
EXCEL のワークシートの仕様上,100 万件を超えるデータは扱えない.これは大規模なデータを扱う際の制約である.180万件のデータをPower Queryで処理してEXCELがオーバーフローした話 でも述べたが,この制約を乗り越えてデータをインポートするにはデータモデルに読み込むほかはない.
SQL Server で PowerQuery が使えればこういった制約を回避できるのだが,ないものは仕方がない.今回は PowerPivot を用いてデータモデルに蓄積したデータを取り出す方法を見つけたので備忘録として記す.
謝辞
Twitter のフォロワーの中に EXCEL の達人がいるが,ちょっと困っている旨呟いたらヒントを頂けた.
180万件だとワークシートテーブルではそのまま扱えませんね…Power Pivot アドインが使えるのであれば、Power Pivot管理画面のデータビューから出力できるかもしれませんが、どうですか?
— Akira Takao (@modernexcel7) 2019年11月2日
やってみるとできたので,お礼方々この記事を書くことにした次第である.
Power Query での処理
ピボット解除
「01204旭川市」などのように,市区町村コードと市区町村名が接続された列がピボット解除の対象である.
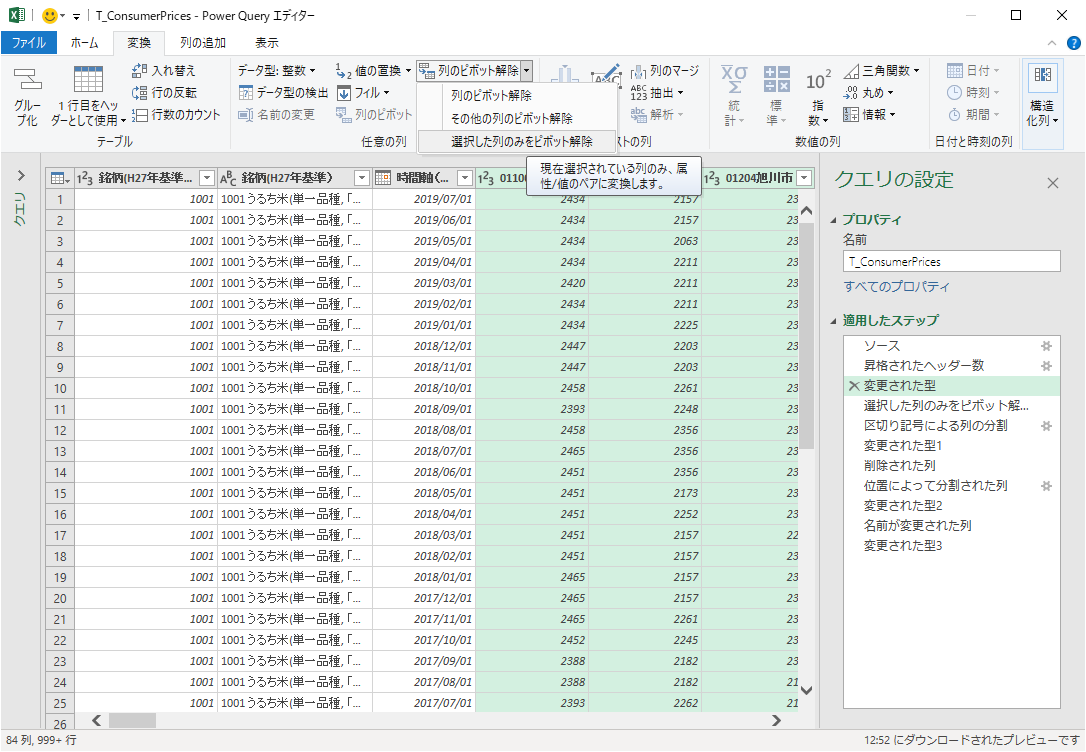
最初に札幌市の列を選択し,シフトキーと右矢印キーを押しっぱなしにして札幌市より右側の列をすべて選択する.
次に「変換」タブの「列のピボット解除」から「選択した列のみをピボット解除」する.
列の分割
「銘柄(平成27年基準)」および「属性」が列分割の対象となる.
区切り記号による分割
「銘柄(平成27年基準)」はスペースを挟んで銘柄コードと銘柄が接続されている.これを分割したい.
