
日本の人口統計は総務省が 5 年おきに行う国勢調査が元になっている.日本の市の人口順位をEXCELにダウンロードして散布図に描くでは日本全国の都市の人口増減率と人口の関係を時系列で流すとどう推移するか予測した.今回はその予測が実態と合っているか乖離しているかの検証を行う.
データクレンジングは形式的作業と本質的作業の行ったり来たり
データクレンジングをやっていると,本質にはあまり関係のない形式的作業と,本質にかかわる作業を行ったり来たりしていることに気がつく.
両者とも重要なのだが,日本の官公庁の作成したデータには本質に関係のない形式的作業を要するものが少なくない.データというのは第一正規形になっていないと意味がない.気象庁にある過去の気象データはまだしも,桜開花日などの生物気象観測データなど,その最たるものだ.
情報をコンパクトに折りたたむという意味では少ないページに詰め込む意味があるのかも知れないが,データの再利用という点に関しては落第である.そもそも PDF という時点で終わっている.最低でも EXCEL でないと意味がない.
データファイルは都道府県・市区町村別統計表
2000 年,2005 年,2010 年,2015 年の 4 件がダウンロードできる.
各ファイルの外観
ダウンロードして開いたばかりの各ファイルの外観である.ここからデータを抽出していく.
形式的作業
ウィンドウ枠固定の解除
ウィンドウ枠は良かれと思って作成者が固定しておいたものだろう.データ抽出の邪魔になるため固定を解除する.
メモの削除
セル右肩に赤い三角のあるセルにはメモが付加されている.これはワークシートの操作で邪魔になるため削除する.
ハイパーリンクの削除
本質的作業
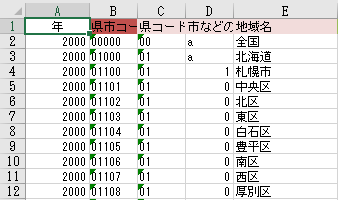
都道府県・市区町村コード,都道府県コード,市区町村コード,都道府県・市区町村名の抽出
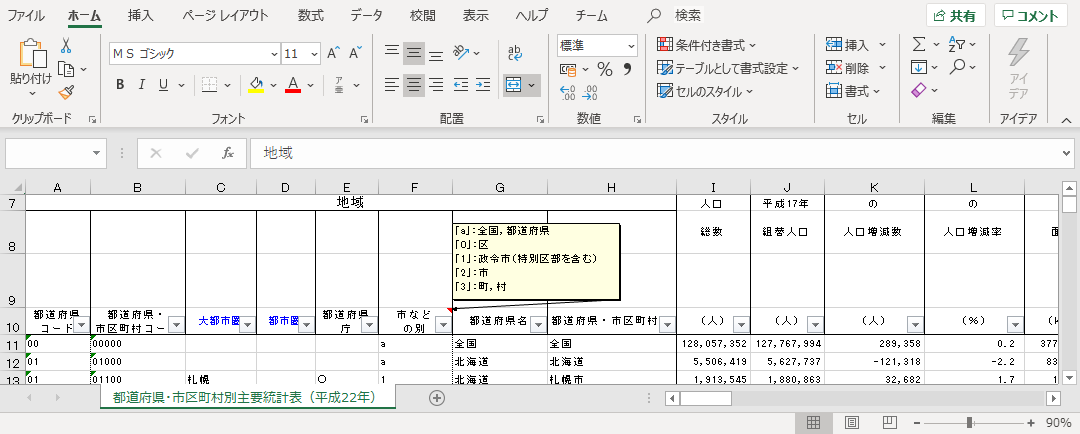
セルに赤で色をつけたタイトルが抽出すべきものである.コード名が 2005 年までと 2010 年以降で変わっているが,新しいコード名ほど正確であることが分かる.

