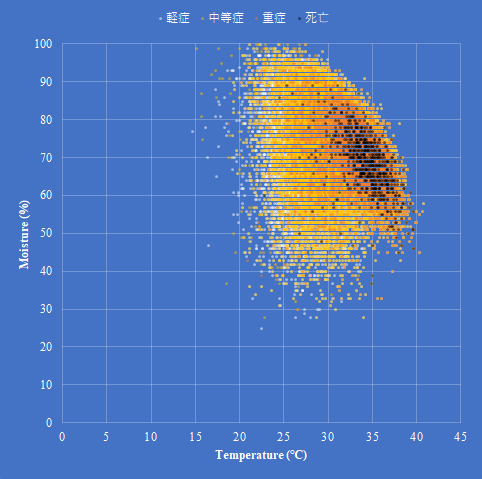
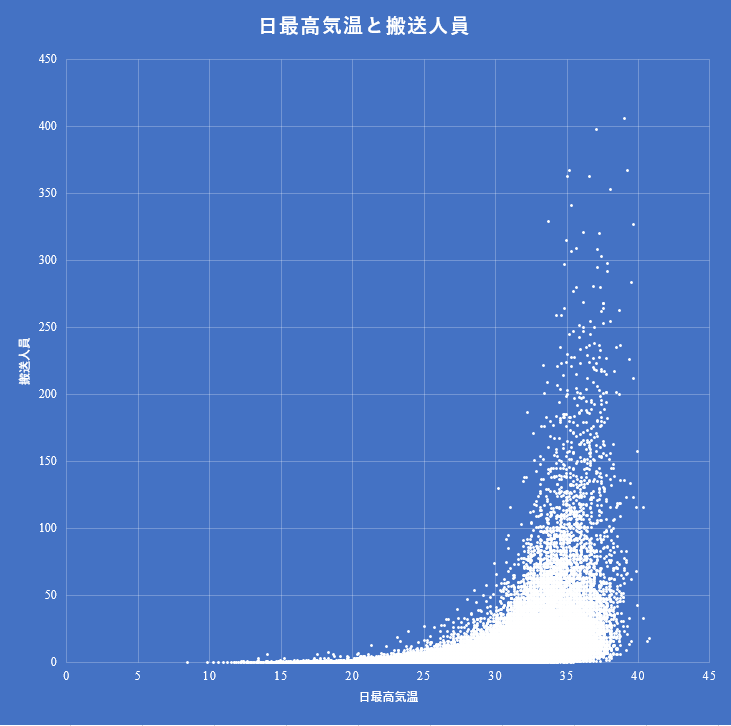
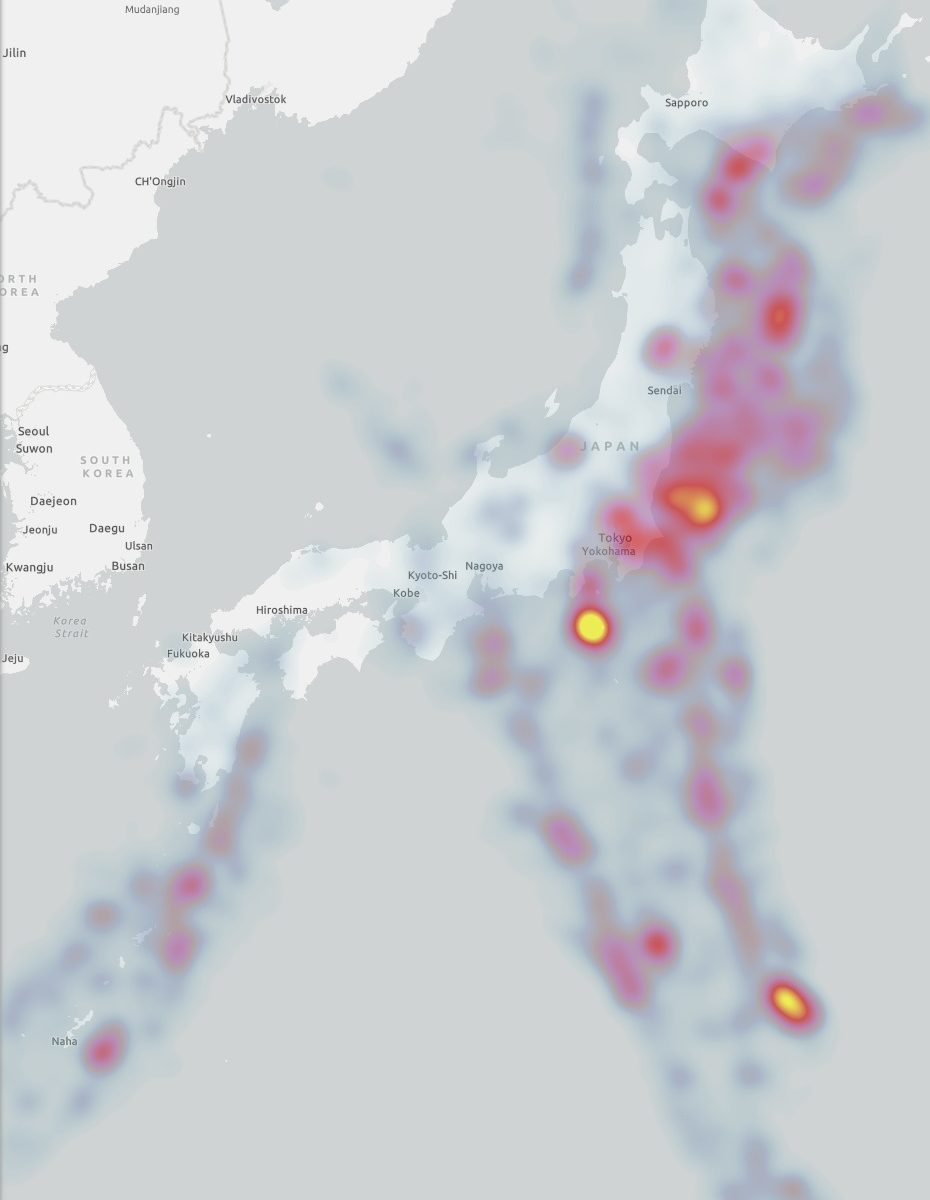
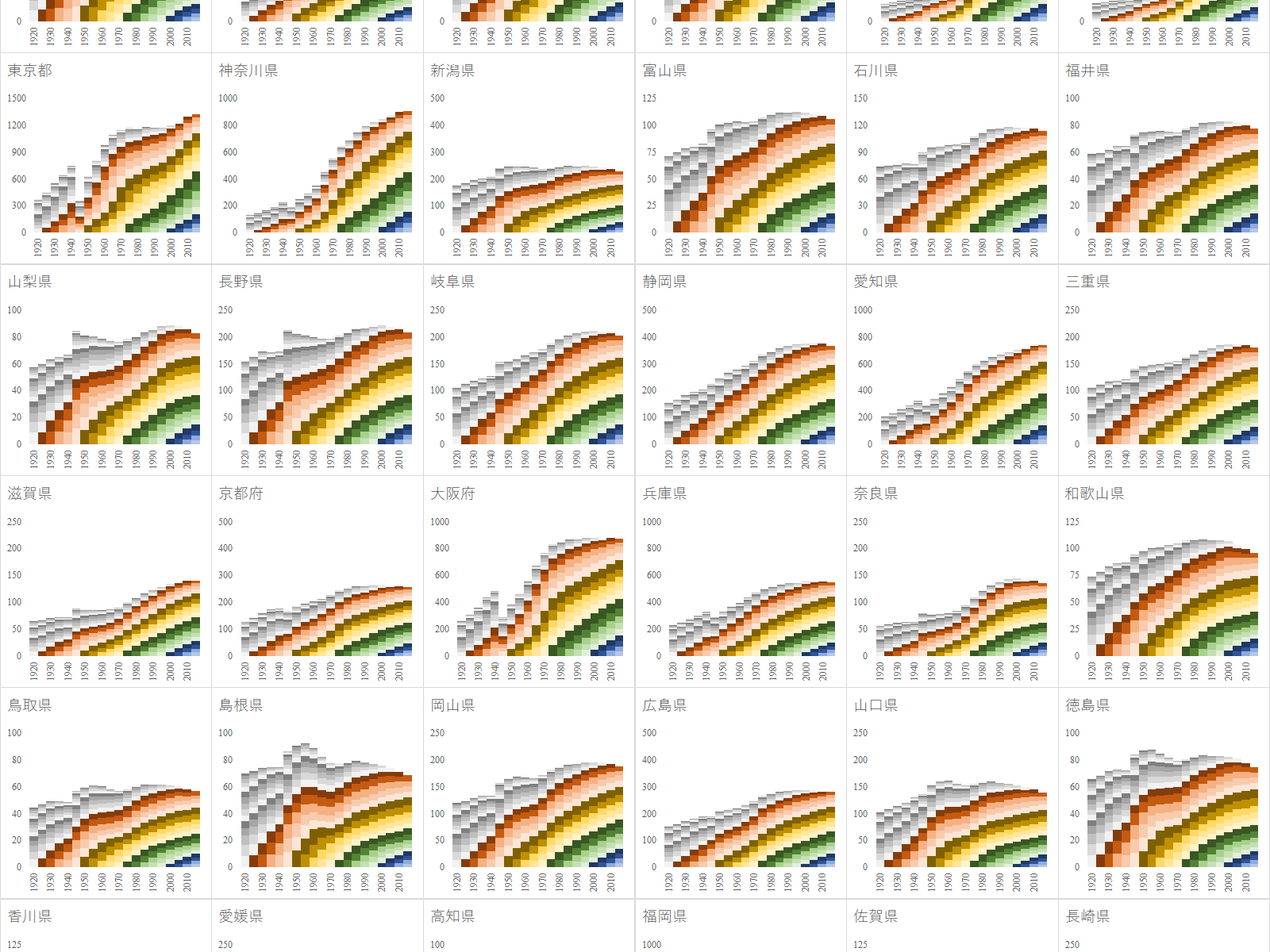