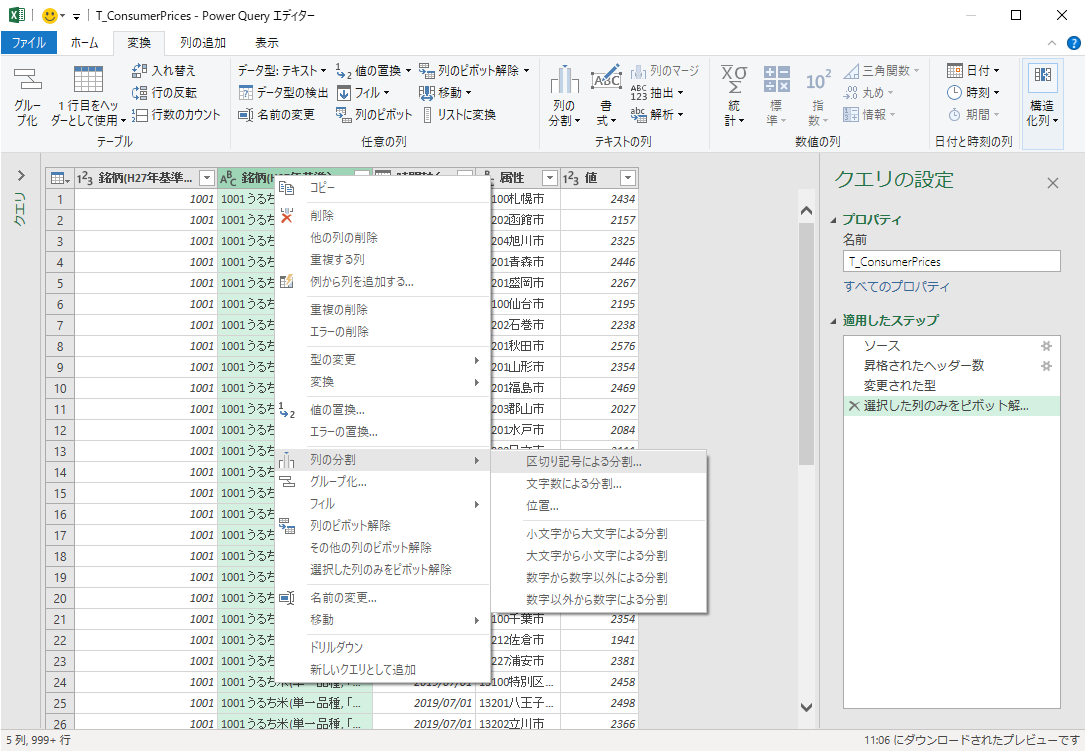
「区切り記号」はスペースがデフォルトである.「分割」は「一番左の区切り記号」をチェックする.詳細設定オプションは今回使用しない.
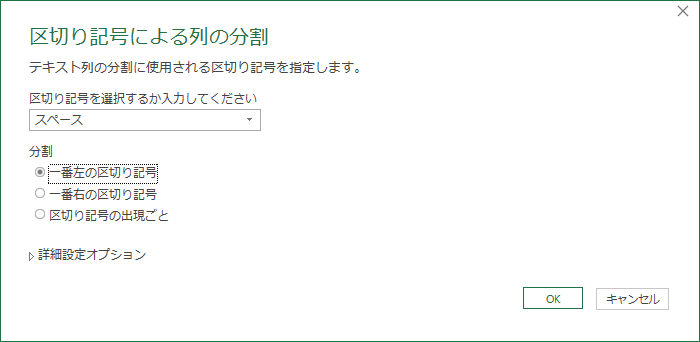
「銘柄1」という列ができるが,今回は不要であり「削除」する.
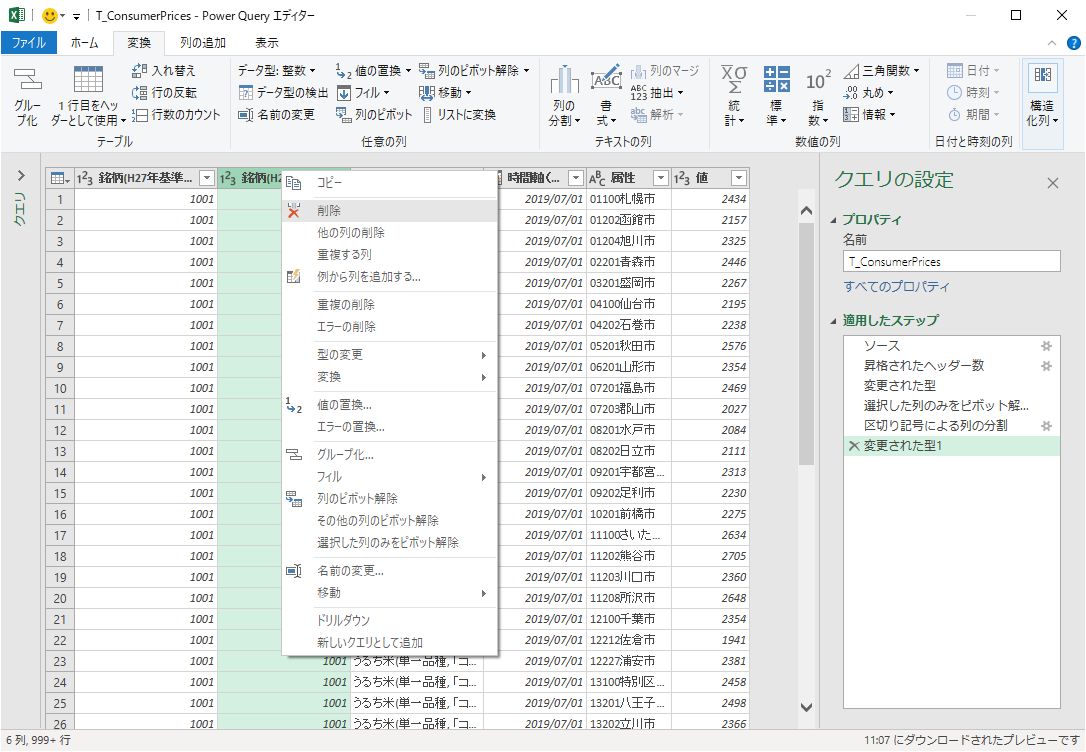
文字数による分割
「属性」は市区町村コードと市区町村が接続されており,これを分割したい.
