世界各国の人口推移およびGDP推移を取得したい.そんな場合は国連や世界銀行のデータを活用する.今回は国連から人口推移,世界銀行からGDP推移のデータをそれぞれ取得したので経緯を紹介する.
国連の人口データおよび世界銀行のGDPデータをダウンロードする

Co-evolution of human and technology
世界各国の人口推移およびGDP推移を取得したい.そんな場合は国連や世界銀行のデータを活用する.今回は国連から人口推移,世界銀行からGDP推移のデータをそれぞれ取得したので経緯を紹介する.
総務省消防庁の公開している熱中症搬送人員数は都道府県ごとに毎日データを反復抽出しているとも言える.複数の都道府県から繰り返しデータを取るのは独立した反復ではなく,疑似反復と考えられる.このような場合,都道府県単位で差が生じると考えられ,一般化線形混合モデルを用いて回帰係数を推定する必要がある.
今回はRのglmmML()関数を用いて一般化線形混合モデルを用いた回帰係数の推定を行った.
日本の住宅の断熱性はクソだ!では感情的な投稿を行ったが,本稿ではデータをもとに住宅の断熱性能の重要性を述べる.この論文の提起する問題は皆が思っていることであるが,データで示されたのは初めてだと思う.
論文自体はここから読める.全訳したが,筆者の英語力の乏しさゆえ,やや読解しにくいところはご容赦いただきたい.

2020 年の国勢調査の結果がようやくeSTATに反映された.日本の市区町村よりも粒度の細かい小地域(町丁・字等別)の人口構成が公表されたのは2022年6月24日付である.今回はこのデータをSQL Serverに取り込んでみたい.
“eSTATの小地域(町丁・字等別)毎の年齢(5歳階級、4区分)別、男女別人口をSQL ServerにBULK INSERTする” の続きを読む
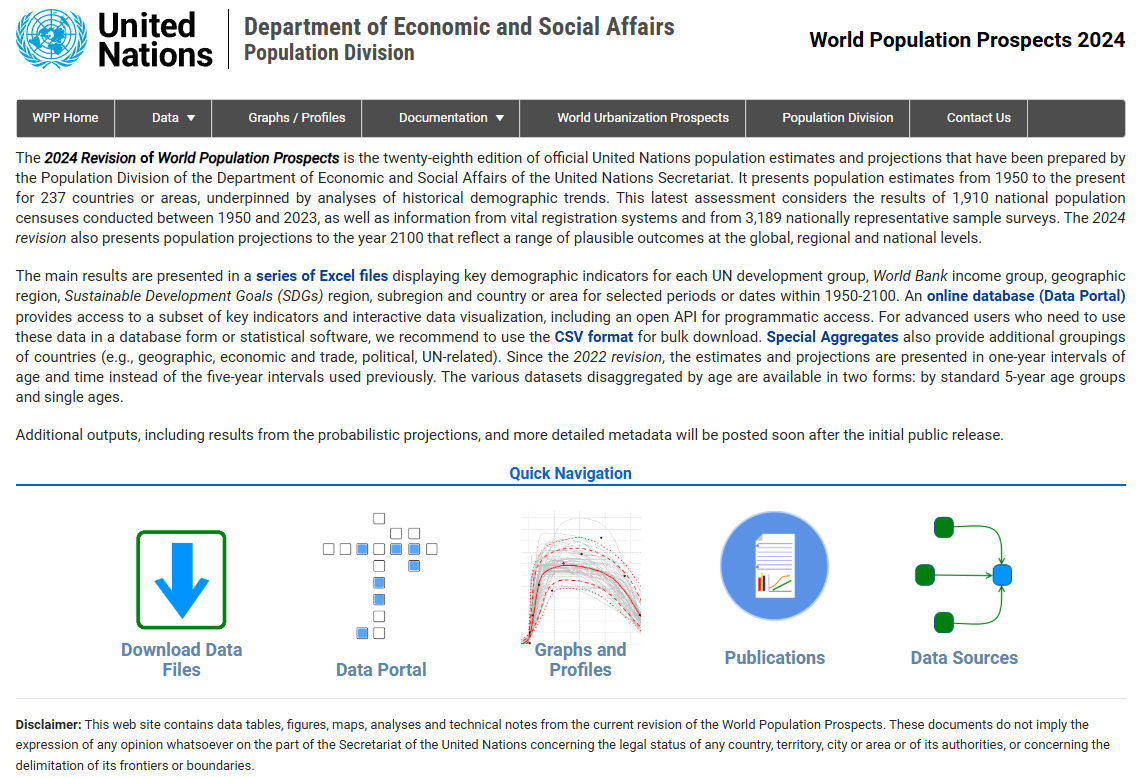
化石燃料が悪者扱いされているが,日本においては原子力発電所の稼働停止により火力発電所の稼働は止むを得ない.eStatから日本の資源収支を概略するでは化石燃料の代表として都市ガス販売量とガソリン販売量を挙げたが,今回は1980年以降の石油需給について,経済産業省の石油統計を調べてみた.
