
総務省統計ポータル e-Stat からのデータに全国の市区町村の人口推移があった.マーク・ブキャナンの「歴史はべき乗則で動く」の p 261 に「人口が半分の都市は四つある」とある.本当だろうか.検証してみた.
人口データのダウンロード
データベースは総務省の e-Stat である.あまり巨大なデータをダウンロードしようとするとエラーが発生するため,程々にしておく必要がある.
トップページから「地域」へ
e-Statトップページ.「統計データを活用する」の「地域」をクリックする.

「市区町村データ」の「データ表示」へ
「都道府県・市区町村のすがた(社会・人口統計体系)」から「市区町村データ」と「データ表示」をクリックする.
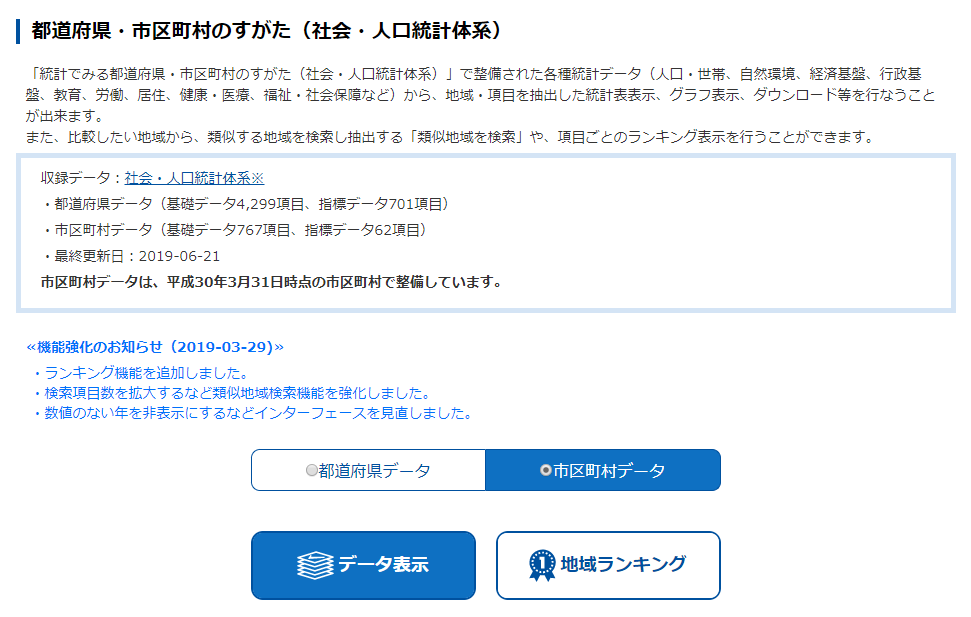
地域選択の絞り込みは「現在の市区町村」
「地域選択」の「1絞り込み」で「表示データ」は「現在の市区町村」,「地域区分」は都道府県の「すべて」,「絞り込み」はデフォルトのまま.「2地域候補」から「全て選択」をクリックする.
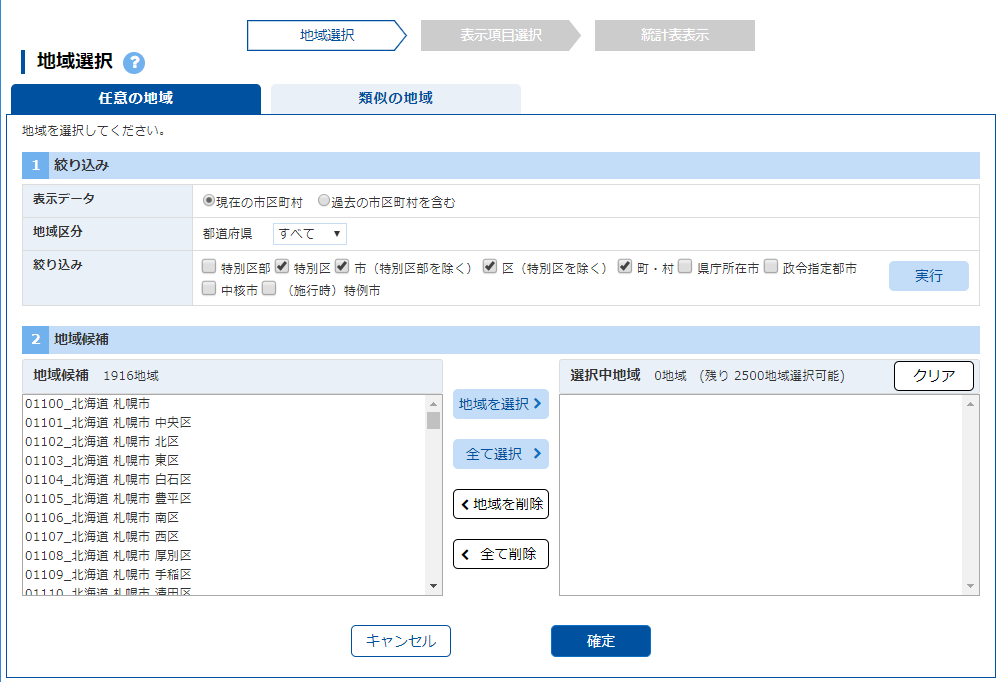
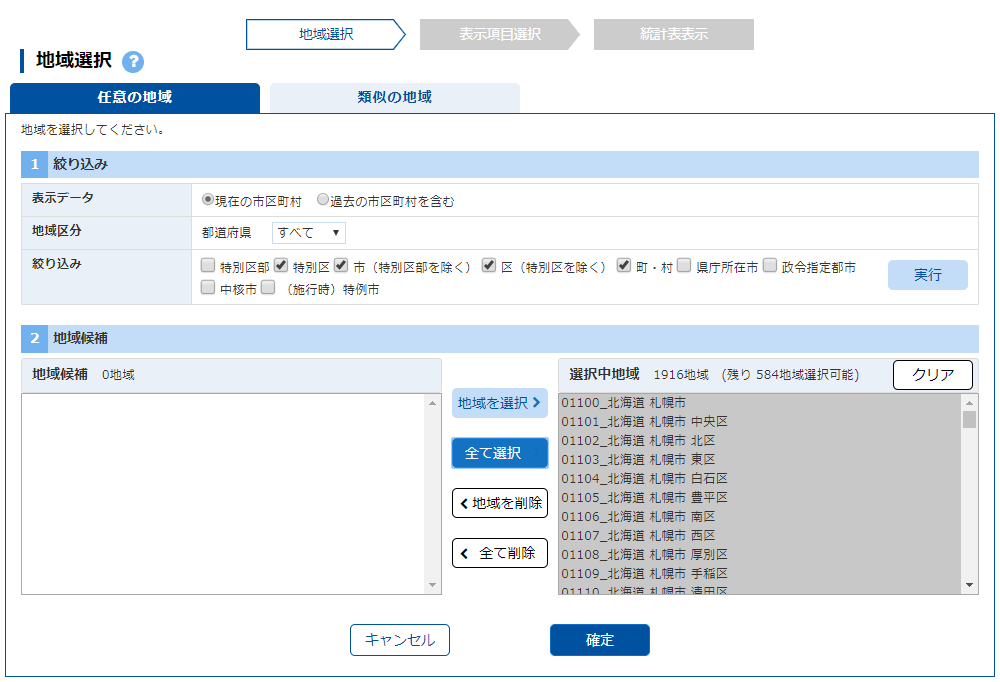
地域候補は「すべて選択」
市区町村は「すべて選択」である.不要なものは後から削除する.