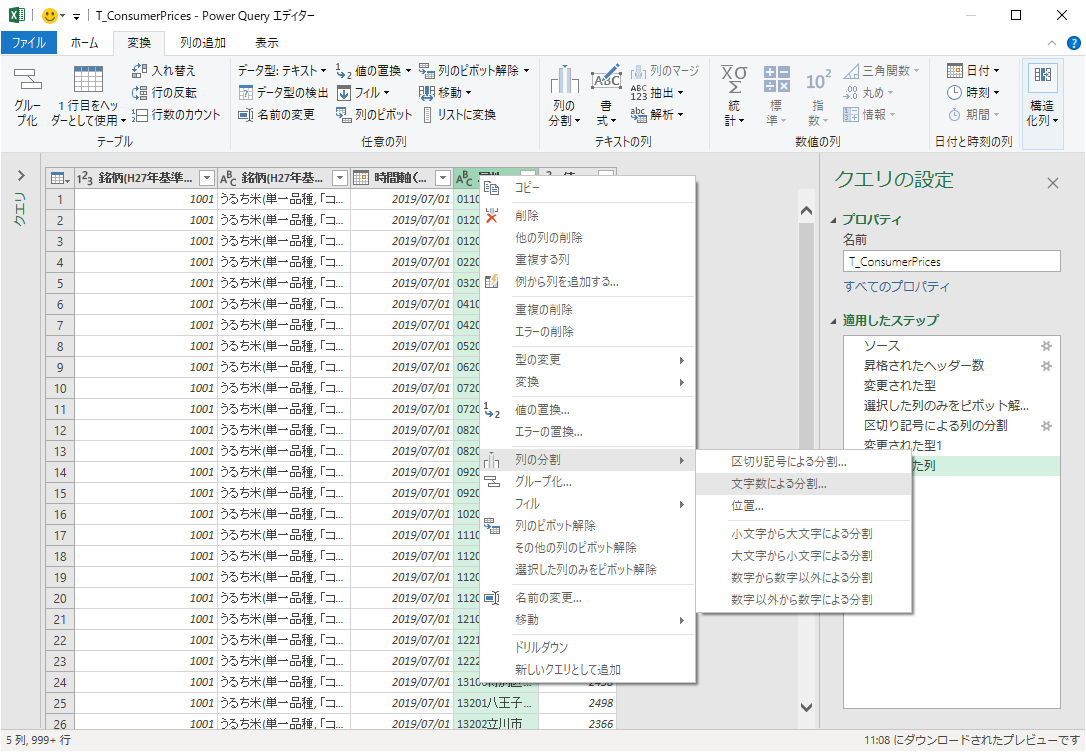
「文字数」は市区町村コードの列長の 5 とし,「分割」は「できるだけ左側で1回」をチェックする.詳細設定オプションは使わない.
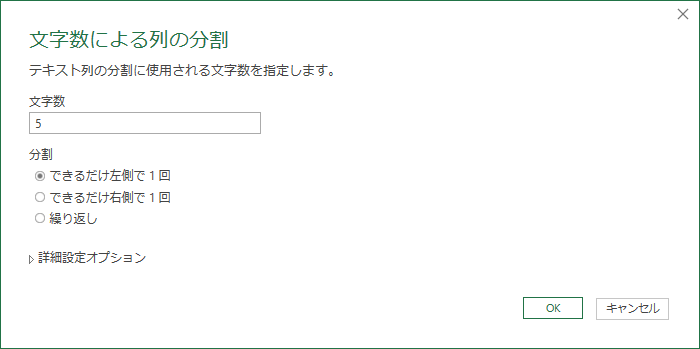
データ型の変更履歴を削除
Power Query のおせっかい機能の一つにデータ型を勝手に変換する機能がある.右側のパネルに「適用したステップ」があるが,市区町村コードが数値型に変更されている.これは不要なステップなので削除して履歴を一つ戻す.
列名の変更
SQL Server にインポートする際には列名を英語に直したほうがよい.
| 旧列名 | 新列名 |
|---|---|
| 銘柄(平成27年基準)コード | ItemCode |
| 銘柄(平成27年基準) | Item |
| 時間軸 | Date |
| 属性1 | CityCode |
| 属性2 | City |
| 値 | Price |
オーバーフローへの対処は「データモデル」
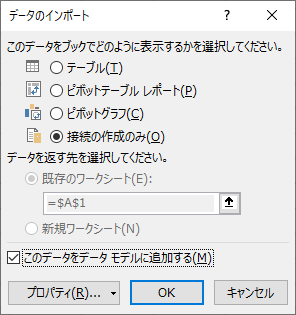
例によって 100 万件超えのデータはオーバーフローするので,「読み込み先…」から「データのインポート」を開き,「接続の作成のみ」をチェックし,「このデータをデータモデルに追加する」にチェックを入れる.
