.MarkerStyle = xlMarkerStyleNone
Next myPoint
'(4)■
End With
Next mySeries
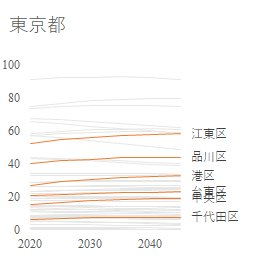
完成コード
Option Explicit
Sub PopulationChart()
Dim mySht1 As Worksheet
Dim mySht2 As Worksheet
Dim mySht3 As Worksheet
Dim myLstObj2 As ListObject
Dim myLstObj3 As ListObject
Set mySht1 = Worksheets("Sheet1")
Set mySht2 = Worksheets("Sheet2")
Set mySht3 = Worksheets("Sheet3")
Set myLstObj2 = mySht2.ListObjects.Item(mySht2.ListObjects.Count)
Set myLstObj3 = mySht3.ListObjects.Item(mySht3.ListObjects.Count)
Dim myRng1 As Range
Dim myRng2 As Range
Dim myRng3 As Range
Dim myCht As Chart
Dim i As Long
Dim myPrefCode As String
Dim myPref As String
Dim j As Long
Dim myXValue() As Long
Dim myValue() As Long
Dim myCity As String
Dim mySeries As Series
'(1)
Dim myBool As Boolean
Dim myDataLabel As DataLabel
'(2)
Dim myAxis As Axis
'(4)
Dim myPoint As Point
With mySht1
For i = 1 To 47
'Debug.Print i, (i - 1) Mod 6, (i - 1) \ 6
Set myCht = .Shapes.AddChart2(Style:=-1, _
XlChartType:=xlXYScatterLines, _
Left:=200 * ((i - 1) Mod 6), _
Top:=200 * ((i - 1) \ 6), _
Width:=200, _
Height:=200).Chart
With myLstObj3
myPrefCode = WorksheetFunction.Text(i, "00")
'Debug.Print i, myPrefCode
.Range.AutoFilter field:=3, Criteria1:=myPrefCode
Set myRng1 = Intersect(.DataBodyRange, _
.Range.SpecialCells(xlCellTypeVisible), _
.ListColumns("CityCode").Range)
'Debug.Print i, myRng1.Address
myPref = myRng1.Offset(0, 3).Resize(1).Value
'Debug.Print i, myPref
For Each myRng2 In myRng1
'Debug.Print myRng2.Address
With myLstObj2
.Range.AutoFilter field:=1, Criteria1:=myRng2.Value
Set myRng3 = Intersect(.DataBodyRange, _
.Range.SpecialCells(xlCellTypeVisible))
If myRng3 Is Nothing Then
Else
'Debug.Print myRng3.Address
For j = 0 To myRng3.Rows.Count - 1
'Debug.Print j
ReDim Preserve myXValue(j)
ReDim Preserve myValue(j)
myCity = myRng3.Cells(j + 1, 2)
myXValue(j) = myRng3.Cells(j + 1, 5)
myValue(j) = myRng3.Cells(j + 1, 6)
'Debug.Print j, myCity, myXValue(j), myValue(j)
Next j
myBool = False
If (myValue(j - 1) > myValue(j - 2)) _
And (myValue(j - 2) > myValue(j - 3)) _
And (myValue(j - 3) > myValue(j - 4)) _
And (myValue(j - 4) > myValue(j - 5)) _
And (myValue(j - 5) > myValue(j - 6)) _
Then
myBool = True
End If
'Debug.Print myCht.SeriesCollection.Count
If myCht.SeriesCollection.Count = 255 Then Exit For
Set mySeries = myCht.SeriesCollection.NewSeries
'Debug.Print mySeries.PlotOrder
With mySeries
.Name = myCity
.XValues = myXValue
.Values = myValue
'(4)■
For Each myPoint In .Points
.MarkerStyle = xlMarkerStyleNone
Next myPoint
'(4)■
'(1)■
If myBool Then
With .Format.Fill
.ForeColor.RGB = RGB(237, 125, 49)
.BackColor.RGB = RGB(237, 125, 49)
.Transparency = 0
End With
With .Format.Line
.ForeColor.RGB = RGB(237, 125, 49)
.Transparency = 0
.Weight = 1
End With