人口総数,組替人口,人口増減数,人口増減率,年齢階級別人口,年齢階級別人口割合の抽出
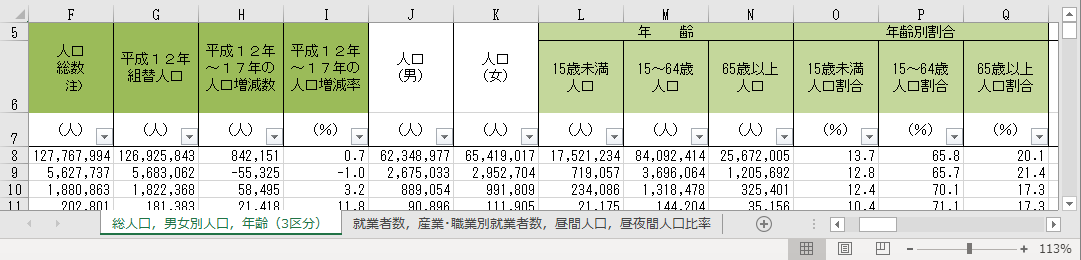
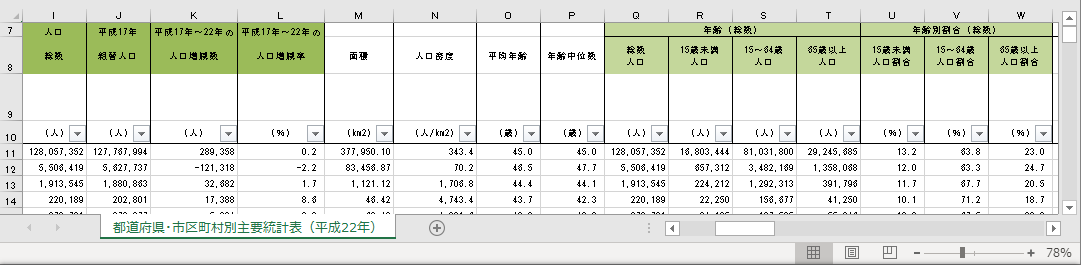
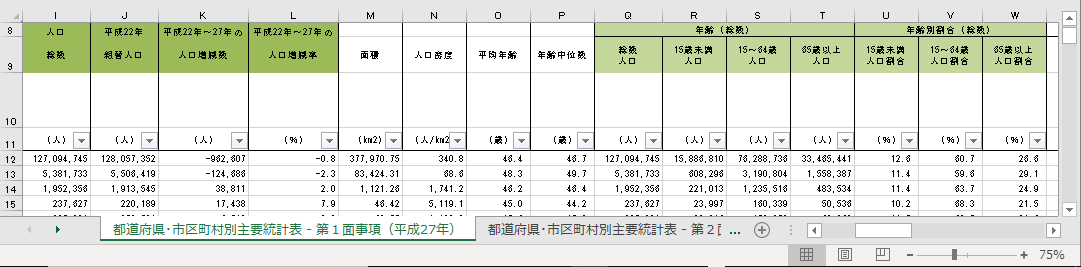
不要な列は削除する
前章で抽出した列以外は削除する.年によって調査する項目は変動するが,それはその時の政府の方針によって調査する項目が変わるからである.必ず調査しなくてはならない項目は一貫している.
結果を示す.
形式的作業
ここで再び形式的作業に戻る.データの本質には直接関係のない作業である.
セル結合はすべて解除
EXCEL のワークシートを第一正規形にする際にまず問題になるのが結合されたセルである.「セル結合はすべて解除」と覚えておいてほしい.
ワークシートのセルをすべて選択し,コントロールキーと1のキーを押す.「セルの書式設定」が開く.
ここで設定を変更すべき箇所はいくつかあるが,最も重要なのは「セルを結合する」のチェックを外すことである.
罫線の削除
このタイミングで罫線も削除しておこう.「セルの書式設定」の「罫線」タブで「なし」をクリックする.
スペースの削除
位置揃えのためのスペースは検索のじゃまになる.「検索と置換」で一括削除する.