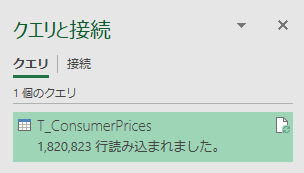
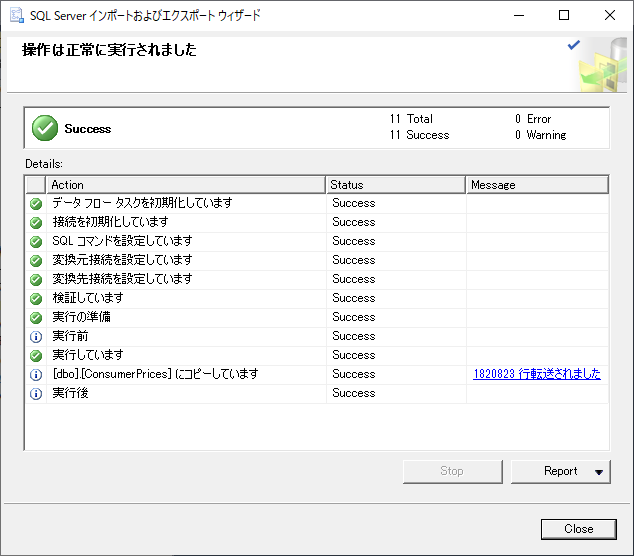
「クエリと接続」で読み込んだデータ件数がカウントアップされ,最終的に下図のように 1,820,823 件が読み込まれた.
DAX式 M 言語
DAX 式 M 言語は下図のとおりである.
let
ソース = Csv.Document(File.Contents("C:\Users\****\Dropbox\20190908BLOG\T_ConsumerPrices.txt"),[Delimiter=" ", Columns=84, Encoding=932, QuoteStyle=QuoteStyle.None]),
昇格されたヘッダー数 = Table.PromoteHeaders(ソース, [PromoteAllScalars=true]),
変更された型 = Table.TransformColumnTypes(昇格されたヘッダー数,{{"銘柄(H27年基準) コード", Int64.Type}, {"銘柄(H27年基準)", type text}, {"時間軸(月)", type date}, {"01100札幌市", Int64.Type}, {"01202函館市", Int64.Type}, {"01204旭川市", Int64.Type}, {"02201青森市", Int64.Type}, {"03201盛岡市", Int64.Type}, {"04100仙台市", Int64.Type}, {"04202石巻市", Int64.Type}, {"05201秋田市", Int64.Type}, {"06201山形市", Int64.Type}, {"07201福島市", Int64.Type}, {"07203郡山市", Int64.Type}, {"08201水戸市", Int64.Type}, {"08202日立市", Int64.Type}, {"09201宇都宮市", Int64.Type}, {"09202足利市", Int64.Type}, {"10201前橋市", Int64.Type}, {"11100さいたま市", Int64.Type}, {"11202熊谷市", Int64.Type}, {"11203川口市", Int64.Type}, {"11208所沢市", Int64.Type}, {"12100千葉市", Int64.Type}, {"12212佐倉市", Int64.Type}, {"12227浦安市", Int64.Type}, {"13100特別区部", Int64.Type}, {"13201八王子市", Int64.Type}, {"13202立川市", Int64.Type}, {"13206府中市", Int64.Type}, {"14100横浜市", Int64.Type}, {"14130川崎市", Int64.Type}, {"14150相模原市", Int64.Type}, {"14201横須賀市", Int64.Type}, {"15100新潟市", Int64.Type}, {"15202長岡市", Int64.Type}, {"16201富山市", Int64.Type}, {"17201金沢市", Int64.Type}, {"18201福井市", Int64.Type}, {"19201甲府市", Int64.Type}, {"20201長野市", Int64.Type}, {"20202松本市", Int64.Type}, {"21201岐阜市", Int64.Type}, {"22100静岡市", Int64.Type}, {"22130浜松市", Int64.Type}, {"22210富士市", Int64.Type}, {"23100名古屋市", Int64.Type}, {"23201豊