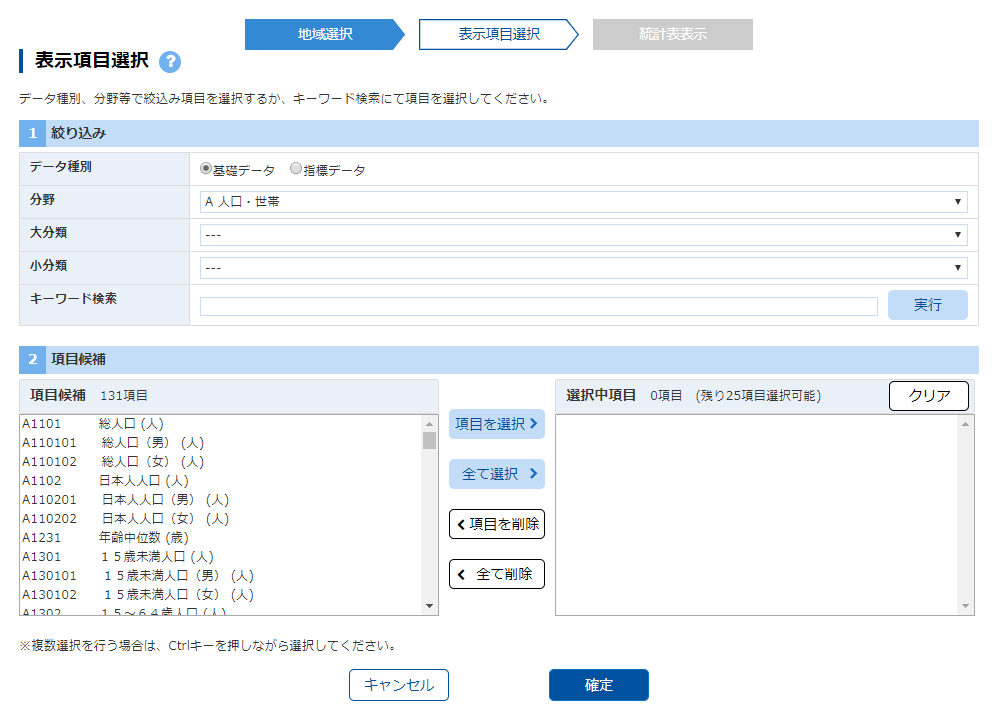
表示項目選択の絞り込み
よく見ないと見落とすが,「データ種別」には基礎データと指標データがある.格納されているテーブルが違うのだろう.
データの項目を決める.本来なら総人口,年少人口,生産年齢人口,老年人口,出生数,死亡数,転入者数,転出者数すべてほしい.

基礎データ,指標データそれぞれの分野は「A人口・世帯」
「指標データ」に切り替えて人口増減率,転入率,転出率を選択する.
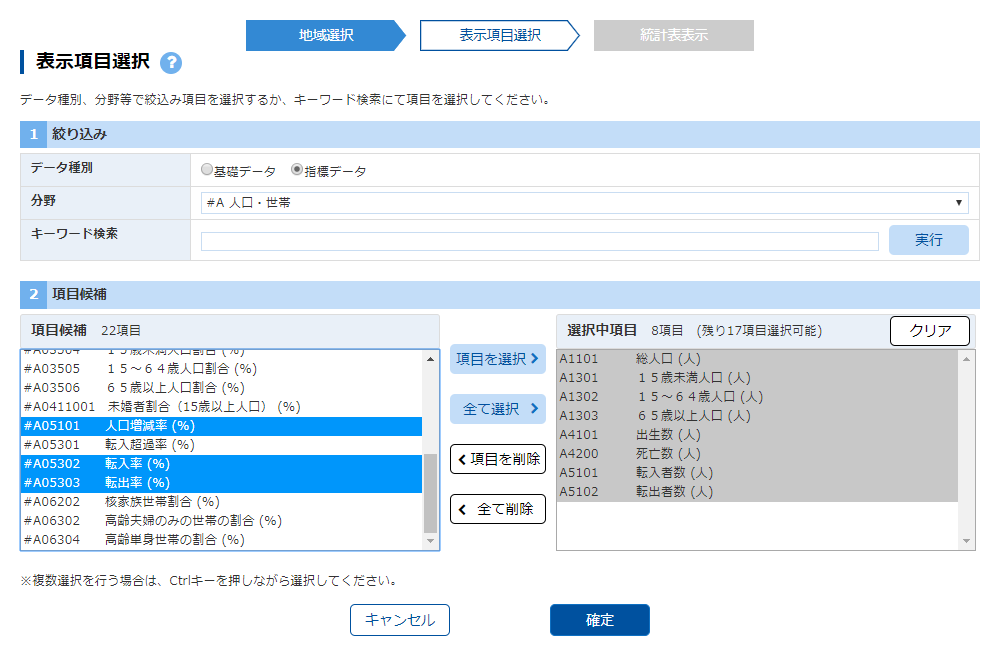
確定をクリック
確定をクリックすると画面にデータが表示される.右上に「ダウンロード」ボタンがあるのでクリックする.

ファイル形式など決める
ファイル形式は「XLSX 形式」に変更し,チェックを外したり付け替えたりする.「ダウンロード」をクリックする.
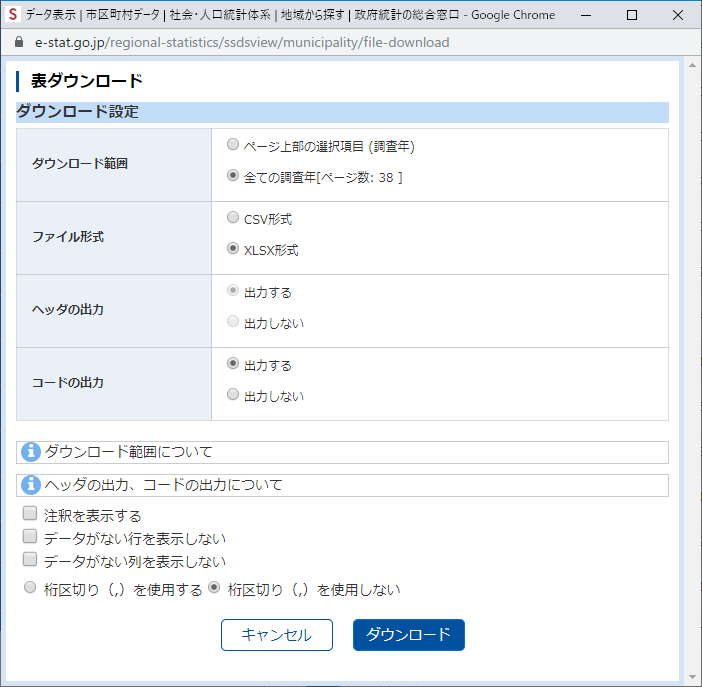
ファイル容量が大きすぎるためか,失敗する.