セル内改行の削除
セル内改行もやっかいである.「検索と置換」で「検索する文字列」にコントロールキーと J キーをタイプし,「置換する文字列」は何も入力せず「すべて置換」する.
フィルターの解除
「データ」タブの「並べ替えとフィルター」で「フィルター」がオンになっているのでクリックして解除する.
タイトル行を揃える
「切り取り」と「貼り付け」でタイトル行の位置を揃える.図は 2015 年のものである.

本質的作業
市コードのないファイルがある!
そろそろ重大な間違いに気がついても良さそうである.2010 年と 2015 年のファイルには 3 桁の市コードがない.
厳密に言うと,5桁の都道府県・市区町村コードがあれば都道府県コードも都道府県名も市区町村名も導出できる.しかしここではテーブルを正規化しないため,対応を決める必要がある.
削除するほうが簡単である.2000 年版と 2005 年版から市コードを削除する.
人口総数の列が重複しているので削除
まだある.2010 年と 2015 年のファイルには「人口増減率」と「15歳未満人口」の間に「総数人口」の列があるが,2000 年と 2005 年のファイルにはない.

差し引きゼロで列数が同数になり,間違いに気がつかなかった.重複は削除しておこう.ついでに 2010 年版と 2015 年版の E 列のタイトルを「総数」から「人口総数」に修正しておく.2010 年版と 2015 年版は余計な文字列を削除しておく.
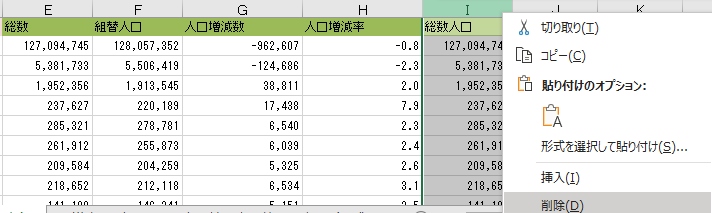
主キーとなる列は先頭に移動する
具体的には 2010 年版と 2015 年版の B 列にある「都道府県・市区町村コード」を A 列に「切り取り」「切り取ったセルの挿入」で移動する.
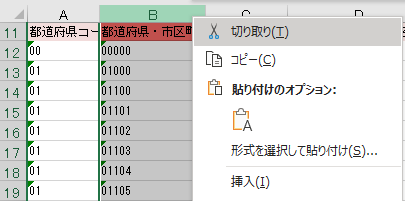
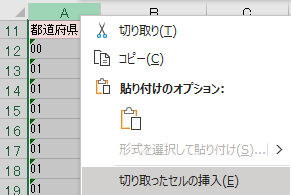
タイトル行より上は不要なので削除
繰り返すが,データクレンジングの目的は単なるワークシートをテーブルに変換することである.そのためには第一正規形の形を取っていなければならない.必要なデータは残しつつ,不要なデータは削除する.その識別が重要である.
4ファイルともタイトル行よりも上の行はテーブルには不要であるため削除する.
「年」の列を追加
さて,ここまでの作業で八割ほどは終わった.後は各ファイルを結合していくのであるが,その前に各ファイルに分割された理由を考えると,新しい列を追加する必要があることが分かる.
時間軸を追加しなければならない.今回の場合は「年月日」までは必要なく,「年」だけでよいだろう.
A 列を選択して右クリックから「挿入」して新しい列を追加する.
タイトルは「年」と入力し,データ行にはファイルに応じて 2000, 2005, 2010 または 2015 とすべての行にコピペする.
形式的作業
新しい EXCEL のファイルを新規作成
ダウンロードしたファイルは互換モードで動いている.ファイル形式が古く,新しい機能を十分に使えないため,最新の形式でファイルを新規作成したほうがよい.

タイトル行は最新版からコピペ
最新版ファイルからタイトル行を「コピー」して「値のみ貼付け」する.