橋市", Int64.Type}, {"24201津市", Int64.Type}, {"24204松阪市", Int64.Type}, {"25201大津市", Int64.Type}, {"26100京都市", Int64.Type}, {"27100大阪市", Int64.Type}, {"27140堺市", Int64.Type}, {"27210枚方市", Int64.Type}, {"27227東大阪市", Int64.Type}, {"28100神戸市", Int64.Type}, {"28201姫路市", Int64.Type}, {"28204西宮市", Int64.Type}, {"28207伊丹市", Int64.Type}, {"29201奈良市", Int64.Type}, {"30201和歌山市", Int64.Type}, {"31201鳥取市", Int64.Type}, {"32201松江市", Int64.Type}, {"33100岡山市", Int64.Type}, {"34100広島市", Int64.Type}, {"34207福山市", Int64.Type}, {"35202宇部市", Int64.Type}, {"35203山口市", Int64.Type}, {"36201徳島市", Int64.Type}, {"37201高松市", Int64.Type}, {"38201松山市", Int64.Type}, {"38202今治市", Int64.Type}, {"39201高知市", Int64.Type}, {"40100北九州市", Int64.Type}, {"40130福岡市", Int64.Type}, {"41201佐賀市", Int64.Type}, {"42201長崎市", Int64.Type}, {"42202佐世保市", Int64.Type}, {"43100熊本市", Int64.Type}, {"44201大分市", Int64.Type}, {"45201宮崎市", Int64.Type}, {"46201鹿児島市", Int64.Type}, {"47201那覇市", Int64.Type}}),
選択した列のみをピボット解除しました = Table.Unpivot(変更された型, {"01100札幌市", "01202函館市", "01204旭川市", "02201青森市", "03201盛岡市", "04100仙台市", "04202石巻市", "05201秋田市", "06201山形市", "07201福島市", "07203郡山市", "08201水戸市", "08202日立市", "09201宇都宮市", "09202足利市", "10201前橋市", "11100さいたま市", "11202熊谷市", "11203川口市", "11208所沢市", "12100千葉市", "12212佐倉市", "12227浦安市", "13100特別区部", "13201八王子市", "13202立川市", "13206府中市", "14100横浜市", "14130川崎市", "14150相模原市", "14201横須賀市", "15100新潟市", "15202長岡市", "16201富山市", "17201金沢市", "18201福井市", "19201甲府市", "20201長野市", "20202松本市", "21201岐阜市", "22100静岡市", "22130浜松市", "22210富士市", "23100名古屋市", "23201豊橋市", "24201津市", "24204松阪市", "25201大津市", "26100京都市", "27100大阪市", "27140堺市", "27210枚方市", "27227東大阪市", "28100神戸市", "28201姫路市", "28204西宮市", "28207伊丹市", "29201