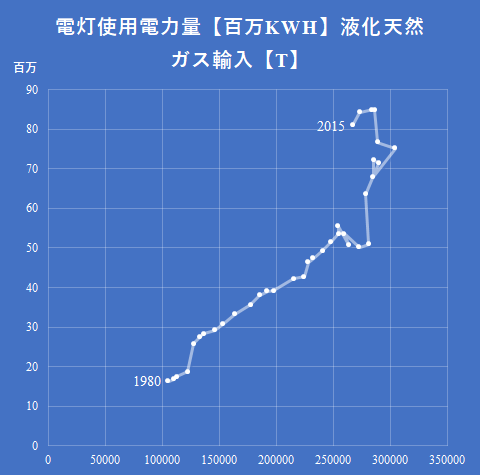
eStatから日本の資源収支を概略するで概略を取り上げた話題の一つに,トイレ水洗化人口が挙げられる.今回は各都道府県ごとの下水道によるトイレ水洗化人口の人口に占める割合の推移をグラフ化する.
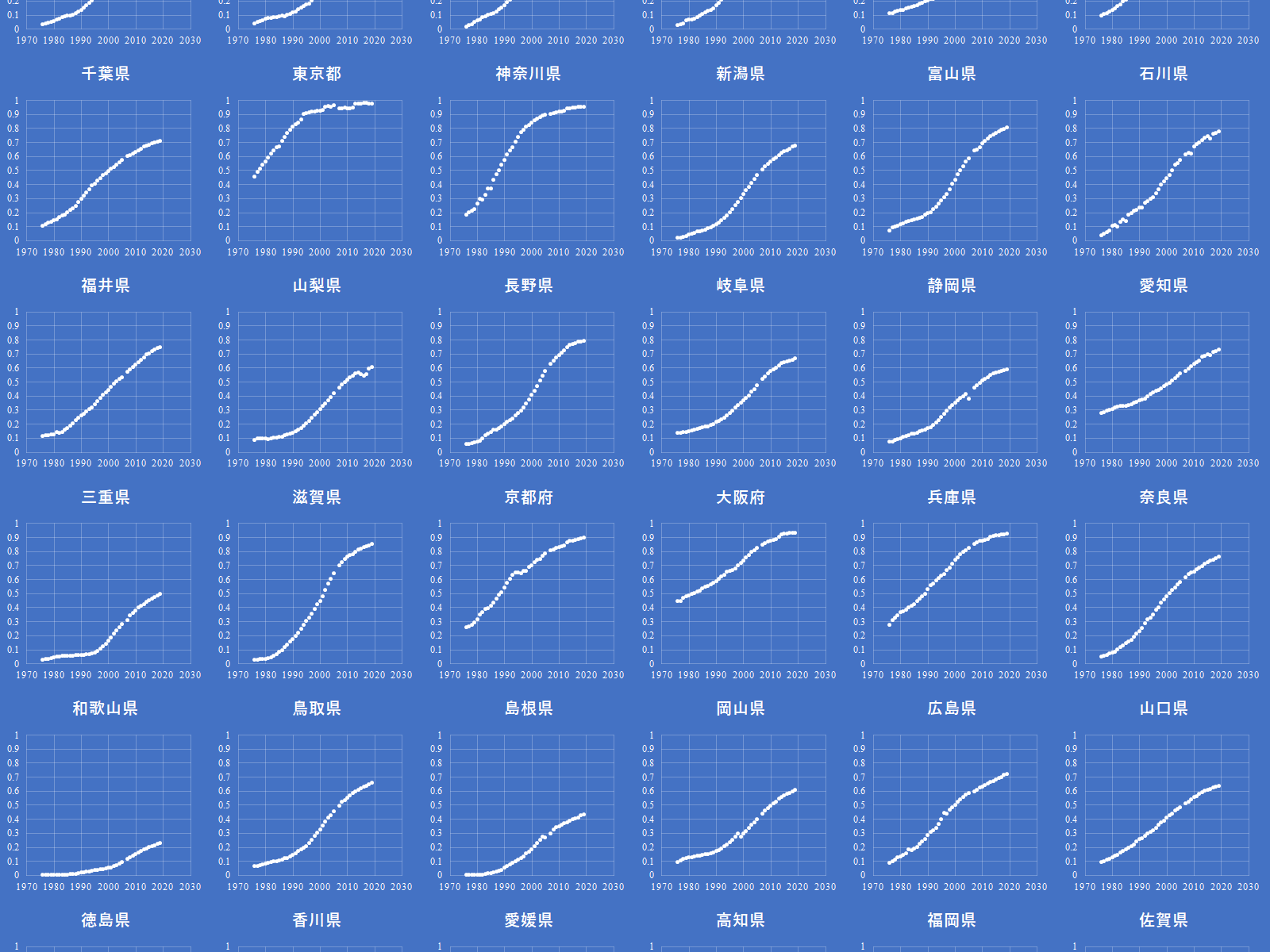
最高気温と熱中症の搬送人数との間に相関関係はあるだろうか.熱中症で救急搬送された人数は総務省の消防庁のサイトにある.これと気象庁のデータを結合してみた.
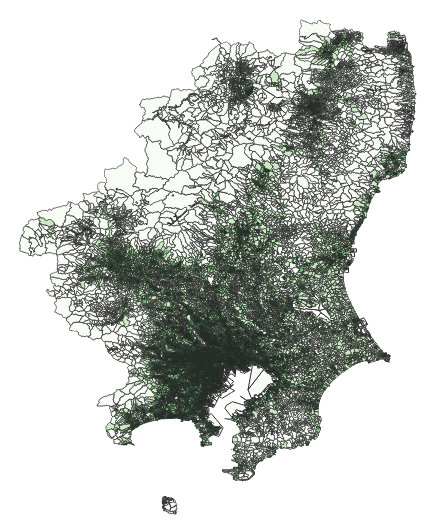
国勢調査をもとに作成された境界データダウンロードサービスがある.市区町村よりも更に細かい,町字の粒度でのGISデータである.今回は関東地方のデータをダウンロードし,QGISで人口密度を可視化する.
“eStatの地図で見る統計(統計GIS)データダウンロードから小地域の境界データをダウンロードし,人口密度をQGISで表現する” の続きを読む
Shape2SQL は以前の記事でも触れたが,ESRI 社の Shape ファイルを SQL Server のテーブルに直接アップロードしてくれるツールである.残念ながら更新は停止しており,最新の SQL Server とは互換性がない.今回,SQL Server 2008 R2 を新規インストールしたところ,アップロードがうまく行ったので報告する.
多くの空間アプリケーションがカスタム定義の空間機能を組み合わせている.例えば顧客セットの局在と,広く受け入れられた表現の空間データ,地球上の汎用性のある特徴,例えば国や州の境界線,世界の主要都市の局在および主要な道路や鉄道の経路などである.この情報は自分自身で作成するよりも,多くの代替可能な資源が存在しており,そこから普通に使うための空間データを取得して空間アプリケーションに搭載できる.
本章では,そこから一般公開された空間情報を取得できる資源,そこでそのデータが普通に提供されるフォーマットおよびその情報を SQL Server にインポートするのに使える技術を紹介しよう.
“第 6 章 空間データをインポートする (Beginning Spatial with SQL Server 2008)” の続きを読む