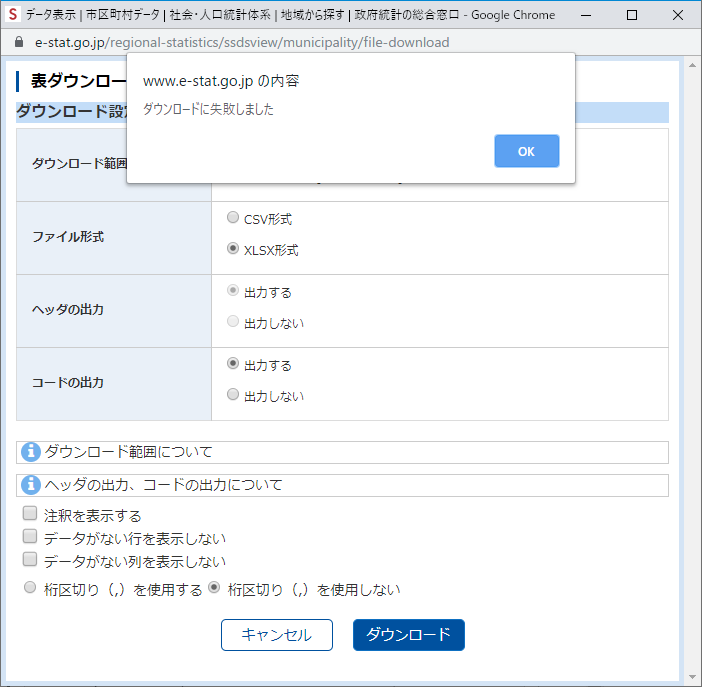
なぜか CSV 形式だとうまく行く
何度か項目を減らしたりして試行錯誤していたが,結局 csv ファイル形式にすると失敗しないようだ.EXCEL に変換するところでエラーが発生しているのかもしれない.
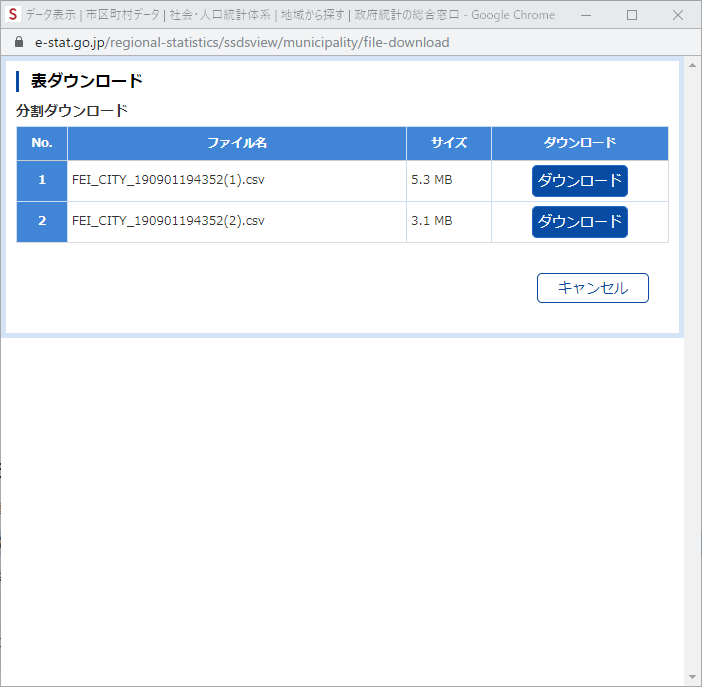
データクレンジング
EXCELで開く
ダウンロードした csv ファイルを EXCEL で開く.二つに分割されており,1つ目のファイルは 45,463 行目で切られている.2つ目のファイルはその続きからのようだ.
コピペでデータを統合する
ファイルが 2 つだけで,ワークシートも 1 枚しかないので手動でコピペしたほうが早い.別名で保存で EXCEL マクロ有効ブック (“.xlsm) にする.ファイル名を「市区町村人口動態」としよう.
不要な列を削除
1 – 8 行目が不要だ.削除する.
テーブルの挿入
「挿入」タブから「テーブル」をクリックしてテーブルを作成する.
タイトルの編集
タイトルはデータベースのドメインでもある.重複しないような項目名にしたい.できれば日本語は避けたい.
ぱっと見て,「調査年コード」は不要と分かるので削除する.「/項目」も空欄しかないが,これは後で別の項目に書き換えるために残しておく.
以下,タイトル編集前後を表形式で記しておく.
| 編集前タイトル | 編集後タイトル |
|---|---|
| 調査年コード | (削除) |
| 調査年 | YEAR |
| 地域 コード | CityCode |
| 地域 | City |
| /項目 | PrefectureCode |
| Prefecture | |
| Region | |
| A1101_総人口【人】 | TotalPopulation |
| A1301_15歳未満人口【人】 | YoungPopulation |
| A1302_15~64歳人口【人】 | WorkingPopulation |
| A1303_65歳以上人口【人】 | ElderPopulation |
| A4101_出生数【人】 | Birth |
| A4200_死亡数【人】 | Death |
| A5101_転入者数【人】 | MoveIn |
| A5102_転出者数【人】 | MoveOut |
| #A05101_人口増減率【%】 | PopulationChangeRate |
| #A05302_転入率【%】 | MoveInRate |
| #A05303_転出率【%】 | MoveOutRate |
レコードの追加・削除・編集
「調査年」が先頭に来た.データを見ていると「年度」の文字が不要だ.検索と置換で一括削除しよう.
都道府県コードと都道府県名,地方区分の追加
市区町村名 (City) の右側 3 列が空いている.都道府県コード (PrefectureCode), 都道府県 (Prefecture), 地方区分 (Region) である.
都道府県コードと都道府県はそれぞれワークシート関数で抽出できる.地方区分は手作業になる.
=LEFT([@CityCode], LEN([@CityCode])-3)
=LEFT([@City], FIND(" ",[@City])-1)
最後にコピーして「値の貼り付け」を忘れずに.
地方区分
地方区分にもいくつかの分類があるが,一般には下表のような区分になると思われる.