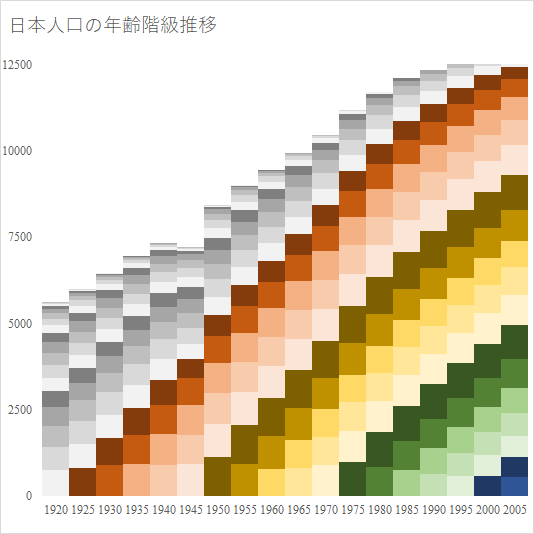
総務省の公開しているe-Statには社会疫学的指標が多く含まれる.今回熱中症搬送人員数に様々な指標を加えて解析してみた.
説明変数として日最高気温,日平均水蒸気圧,都道府県人口に加えて過去30日間の平均気温,エアコン保有台数,年間収入のジニ係数,光熱・水道費,実収入,第1次産業就業者比率,第2次産業就業者比率,都市公園数,都市緑化割合,自然公園割合,自然公園数,生活保護被保護人員を加えた.
すべての変数が有意であったが,VIFを見ると多重共線性を疑わせる変数もあり,良いモデルとは言えない結果となった.