奈良市", "30201和歌山市", "31201鳥取市", "32201松江市", "33100岡山市", "34100広島市", "34207福山市", "35202宇部市", "35203山口市", "36201徳島市", "37201高松市", "38201松山市", "38202今治市", "39201高知市", "40100北九州市", "40130福岡市", "41201佐賀市", "42201長崎市", "42202佐世保市", "43100熊本市", "44201大分市", "45201宮崎市", "46201鹿児島市", "47201那覇市"}, "属性", "値"),
区切り記号による列の分割 = Table.SplitColumn(選択した列のみをピボット解除しました, "銘柄(H27年基準)", Splitter.SplitTextByEachDelimiter({" "}, QuoteStyle.Csv, false), {"銘柄(H27年基準).1", "銘柄(H27年基準).2"}),
変更された型1 = Table.TransformColumnTypes(区切り記号による列の分割,{{"銘柄(H27年基準).1", Int64.Type}, {"銘柄(H27年基準).2", type text}}),
削除された列 = Table.RemoveColumns(変更された型1,{"銘柄(H27年基準).1"}),
位置によって分割された列 = Table.SplitColumn(削除された列, "属性", Splitter.SplitTextByPositions({0, 5}, false), {"属性.1", "属性.2"}),
変更された型2 = Table.TransformColumnTypes(位置によって分割された列,{{"銘柄(H27年基準) コード", type text}}),
#"名前が変更された列 " = Table.RenameColumns(変更された型2,{{"銘柄(H27年基準) コード", "ItemCode"}, {"銘柄(H27年基準).2", "Item"}, {"時間軸(月)", "Date"}, {"属性.1", "CityCode"}, {"属性.2", "City"}, {"値", "Price"}}),
変更された型3 = Table.TransformColumnTypes(#"名前が変更された列 ",{{"ItemCode", Int64.Type}})
in
変更された型3
PowerPivot の有効化
EXCEL の「ファイル」メニュー下部に「オプション」があるのでクリックする.

EXCEL のオプション左パネルの「アドイン」をクリックする.
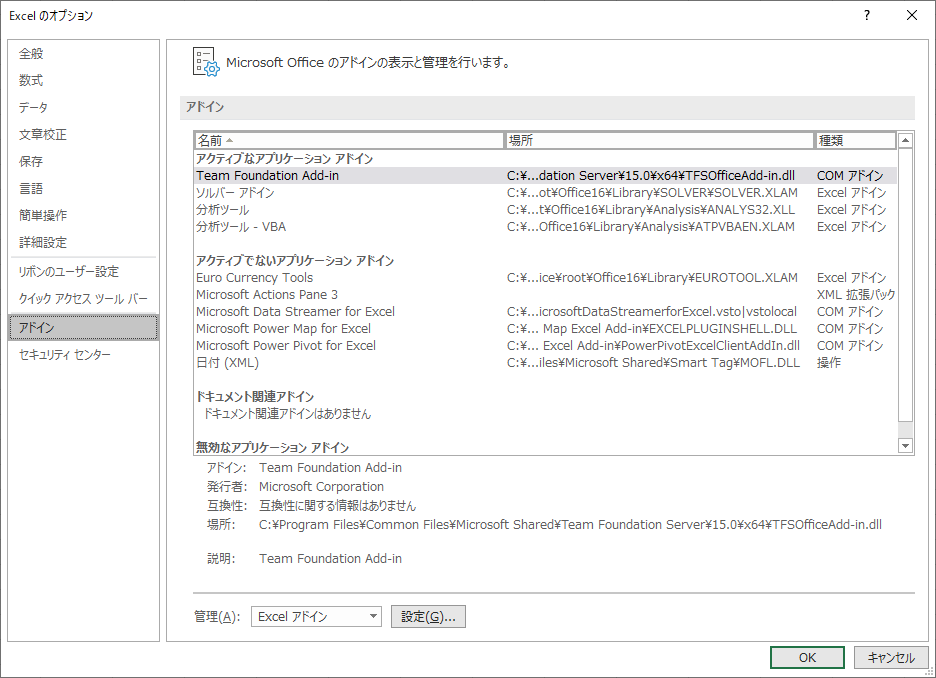
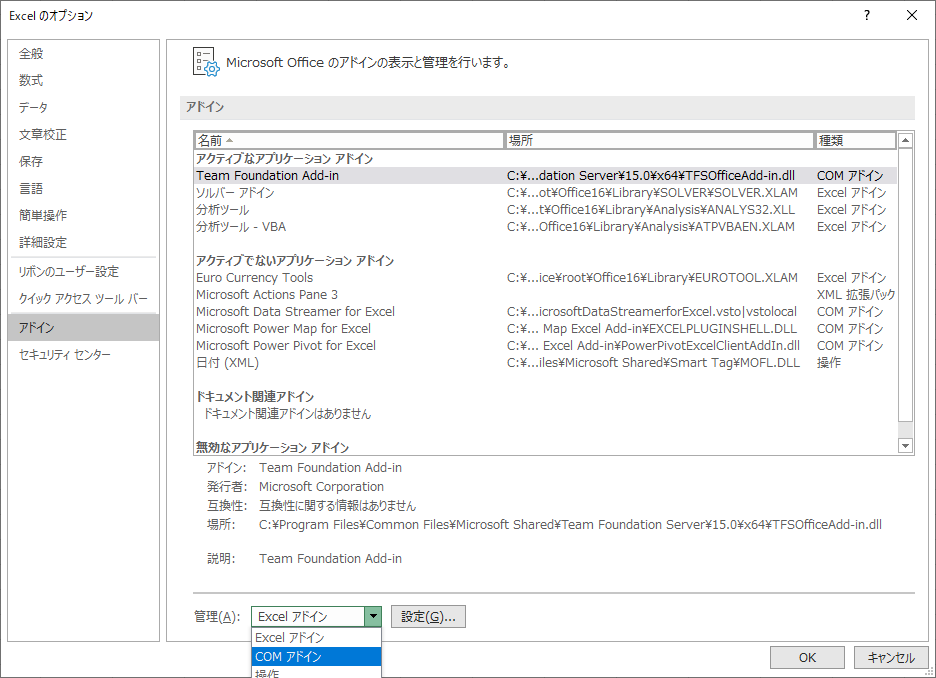
「管理」から「COMアドイン」を選択して「設定…」ボタンをクリックする.
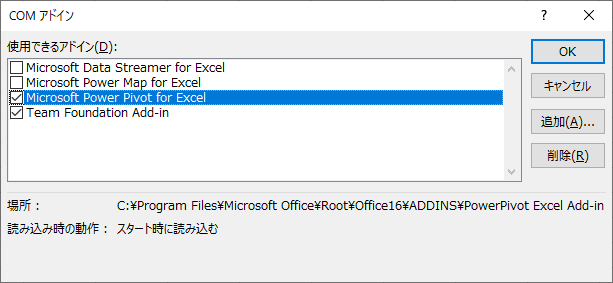
Microsoft Power Pivot for Excel にチェックを入れて OK をクリックする.
メニューに Power Pivot が現れる.「データモデル」の「管理」をクリックする.

ItemCode のデータ型が数値でないといけない理由
数値フィルターのクエリで「次の値の間」を選択できるようにするため,ItemCode のデータ型は数値型でないといけない.文字列型だと完全一致しか選択できず,次の操作に支障が出る.
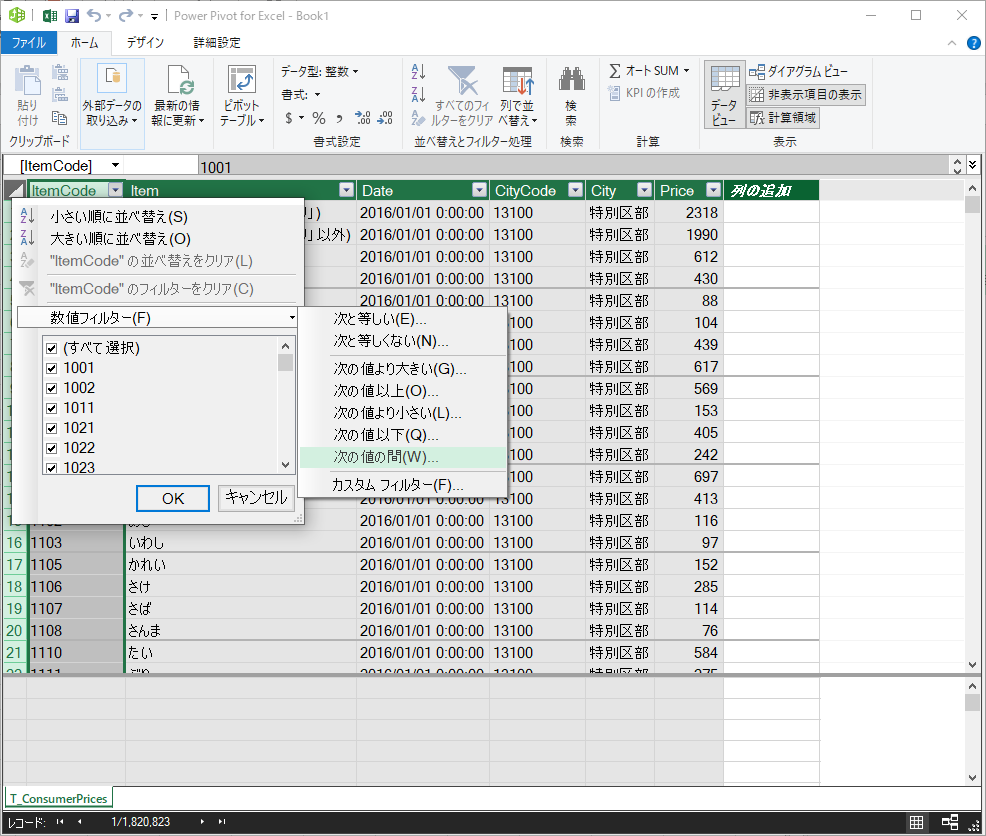
カスタムフィルター
ItemCode に数値フィルターを適用するのは,コピーできるデータ件数にはメモリ上の制限があって,すべてのデータを一度にコピーすることができないためである.