| 都道府県コード | 都道府県 | 地方区分 |
|---|---|---|
| 01000 | 北海道 | 北海道地方 |
| 02000 | 青森県 | 東北地方 |
| 03000 | 岩手県 | 東北地方 |
| 04000 | 宮城県 | 東北地方 |
| 05000 | 秋田県 | 東北地方 |
| 06000 | 山形県 | 東北地方 |
| 07000 | 福島県 | 東北地方 |
| 08000 | 茨城県 | 関東地方 |
| 09000 | 栃木県 | 関東地方 |
| 10000 | 群馬県 | 関東地方 |
| 11000 | 埼玉県 | 関東地方 |
| 12000 | 千葉県 | 関東地方 |
| 13000 | 東京都 | 関東地方 |
| 14000 | 神奈川県 | 関東地方 |
| 15000 | 新潟県 | 中部地方 |
| 16000 | 富山県 | 中部地方 |
| 17000 | 石川県 | 中部地方 |
| 18000 | 福井県 | 中部地方 |
| 19000 | 山梨県 | 中部地方 |
| 20000 | 長野県 | 中部地方 |
| 21000 | 岐阜県 | 中部地方 |
| 22000 | 静岡県 | 中部地方 |
| 23000 | 愛知県 | 中部地方 |
| 24000 | 三重県 | 近畿地方 |
| 25000 | 滋賀県 | 近畿地方 |
| 26000 | 京都府 | 近畿地方 |
| 27000 | 大阪府 | 近畿地方 |
| 28000 | 兵庫県 | 近畿地方 |
| 29000 | 奈良県 | 近畿地方 |
| 30000 | 和歌山県 | 近畿地方 |
| 31000 | 鳥取県 | 中国地方 |
| 32000 | 島根県 | 中国地方 |
| 33000 | 岡山県 | 中国地方 |
| 34000 | 広島県 | 中国地方 |
| 35000 | 山口県 | 中国地方 |
| 36000 | 徳島県 | 四国地方 |
| 37000 | 香川県 | 四国地方 |
| 38000 | 愛媛県 | 四国地方 |
| 39000 | 高知県 | 四国地方 |
| 40000 | 福岡県 | 九州・沖縄地方 |
| 41000 | 佐賀県 | 九州・沖縄地方 |
| 42000 | 長崎県 | 九州・沖縄地方 |
| 43000 | 熊本県 | 九州・沖縄地方 |
| 44000 | 大分県 | 九州・沖縄地方 |
| 45000 | 宮崎県 | 九州・沖縄地方 |
| 46000 | 鹿児島県 | 九州・沖縄地方 |
| 47000 | 沖縄県 | 九州・沖縄地方 |
完全なデータセットのないレコードは削除する
データベースにとって NULL は最大の敵である.国勢調査などの統計も一つ一つは信頼できるが,それらを組み合わせたデータセットは完全ではないかもしれない.何より,e-Stat のデータベースは完全外部結合によりデータセットを都度作成している可能性が高い.
ここでは,完全なデータセットのないレコードは削除する,という最も厳格な方針を貫くことにする.
具体的には,値のない行はすべて削除する,である.実際には EXCEL のテーブルに標準装備されたフィルターを使う.
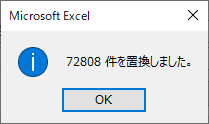
TotalPopulation 列のフィルターに ~* とタイプすると,アスタリスクの入った行が抽出される.実に 72,808 レコード中 57,503 レコードである.まず,これらを削除する.フィルターを解除すると残ったのは 15,305 レコードである.
同じ TotalPopulation 列のフィルターに – とタイプすると 303 レコードが抽出される.これらも削除する.
このような作業を YoungPopulation, WorkingPopulation, ElderPopulation, Birth, Death, MoveIn, MoveOut, PopulationChangeRate, MoveInRate, MoveOutRate のすべての列で繰り返す.
Birth で 5,562 レコード,MoveIn で 1,868 レコード,MoveOut で 230 レコード,PopulationChangeRate で 43 レコード,MoveInRate で 5 レコード,合計で 65,514 レコード削除した.
残ったのはたった 7,294 レコードである.最初 72,808 もあったのが 10 分の 1 に減ってしまった計算だ.しかし,これで良い.
YEAR の列を見てみると, 2000 年, 2005 年, 2010 年, 2015 年のレコードしか残っていない.
YEAR, CityCode で昇順ソートする
年と市区町村コードそれぞれを昇順でソートする.2005 年のレコードが抜けているのは北海道のみである.何か事情があったのかもしれない.
SQL Server にインポート
なぜデータベースが必要になるのか?単に軸のオプション設定を対数表記にすればよいのでは?と思うかもしれない.
理由は EXCEL では横軸を対数表記にした区間集計の棒グラフの作成が難しいからである.できないことはないが,テーブルに分類用の作業列を追加する必要がある.しかし,データベース側でデータを集計する方が簡単である.
ここでの目的は「人口を,べき乗数を 10 等分した区間ごとに集計を行う」ことである.意味が分からないって?では下記リストを見てほしい.^ の演算記号はべき乗を示している.
| 定義 | 下限 | 上限 | 数値下限 | 数値上限 |
|---|---|---|---|---|
| 1万人未満 | 10^4.0 | 10,000 | ||
| 10^4.0 | 10^4.1 | 10,000 | 12,589 | |
| 10^4.1 | 10^4.2 | 12,589 | 15,849 | |
| 10^4.2 | 10^4.3 | 15,849 | 19,953 | |
| 10^4.3 | 10^4.4 | 19,953 | 25,119 | |
| 10^4.4 | 10^4.5 | 25,119 | 31,623 | |
| 10^4.5 | 10^4.6 | 31,623 | 39,811 | |
| 10^4.6 | 10^4.7 | 39,811 | 50,119 | |
| 10^4.7 | 10^4.8 | 50,119 | 63,096 | |
| 10^4.8 | 10^4.9 | 63,096 | 79,433 | |
| 10万人未満 | 10^4.9 | 10^5.0 | 79,433 | 100,000 |
| 10^5.0 | 10^5.1 | 100,000 | 125,893 | |
| 10^5.1 | 10^5.2 | 125,893 | 158,489 | |
| 10^5.2 | 10^5.3 | 158,489 | 199,526 | |
| 10^5.3 | 10^5.4 | 199,526 | 251,189 | |
| 10^5.5 | 10^5.5 | 251,189 | 316,228 | |
| 10^5.5 | 10^5.6 | 316,228 | 398,107 | |
| 10^5.6 | 10^5.7 | 398,107 | 501,187 | |
| 10^5.7 | 10^5.8 | 501,187 | 630,957 | |
| 10^5.8 | 10^5.9 | 630,957 | 794,328 | |
| 100万人未満 | 10^5.9 | 10^6.0 | 794,328 | 1,000,000 |
| 100万人以上 | 10^6.0 | 1,000,000 |
こういう区間ごとの集計は,つまりヒストグラムだが,単純にピボットテーブルを適用してもできない.どの区間に属するかを計算するために,作業列を追加する必要がある.
EXCEL だと IF 関数のネストになるか,テーブルを人口でソートした上で INDEX 関数と MATCH 関数の組み合わせか,FREQUENCY 関数でどの区間に属するかを分類することになる.EXCEL の照合の特徴として,日本の基準である「以上未満」での照合ではなく,「より大以下」での照合となることは覚えておきたい.ピボットテーブルのグループ化は線形での等分割にしかならないため,今回の作業には向かない.
後述するが,同じ作業を SQL では CASE 式を使ってスマートに記述できる.
テキストファイルに「名前を付けて保存」
「ファイル」タブの「名前を付けて保存」でファイル形式を「テキスト(タブ区切り)(*.txt)」とする.

警告が出るが気にせず OK をクリックする.

データベースの作成
SQL Serverのオブジェクトエクスプローラーで「新しいデータベース…」を選ぶ.
「新しいデータベース」で「データベース名」を CityPopulationDB とする.
ファイルのインポート
作成したデータベースを右クリックして「タスク」「データのインポート…」と進む.