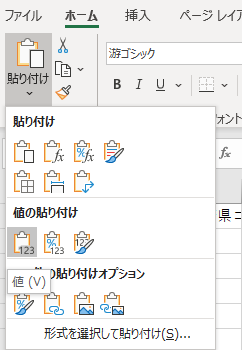
すべてのファイルからデータ行だけをコピペ
2000 年版から順にデータ行をコピペする.「値のみ貼り付け」がよいだろう.
テーブルの挿入
そのままワークシートをテーブルに変換する.
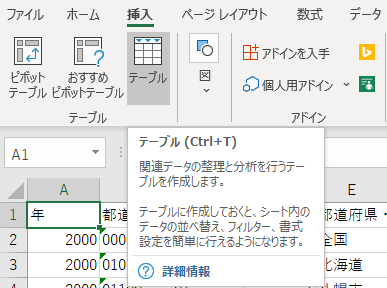
何も触らず OK をクリックする.
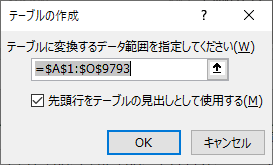
本質的作業
紛れ込んでいる集計行を探せ
さて,ここまで来て何であるが,実はデータの中に市区町村ではない,都道府県で集約した集計行が紛れ込んでいる.さらに日本全体の集計行も紛れ込んでいる.
これらは散布図を描く際にはじゃまである.市区町村のみのデータとしたい.どうするか?テーブルならフィルターをかけられる.問題はフィルターの条件である.
000で終わるコードを探せ
いくつか方法はあると思うが,最も単純なのは 5 桁の都道府県・市区町村コードのうち,000 で終わるものである.
「テキストフィルター」から「指定の値で終わる…」を選択する.
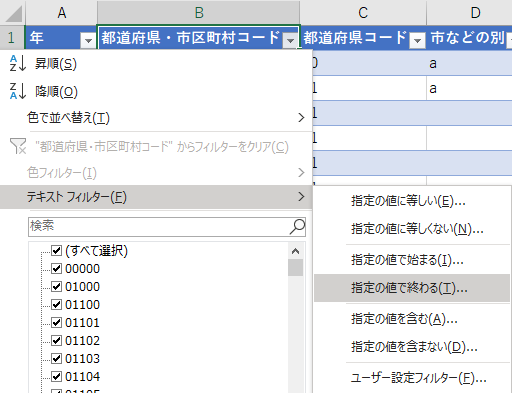
「オートフィルターオプション」の「抽出条件の指定」で都道府県・市区町村コードに 000 と入力し,OKをクリックする.
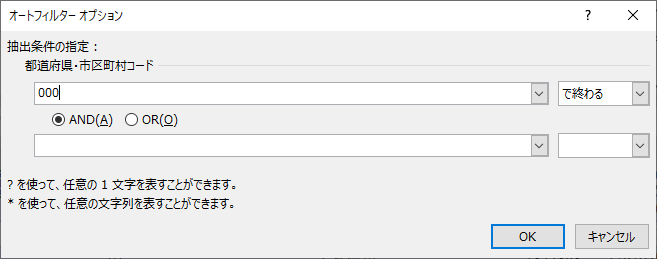
192 件が抽出される.これは都道府県の数 47 に全国を加えた 48 件の 4 倍である.
都道府県レベルの集計行は不要だが,都道府県名は必要
集計行は基本的に不要だ.削除して構わない.だが,その前にすることがある.都道府県・市区町村名の列から都道府県名を切り分けたい.
「都道府県・市区町村名」の列を選択し,右クリックして「挿入」を選ぶ.
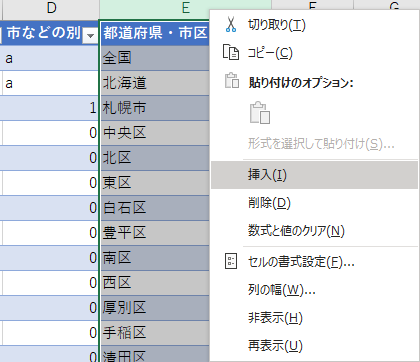
挿入した列のタイトルを「都道府県名」とし,元の列のタイトルを「市区町村名」に変更する.