下図のように SQL で言うところの BETWEEN 句に該当するクエリを指定する.
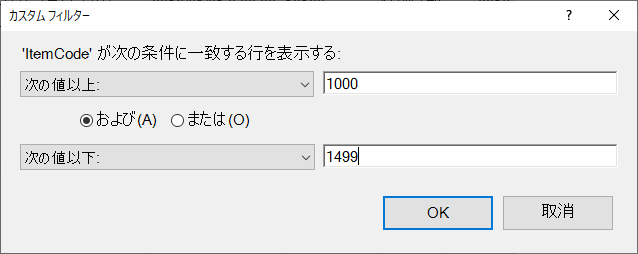
すべてを選択してコピー
セル範囲の左上のマークをクリックしてすべて選択し,右クリックして「コピー」する.
メモ帳に貼り付け
メモ帳を起動して貼り付ける.もっとも,40万件ものデータをクリップボード経由でペーストすることはできず,端末はしばらく黙り込んだ後,何事もなかったかのように無視されてしまう.件数が多すぎたのだ.
クエリを変更して件数を絞り込む.20万件くらいに絞り込むとクリップボード経由で貼り付けできるようだ.
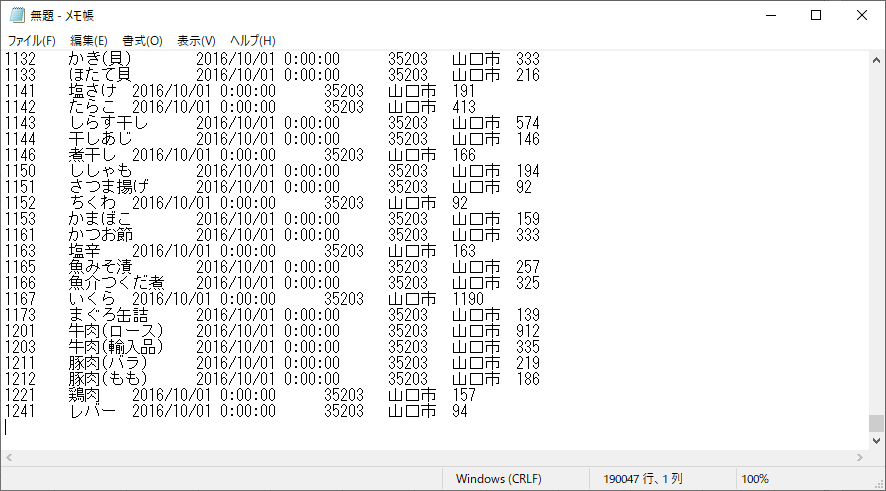
ヘッダー付きでコピーされている
下図はすべてのデータを貼り付け終えたところである.蛍光マーカーで強調したところをよく見てほしい.データ件数が実際よりも多くなっている.
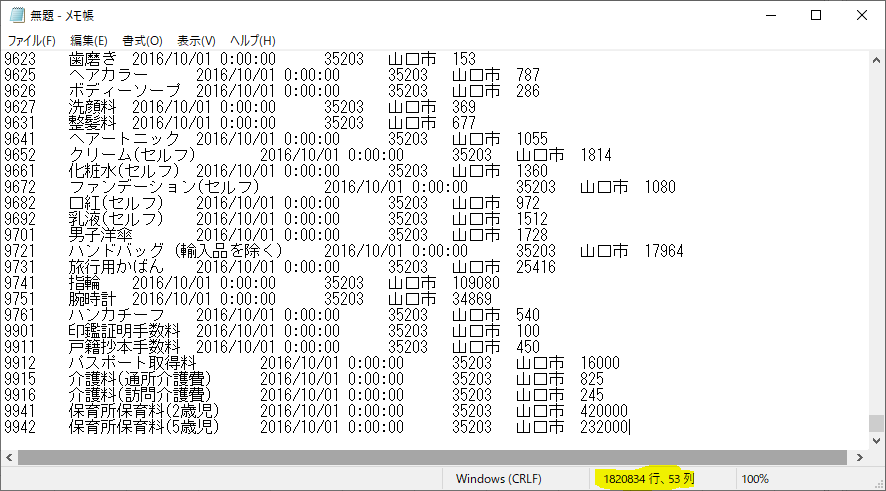
この差分はヘッダー行である.貼り付けた回数分だけ多くなっている.後で SQL Server にインポートする際に邪魔になるので,ここで削除しておこう.