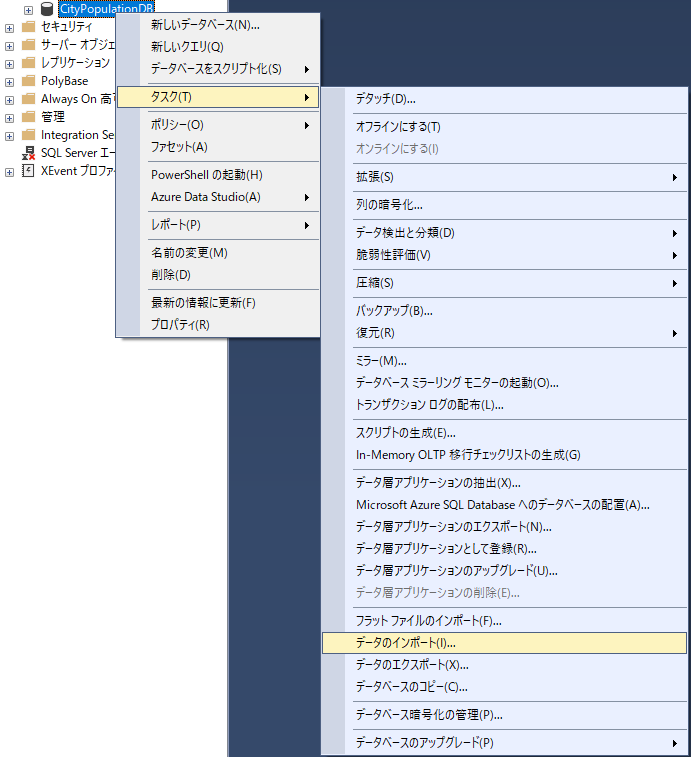
「データソース」からFlat File Sourceを選ぶ.
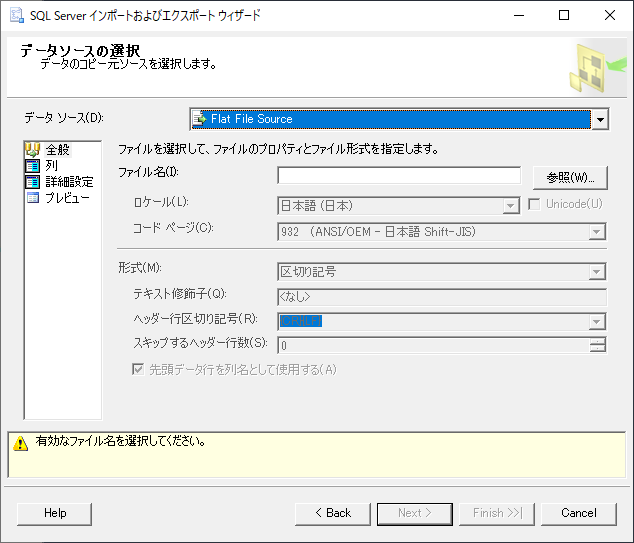
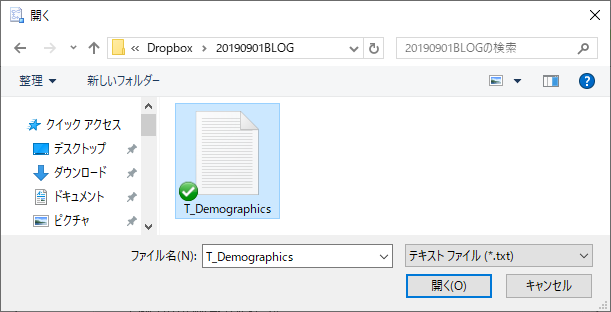
先程 EXCEL からエクスポートしたテキストファイルを指定する.
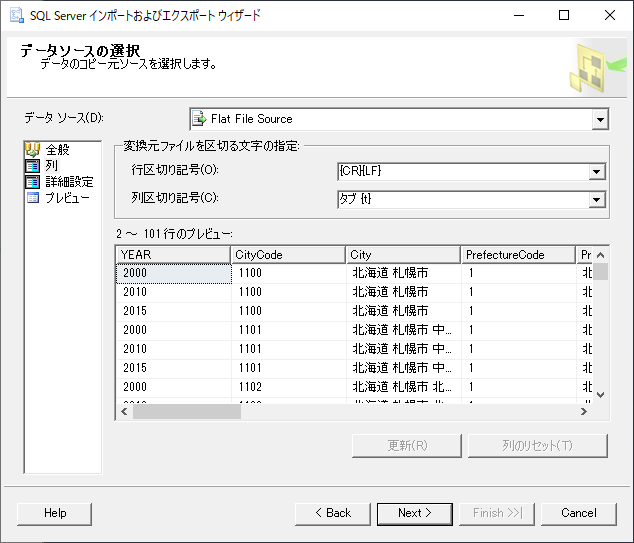
プレビューが見える.Nextをクリックする.
「変換先」は SQL Server Native Client を選択する.
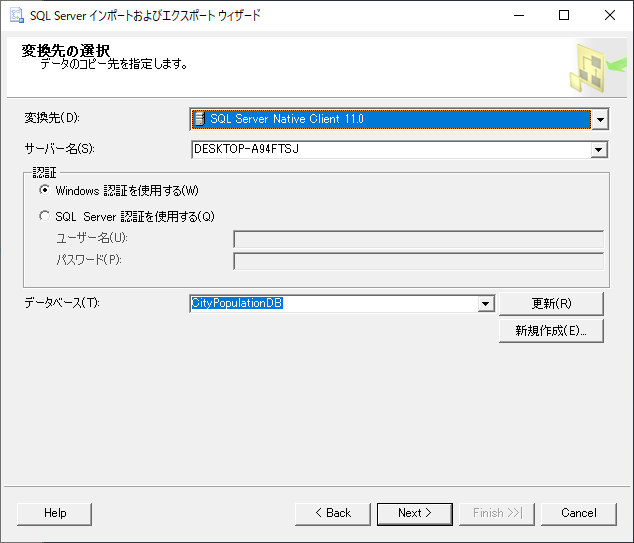
「マッピングの編集…」をクリックする.
列マッピングのデフォルト状態.ここから NULLの可否,データ型,サイズを変更していく.
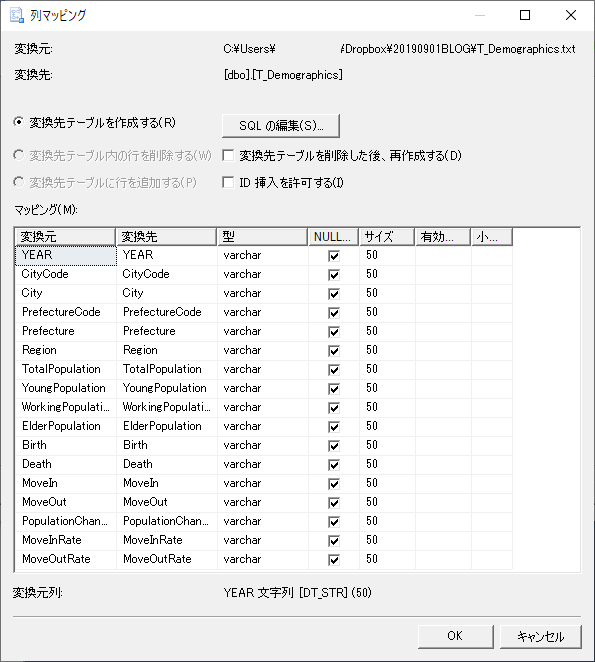
列マッピングの変更後.人口のデータ型が bigint 型であることに注意.
エラー時の対応を決める.ここでは「無視する」としている.