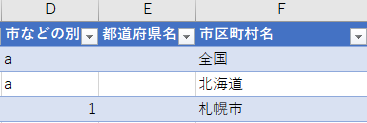
都道府県コードでフィルターし,都道府県名をコピペ
今度は都道府県コードでフィルターをかける.手作業による泥臭い作業になるが,ここだけなので我慢してついてきてほしい.
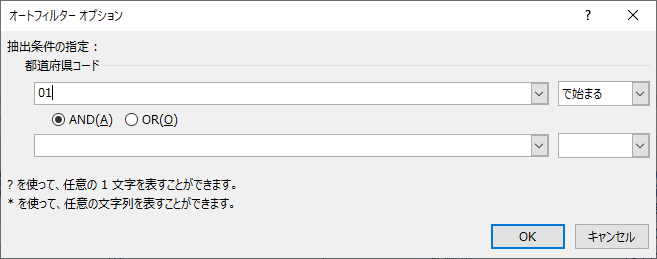
- 都道府県コードの「テキストフィルター」で「指定の値で始まる」を選ぶ
- 「01」を入力してOK
- 「北海道」をコピーして「都道府県名」の空欄に貼り付け
- 上記を都道府県の数だけ繰り返す
図で示すと以下の流れとなる.
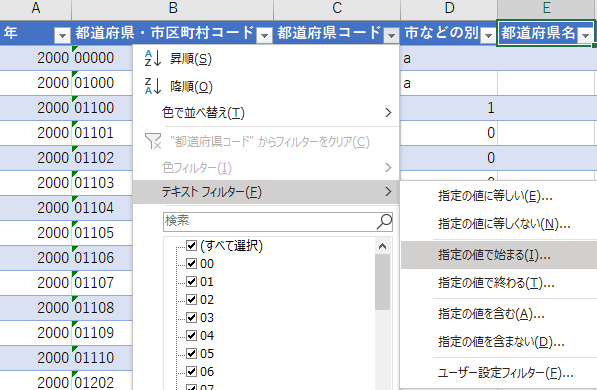

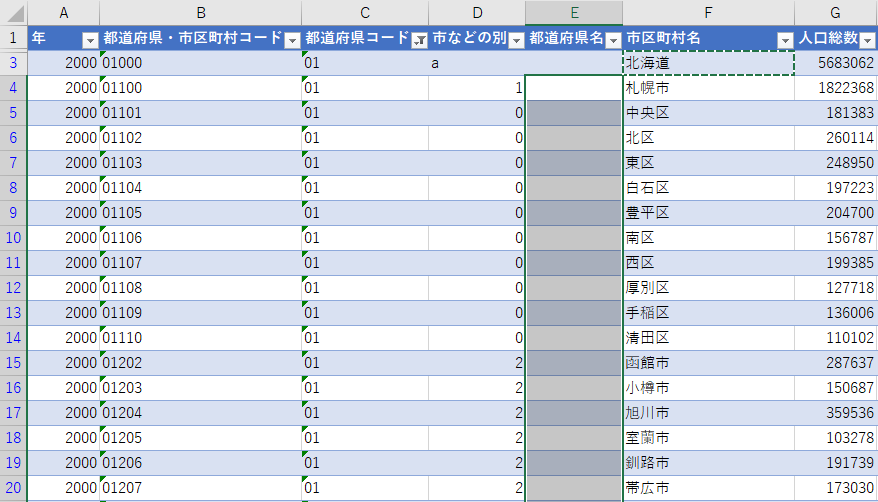
フィルターの方法は他にもある.テーブルのフィルターは重複を省略した状態でチェックして選択できるようになっており,これらのチェックボックスを一つずつオン・オフする方法でも良い.