'データラベルを表示
.HasDataLabels = True
'Debug.Print .DataLabels.Count
Set myDataLabel = .Points.Item(.Points.Count).DataLabel
With myDataLabel
'最後のデータラベルに系列名を表示する
'ここでデータラベルの位置を設定しても反映されない
.ShowSeriesName = True
End With
'データラベルの値を消去
For Each myDataLabel In .DataLabels
myDataLabel.ShowValue = False
Next myDataLabel
Else
.PlotOrder = 1
With .Format.Fill
.ForeColor.RGB = RGB(231, 230, 230)
.BackColor.RGB = RGB(231, 230, 230)
.Transparency = 0
End With
With .Format.Line
.ForeColor.RGB = RGB(231, 230, 230)
.Transparency = 0
.Weight = 0.25
End With
End If
'(1)■
End With
End If
.Range.AutoFilter field:=1
End With
Next myRng2
.Range.AutoFilter field:=3
End With
'(2)■
With myCht
Set myAxis = .Axes(xlCategory)
With myAxis
.Format.Line.Visible = msoFalse
.MinimumScale = "2020"
.MaximumScale = "2045"
.MajorGridlines.Format.Line.Visible = msoFalse
End With
Set myAxis = .Axes(xlValue)
With myAxis
.Format.Line.Visible = msoFalse
.DisplayUnit = xlTenThousands
.HasDisplayUnitLabel = False
.MajorGridlines.Format.Line.Visible = msoFalse
'(3)■
'Debug.Print myPref, .MaximumScale / 10000, .MajorUnit / 10000, .MaximumScale / .MajorUnit
Select Case .MaximumScale / 10000
Case 10 To 25
.MaximumScale = 250000
Case 25 + 0.0001 To 50
.MaximumScale = 500000
Case 50 + 0.0001 To 100
.MaximumScale = 1000000
Case 100 + 0.0001 To 250
.MaximumScale = 2500000
Case 250 + 0.0001 To 500
.MaximumScale = 5000000
Case Else
End Select
.MajorUnit = .MaximumScale / 5
'Debug.Print myPref, .MaximumScale / 10000, .MajorUnit / 10000, .MaximumScale / .MajorUnit
'(3)■
End With
.HasTitle = True
With .ChartTitle
.Caption = myPref
.Left = 0
End With
With .PlotArea
.Format.Fill.Visible = msoFalse
.Format.Line.Visible = msoFalse
'Debug.Print .Left, .InsideLeft, .Width, .InsideWidth
.Left = -10
.Width = 150
'Debug.Print .Left, .InsideLeft, .Width, .InsideWidth
End With
With .ChartArea
.Format.Fill.ForeColor.ObjectThemeColor = msoThemeColorBackground1
.Format.Line.Visible = msoFalse
.Format.TextFrame2.TextRange.Font.Name = "TimesNewRoman"
End With
'(2)-1■
For Each mySeries In .SeriesCollection
With mySeries
If .HasDataLabels Then
Set myDataLabel = .Points.Item(.Points.Count).DataLabel
With myDataLabel
'Debug.Print .Caption, .Width
'Debug.Print .Width, .Format.TextFrame2.HorizontalAnchor
.Width = 50
.Format.TextFrame2.WordWrap = msoFalse
.Format.TextFrame2.AutoSize = msoAutoSizeShapeToFitText
End With
End If
End With
Next mySeries
'(2)-1■
End With
'(2)■
Next i
End With
End Sub
まとめと課題
今後 25 年間の日本の各都市の将来推計人口を総務省のデータベースからダウンロードし,グラフを作成した.人口が増加し続ける都市は限られている.
人口が増加し続けると言っても,その年齢構成は高齢者に偏っている.少子化に伴う労働力不足は今回考慮していない.
グラフ作成には EXCEL VBA を使った.グラフの各要素を細かく設定することで,データビジュアライゼーションと呼ぶに足るグラフに仕上げることが出来た.
今後の課題としては,プロシージャになるか関数になるかはともかくとして,長大なプロシージャを機能ごとに分割する必要があるだろう.
“今後25年間の日本の都市の将来推計人口を EXCEL VBA で描く” への1件の返信