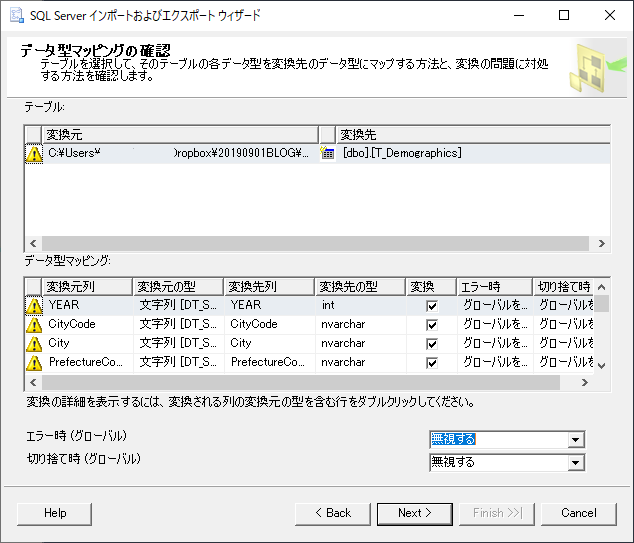
この後 Finish をクリックすると,キャプチャはないが,インポートが成功した旨通知される.
クエリの作成
実際のクエリは下記のようになる.CASE 式を用いた特性関数である.SQL Server Management Studio でも変数入力のアシストはしてくれる.ピリオドを打つと自動的にポップアップするので矢印キーで選択するだけである.
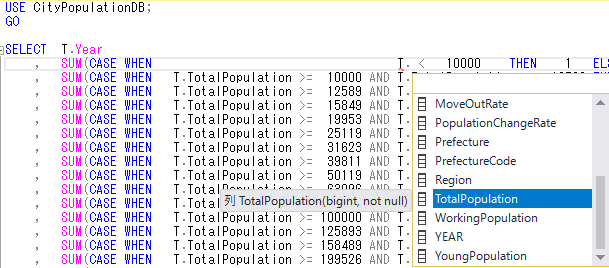
USE CityPopulationDB; GO SELECT T.Year , SUM(CASE WHEN T.TotalPopulation < 10000 THEN 1 ELSE 0 END) AS '1万人未満' , SUM(CASE WHEN T.TotalPopulation >= 10000 AND T.TotalPopulation < 12589 THEN 1 ELSE 0 END) AS '1.25万人未満' , SUM(CASE WHEN T.TotalPopulation >= 12589 AND T.TotalPopulation < 15849 THEN 1 ELSE 0 END) AS '1.5万人未満' , SUM(CASE WHEN T.TotalPopulation >= 15849 AND T.TotalPopulation < 19953 THEN 1 ELSE 0 END) AS '2万人未満' , SUM(CASE WHEN T.TotalPopulation >= 19953 AND T.TotalPopulation < 25119 THEN 1 ELSE 0 END) AS '2.5万人未満' , SUM(CASE WHEN T.TotalPopulation >= 25119 AND T.TotalPopulation < 31623 THEN 1 ELSE 0 END) AS '3万人未満' , SUM(CASE WHEN T.TotalPopulation >= 31623 AND T.TotalPopulation < 39811 THEN 1 ELSE 0 END) AS '4万人未満' , SUM(CASE WHEN T.TotalPopulation >= 39811 AND T.TotalPopulation < 50119 THEN 1 ELSE 0 END) AS '5万人未満' , SUM(CASE WHEN T.TotalPopulation >= 50119 AND T.TotalPopulation < 63096 THEN 1 ELSE 0 END) AS '6.3万人未満' , SUM(CASE WHEN T.TotalPopulation >= 63096 AND T.TotalPopulation < 79433 THEN 1 ELSE 0 END) AS '8万人未満' , SUM(CASE WHEN T.TotalPopulation >= 79433 AND T.TotalPopulation < 100000 THEN 1 ELSE 0 END) AS '10万人未満' , SUM(CASE WHEN T.TotalPopulation >= 100000 AND T.TotalPopulation < 125893 THEN 1 ELSE 0 END) AS '12.5万人未満' , SUM(CASE WHEN T.TotalPopulation >= 125893 AND T.TotalPopulation < 158489 THEN 1 ELSE 0 END) AS '15万人未満' , SUM(CASE WHEN T.TotalPopulation >= 158489 AND T.TotalPopulation < 199526 THEN 1 ELSE 0 END) AS '20万人未満' , SUM(CASE WHEN T.TotalPopulation >= 199526 AND T.TotalPopulation < 251189 THEN 1 ELSE 0 END) AS '25万人未満' , SUM(CASE WHEN T.TotalPopulation >= 251189 AND T.TotalPopulation < 316228 THEN 1 ELSE 0 END) AS '30万人未満' , SUM(CASE WHEN T.TotalPopulation >= 316228 AND T.TotalPopulation < 398107 THEN 1 ELSE 0 END) AS '40万人未満' , SUM(CASE WHEN T.TotalPopulation >= 398107 AND T.TotalPopulation < 501187 THEN 1 ELSE 0 END) AS '50万人未満' , SUM(CASE WHEN T.TotalPopulation >= 501187 AND T.TotalPopulation < 630957 THEN 1 ELSE 0 END) AS '63万人未満' , SUM(CASE WHEN T.TotalPopulation >= 630957 AND T.TotalPopulation < 794328 THEN 1 ELSE 0 END) AS '80万人未満' , SUM(CASE WHEN T.TotalPopulation >= 794328 AND T.TotalPopulation < 1000000 THEN 1 ELSE 0 END) AS '100万人未満' , SUM(CASE WHEN T.TotalPopulation >=1000000 THEN 1 ELSE 0 END) AS '100万以上' FROM dbo.T_Demographics AS T WHERE RIGHT(T.City, 1) = '市' GROUP BY T.Year ORDER BY T.Year;
EXCEL に戻り,グラフを描く
SQL Server から EXCEL へ
クエリを発行して取得された結果を右クリックして「ヘッダー付きでコピー」し,先程の EXCEL の「市町村人口動態」ブックにペーストする.もちろん,新しいワークシートにである.
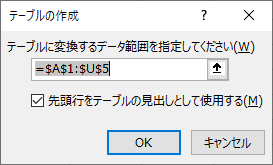
貼り付けたデータをテーブルに変換しておく.
ここまでで完全なデータセットが完成した.ここからはグラフを描いていく.
散布図の描画
新しいワークシートを挿入する.「挿入」タブから「散布図」を選ぶ.なぜ散布図か?データ系列の指定がしやすいというメリットがあるのと,後でグラフの種類の変更が効くからである.
データ系列の指定
ここではまだデータ系列を指定していない.グラフの一部を右クリックして「データの選択…」を選ぶ.
「データソースの選択」で「凡例項目(系列)」の「追加」をクリックし,データ系列を新規作成する.
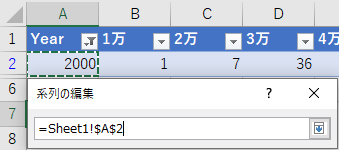
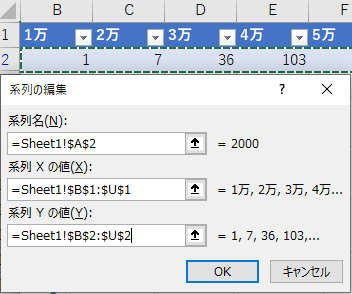
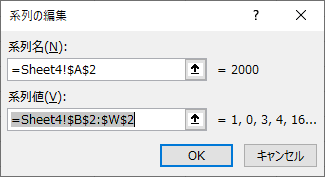
「系列の編集」で「系列名」「系列Xの値」「系列Yの値」をそれぞれ指定する.
