
Power Query で,あるフォルダ内の同一構造のファイルを一括してインポートする機会は多い.M 言語は未開拓であるが,その一端に触れてみた.
EXCEL ブックであれ csv ファイルであれ,構造化されたデータという観点から見れば,ファイル形式などどうでも良い話である.この抽象化が理解できれば,Power Query への理解が一定程度進むのではないかと思う.
この記事はEXCEL VBA でフォルダ内のブックを開きデータを読み込むと対応する.
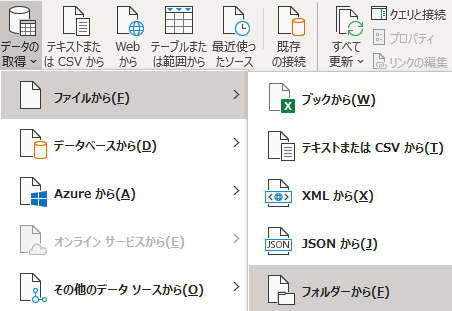
まず「フォルダーパスの指定」
EXCEL であれ Power BI であれ,Power Query エディタの「データの取得」「ファイル」「フォルダ」でフォルダーパスをまず指定する.
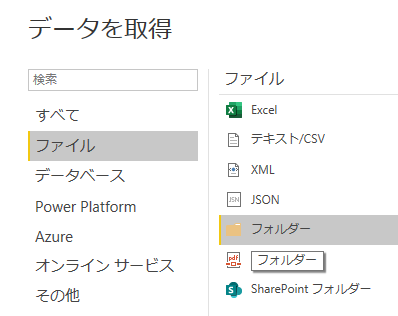
何はともあれ「データの変換」
プレビューでは「データの変換」へと進む.Content, Name, Extension, Date accessed, Date modified, Date created, Attributes, Folder Path の8列がプレビューで表示されている.
Name にフィルターをかける
同一構造のファイルは,ファイル名にも共通点があることが多い.その共通点を含むように,テキストフィルターをかける.その共通点は各自のシステムによって異なるだろうが,何らかの特徴があるはずだ.
M 言語への入り口は「列の追加」
Power Query エディタの最上部に「列の追加」タブがある.「カスタム列」を選ぶ.「カスタム列の式」が M 言語の関数である.「新しい列名」は次の処理ステップで使われる変数名となり,初期値は「カスタム」である.
データ関数はテーブルを返す
ここでソースファイルが csv ファイルか EXCEL のブックかで関数の記述は異なるが,得られる結果はほぼ共通している.ソースファイルが csv ファイルなら csv とタイプするとインテリセンスが働いて自動的に次の候補がポップアップしてくる.この場合 Csv.Document にカーソルが乗った状態でリターンキーを押下する.Excel. とタイプすると Excel.Workbook と続く.他にも Excel.CurrentWorkbook というデータ関数もあるが,違いがよく分からない.
記事公開後,相違について教えてくれた方がいた.感謝したい.
記事の中で出てきたExcel.CurrentWorkbookですが、これは引数なしでExcel.CurrentWorkbook()というように使い、外ではなく今開いているExcelブック自身のテーブルの一覧を持ってくる関数です。画面上だと「テーブルまたは範囲から」で呼ばれる関数ですね。
— Akira Takao (@modernexcel7) 2020年7月15日
これらの関数はデータ関数と呼び,テーブルを返す.関数の種類は数十にも及び,「データの取得」ユーザーインターフェースに使われているデータソースはほぼここから使われている.
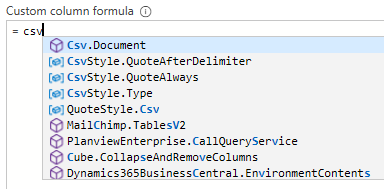
さらに ([ とタイプすると,次の候補がポップアップする.ここでもやはり Attributions, Content, Date accessed, Date created, Date modified, Extension, Folder Path, Name が候補となる.先程フォルダーパスを指定した直後と同様である.
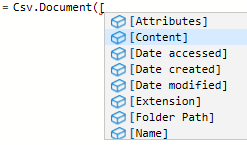
ここで矢印キーで [Content] にカーソルを載せてリターンキーを押下すると Csv.Document([Content] まで入力されるので,) とタイプして関数を閉じる.構文エラーチェックが通ったのを確認して OK をクリックする.
「カスタム列」以外は削除
必要なのはファイル内のデータであるから,「カスタム列」の Table 以外は不要で削除する.
テーブルの展開
カスタム列の右肩に展開アイコンがあるので,クリックする.「展開」「集計」では「展開」がチェックされており,そのまま OK をクリックする.ここで「集計」をチェックするとどうなるかはまだ確認していない.
この後の作業は「1行目をヘッダーとして使用」「列のピボット解除」である.
2件目以降のヘッダーを除外するのを忘れない
忘れがちであるが,複数のファイルを一括インポートすると,2件目以降のファイルの1行目が途中途中で出現する.これをフィルターで除外するのを忘れると,「データ型の変換」あたりか,最後の「閉じて読み込む」あたりで躓くことになる.
課題は PDF
csv ファイルと EXCEL のブックの一括インポートは手順はほぼ同じであるが,PDF ファイルからのインポートが未解決である.Power BI と EXCEL で仕様が異なるらしい.EXCEL だと「その他のソース」「空のクエリ」で指定できるらしいが,まだ取り組めていない.Pdf.Tables 関数は .NET 4.5 が必要なため使用不可となっている.Binary 関数を使用すれば開けるのかも知れない.今後の課題である.
.xls 形式に注意
その後 .xls 形式のファイルをフォルダーごとインポートする機会があったのだが,クエリの検証にやたらと時間がかかる現象が発生した.どうやら古い形式のファイルの取得には時間がかかるものらしい.
xlsだと
— Yt-olt (@olt_yt) 2020年7月8日
シートのデータ、印刷範囲のデータ($’Print_Area)、フィルタの範囲
あたりが別々に読め
そしてxlsxの場合はテーブルのデータが別に読み込めたりします
そして実行読み込み速度は
xlsxのテーブル>>xlsxのそのた>>>xls,xlsb類
だったりします
この問題はいささかトリッキーな方法で回避した.つまり,別のフォルダをソースとして用意しておき,そこに実ファイルを少しコピーしておいてクエリを記述し,最後に読み込む直前にフォルダーパスを本来のパスに書き換える,というものである.
別体で作った軽いテストデータのクエリを作って
— Yt-olt (@olt_yt) 2020年7月8日
Sauceの参照元の書き換えでいじるときだけそっちを読み込むという手はある pic.twitter.com/GgYYDDugCc
テストファイルのパスを後で書き換える、と理解しました
— じふ (@G__Who) 2020年7月8日
やってみます
ありがとうございます
確かに時間はかかるが,クエリのステップごとに検証に時間を取られるよりはマシである..xls 形式の場合は VBA で記述してしまったほうが早いのかもしれない.
powerQueryさんはエラーが出ないように
— Yt-olt (@olt_yt) 2020年7月8日
1手変えるごとにデータをすべて読み込みなおして
全作業の表示結果を再制作してるんです
なので修正時は時間がかかりまして
回避方法は元から読み込みの軽いファイルで作る
という手段になります
“Power Query でフォルダから複数ファイルを一括インポートする” への1件の返信