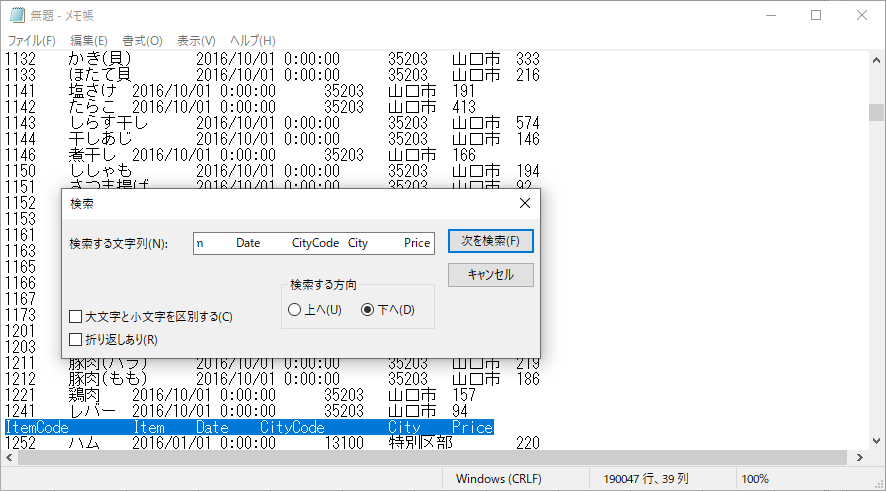
Delete キーを押すこと十数回で余計なヘッダーが削除できる.ファイル名をつけて保存しよう.ここでは ConsumerPrices.txt としておく.
SQL Server にインポート
データベースを右クリックして「データのインポート」
よく間違えるのだが,直上の「フラットファイルのインポート」ではない.ウィザードのデータソースで Flat File Source を選択する.
ウィザードの注意点
何度かインポートに失敗していくうちに,どこで失敗するか見えてくる.今回はヘッダー行を削除し忘れたのと,データの切り捨てが発生していたことである.
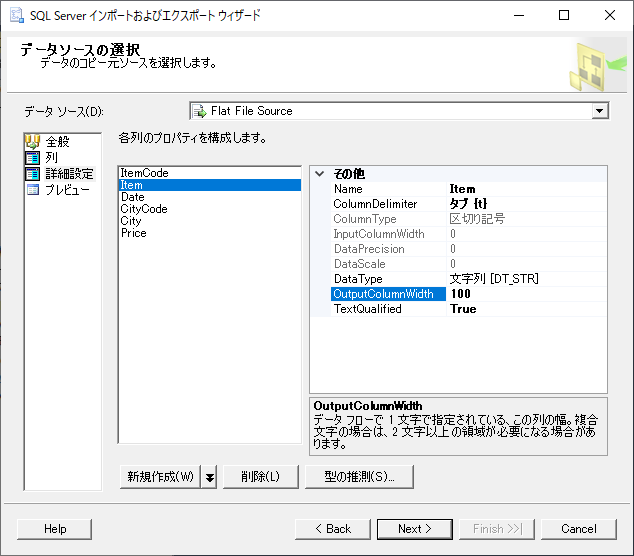
データの切り捨ては詳細設定で修正する
データソースを指定した後,左側のパネルで「詳細設定」を選ぶ.Item を選ぶと OutputColumnWidth という項目がある.ここで入力側のフィルタリングを行っているらしい.デフォルトは 50 だが,100 にするとエラーが止まる.
列マッピングは最重要項目
とにもかくにも,インポートにおいてはここが最も重要である.データ型,データ長,NULL の可否を決める.
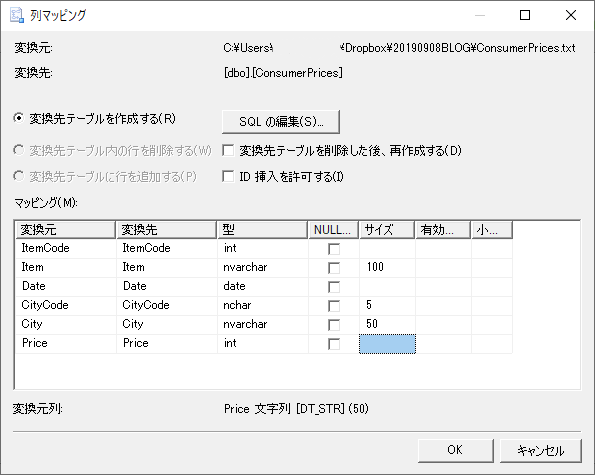
何度かトライアンドエラーを繰り返し,インポートは正常に終了した.
まとめ
100 万件を超えるデータを EXCEL のデータモデルから取り出す方法を公開した.EXCEL 側では Power Pivot が必須であり,メモ帳や SQL Server も必要であった.
手動でクリップボード経由のコピペというのが課題であり,他にスマートな方法が存在するなら知りたい.
Power Queryについて書かれている数少ない貴重なブログですので、ぜひとも頑張ってください!
ブログを検索していたらPower Queryについて書かれているここに辿り着きました。2点ほどコメントがあります。まず、Power Queryの言語はDAXではなく、M言語です。DAXはPower PivotやPower BIのネイティブ言語で、Excel関数のステロイド版のイメージですが、両者はまったく異なる存在です。もう一つは、Power Pivotからデータを抽出する場合、DAX Studioというツールを使えば簡単にできますので、調べてみてください。このツールであれば、Power Pivot内のすべてのテーブルを一括で出力できたりします。確か”180万件のデータをPower Queryで処理してEXCELがオーバーフローした話”のほうでもM言語をDAXと間違って記載されていたようですので、ご確認ください。
https://docs.microsoft.com/ja-jp/powerquery-m/
有益なコメントありがとうございます.
M 言語が正式名称とのご指摘,ありがとうございます.また DAX Studio のご紹介もありがとうございます.
調べてみます.ありがとうございました.