セル範囲を指定するボックスには上向きの矢印がついている.これをクリックすると他のワークシートを参照できるようになる.ちなみにこの過程をマクロ記録すると,CutCopyMode = False という一文が記述されるが,この辺りは深入りしないほうが良い.
ユーザーインターフェースでは,セル範囲を指定するボックスをクリックすると他のワークシートを参照できるようになる.
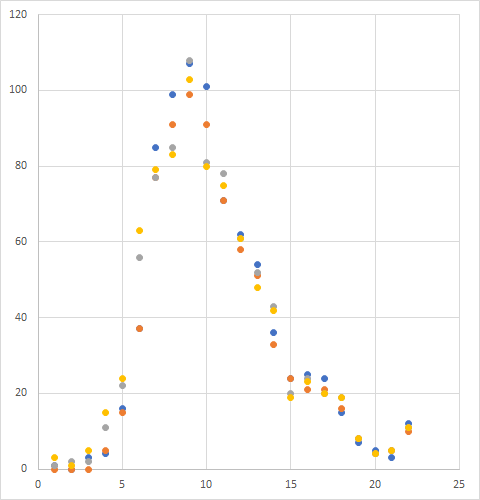
同様の手順で 2005 年,2010 年,2015 年のデータ系列を追加していく.その結果グラフはこうなる.
グラフの種類を集合縦棒グラフに変更
ここでグラフの種類を変更する.グラフを右クリックして「グラフの種類の変更…」を選ぶ.
「縦棒」の「集合縦棒」を選び,OKをクリックする.すでにどんなグラフになるかプレビューが見えている.
データ系列はどうなっているのか?
この時点でデータ系列はどうなっているのだろうか.右クリックして「データの選択…」を見てみよう.
右側のパネルに「横(項目)軸ラベル」が入っている.これを「編集」してみる.
ここでは軸ラベルの範囲を設定できるようだ.VBA でいうところの Series.xlCategory にあたる.「キャンセル」で抜ける.
今度は左側のパネルから「系列」を「編集」してみよう.Series.Name と Series.xlValue にあたるものだ.ここもキャンセルする.
グラフ要素の書式設定
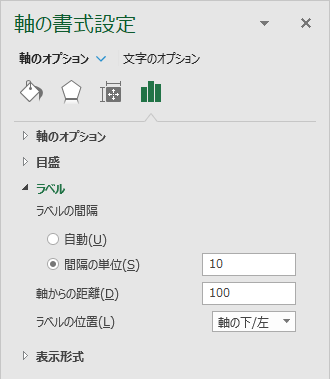
横軸のラベルの間隔を 10 にする
横軸をクリックして「軸の書式設定…」を選ぶ.「ラベル」を展開して「ラベルの間隔」を「自動」から「間隔の単位」にチェックを付け直す. 1 を消して 10 に変更する.設定できる範囲は 1 から 255 までである.
縦軸と横軸の目盛線を削除する
徹底的にシンプルを心がける.必要最小限の要素しか見せたくない.グラフの目盛線をクリックしてキーボードの Delete キーを押して削除する.
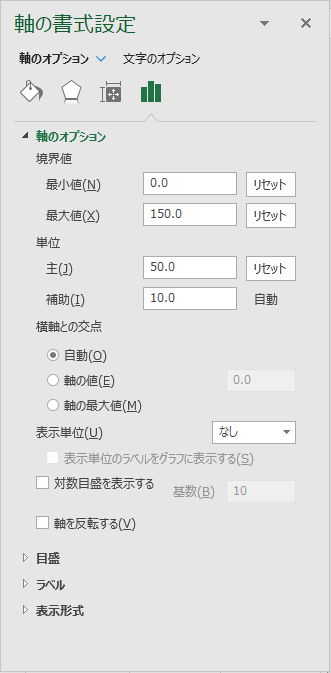
縦軸のオプションで最大値と間隔を変更する
縦軸を右クリックして「軸の書式設定…」「軸のオプション」で「境界値」の「最大値」を 150 に,「単位」の「主」を 50 に変更する.
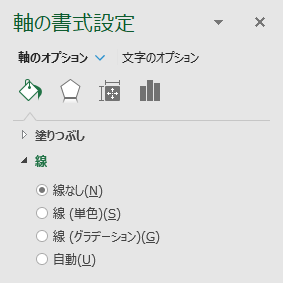
縦軸と横軸を消す
「軸の書式設定」の「線」で「線なし」をチェックする.ラベルのみが残り,軸そのものは見えなくなる.軸そのものを選択して削除しているのではないことに注意されたい.
ここまでの設定でグラフはこうなっている.
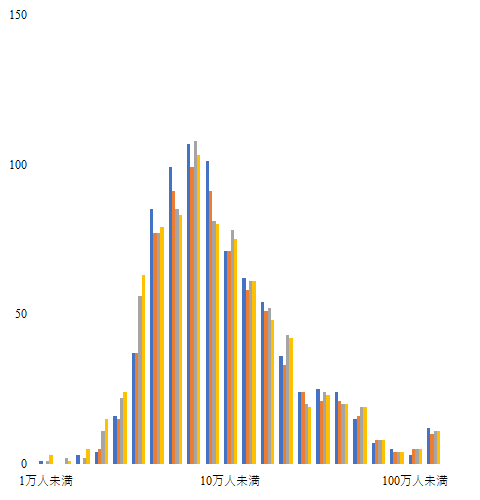
グラフエリアの書式設定
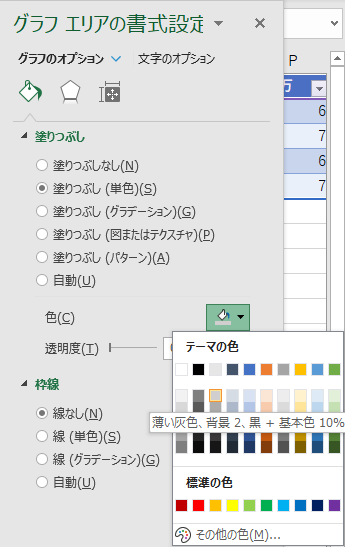
グラフエリアを右クリックして「グラフエリアの書式設定」を選ぶ.「グラフエリアの書式設定」で「塗りつぶし」を「塗りつぶし(単色)」の「薄い灰色,背景2,黒+基本色10%」にする.「枠線」は「線なし」を選ぶ.
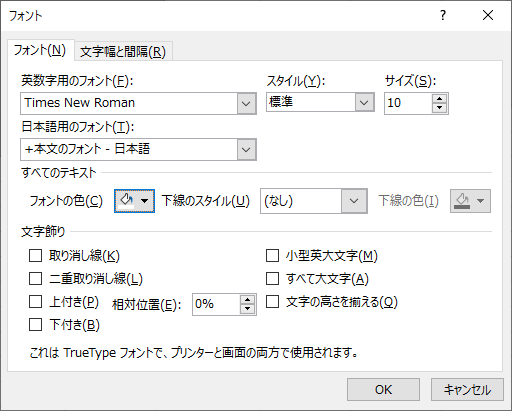
フォントはグラフエリアからまとめて設定する
グラフエリアから「フォント」にアクセスすると縦軸・横軸をはじめ,他にタイトルなどのフォントをまとめて変更できる.つまり,グラフエリアでのフォントの変更の影響はグラフ全体に及ぶ.
グラフエリアを右クリックして「フォント…」を選ぶ行為がそれにあたる.プロットエリアを右クリックしても「フォント…」メニューは現れない.
ここで EXCEL は Font2 オブジェクトにアクセスしている.これは比較的新しいオブジェクトである.縦軸,横軸,目盛り,タイトルなどグラフの要素を個別に選択した場合には EXCEL は旧来の Font オブジェクトにアクセスする.
EXCEL 内部ではおそらく Font2 オブジェクトに統一されているのだろう.旧来のバージョンとの互換性を保つために Font オブジェクトが残されていると想像している.
実際,「マクロの記録」で取得したコードをそのまま走らせても Font2 オブジェクトを取得できないが, Chart オブジェクトの次に ChartArea オブジェクトを記述することで取得できるようになる.これはバグだと思われる.
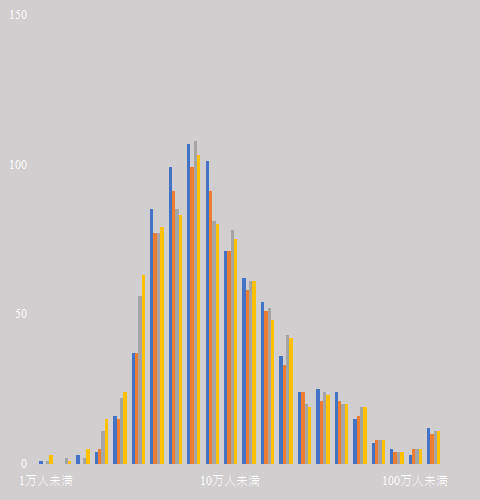
データ系列の書式設定の変更
ユーザーインターフェースでは複数のデータ系列を同時に変更することはできない.一つずつ手動で設定するか,VBA でループするかのいずれかである.今回は系列数がそれほど多くないためユーザーインターフェースでも良いが,あえてコードで設定を変更してみよう.
マクロの記録
下記はマクロの記録をそのままコピペしたものである.With 句で始まるブロックが三つあり,かなり重複している.変更に無関係のコードも記述されている.
ここで本当に必要なのは 21 行目と 24 行目だけである.
Sub Macro9() ActiveSheet.ChartObjects("グラフ 1").Activate ActiveChart.FullSeriesCollection(1).Select With Selection.Format.Fill .Visible = msoTrue .ForeColor.ObjectThemeColor = msoThemeColorAccent1 .ForeColor.TintAndShade = 0 .ForeColor.Brightness = 0 .Solid End With With Selection.Format.Fill .Visible = msoTrue .ForeColor.ObjectThemeColor = msoThemeColorBackground1 .ForeColor.TintAndShade = 0 .ForeColor.Brightness = 0 .Transparency = 0 .Solid End With With Selection.Format.Fill .Visible = msoTrue .ForeColor.ObjectThemeColor = msoThemeColorBackground1 .ForeColor.TintAndShade = 0 .ForeColor.Brightness = 0 .Transparency = 0.5 .Solid End With End Sub
整形後のコード
変数を定義し,ループ内で塗りつぶしの色を「白,背景 1」に変更し,透過性を 50 % に変更している.
Sub Macro10() Dim Cht As Chart Dim MySeries As Series Set Cht = ActiveSheet.ChartObjects("グラフ 1").Chart For Each MySeries In Cht.SeriesCollection With MySeries.Format.Fill .ForeColor.ObjectThemeColor = msoThemeColorBackground1 .Transparency = 0.5 End With Next MySeries End Sub
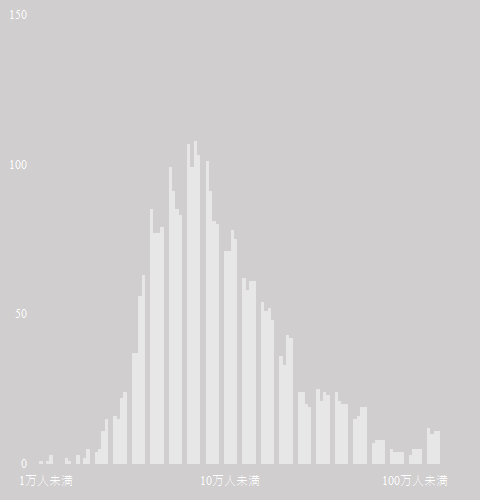
ここまでの設定でグラフは下図のようになっている.
タイトルをつける
「グラフのデザイン」タブの「グラフ要素を追加」から「グラフタイトル」と進み,「中央重ねで配置」を選ぶ.
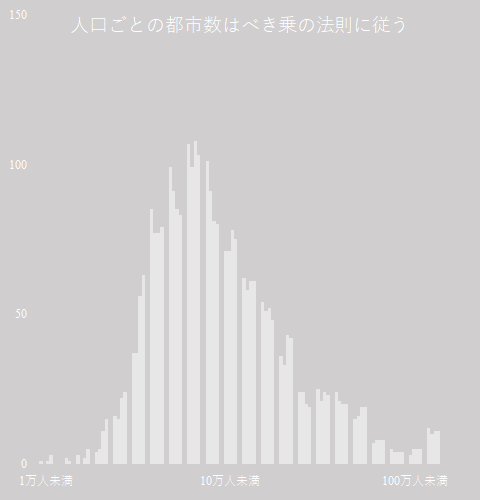
「人口ごとの都市数はべき乗の法則に従う」と入力する.グラフはこうなる.
考察
この記事の最初で「人口が半分の都市は四つある」とのマーク・ブキャナンの言葉を紹介した.
グラフを観察すると,「6.3 万人未満」でピーク(100 前後)が来てきれいに右肩下がりとなっている.「15 万人未満」で約半分(50 前後)になる.
アメリカの場合ほど傾きは顕著でないものの,「片対数グラフに載せると直線を描く」というべき乗の法則は満たしているように見える.
地方自治法では「人口 5 万人以上」が市の要件の一つとされているが, 1995 年に成立し 2005 年に失効したいわゆる合併特例法により,市制の要件は人口 3 万人以上に緩和された.
これはヒストグラムであるが,階級幅を線形でしか扱えないのは問題だ.対数の階級幅でヒストグラムを作成できるようソフトウェアを改良する必要がある.
まとめ
EXCEL の集合縦棒グラフで人口ごとの都市数を示した.べき乗の法則に従っていると考えられる.
総務省の e-Stat からデータをダウンロードする方法を示した.エラーなどの技術的な問題はあるものの,対処法も示した.
ソフトウェアで作成するヒストグラムの階級幅の設定に問題があることを示した.対数の階級幅で作成できるようにすべきである.
データを美しく表現するには,可能な限り要素を削ぎ落とす必要がある.そのための方法を示した.


“人口ごとの都市数をEXCELの集合縦棒グラフで描く” への1件の返信