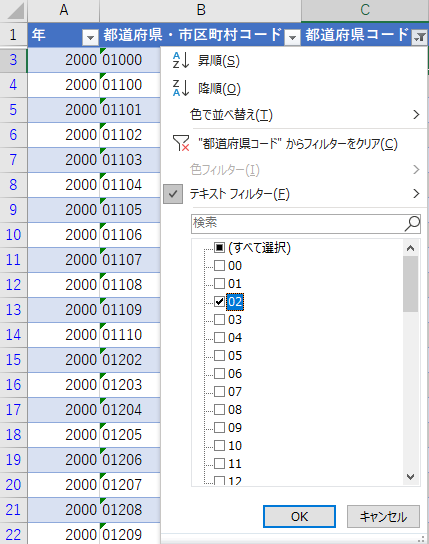
いずれにせよ,都道府県名をコピペで空欄に埋めていく作業である.全ての都道府県名が埋まったら,次の行程に入る.
形式的作業
集計行のフラグ
都道府県・市区町村コードにテキストフィルターをかける.抽出条件の指定は「000 で終わる」である.
192 件が抽出される.ここで D 列の「市などの別」をポップアップしてみると,a しか存在しない.
一旦フィルターを解除する.「市などの別」で抽出条件を a で指定し,続けて「都道府県・市区町村コード」のテキストフィルターで抽出条件を「000 で終わる」を指定すると,やはり結果は 192 件である.
これは両者が完全に一致していることを意味する.つまり,「市などの別」の値が a であることは,集計行であることのフラグである.
では,集計行を別シートに移すことにしよう.
集計行を別シートへ
「切り取り」「貼り付け」でデータを移せればよいのだが,テーブルまるごとになってしまい,なかなかうまくいかない.ワークシートごとコピーしてそれぞれ不要な行を削除する他なさそうである.
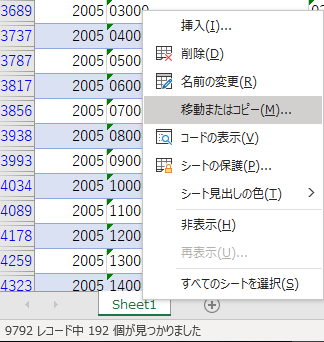
Sheet1の名前を「市区町村」コピーの名前を「都道府県」とする
Sheet1 や Sheet1(2) という名前では意味が分からないからである.
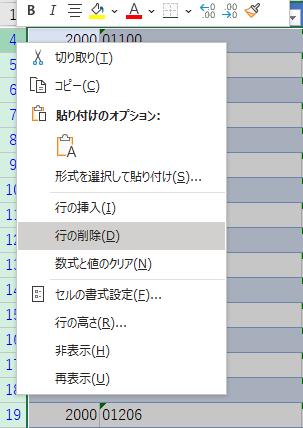
ワークシート「市区町村」では都道府県のデータを削除
「市などの別」の抽出条件を a と指定してフィルターをかける.
2 行目を選択した状態でコントロールキーとシフトキーと下矢印キーを押すと,抽出された行がすべて選択されるので,右クリックして「行の削除」を選ぶ.
フィルターを解除すると 9600 件残る.
ワークシート「都道府県」では市区町村のデータを削除
「市などの別」の抽出条件として 0, 1, 2, 3 を選んでフィルターをかける.結果は 9600 件.
2 行目以降を選択した状態で「行の削除」を選ぶ.192 件が残る.
本質的作業
市区町村マスターテーブルを作る
さて,都道府県と市区町村のテーブルを切り分けたところで次のステップに移ろう.市区町村マスターテーブルの作成である.
リレーショナルデータベースであれば当然マスターテーブルを持っている.EXCEL の場合ならワークシートの重複排除で作成できる.
市区町村ワークシートのコピー
まずは市区町村ワークシートの複製である.実験のために複製を二つ作成する.
「年」のソート
ソートには昇順と降順がある.市区町村(2) では「年」を昇順とし,市区町村(3) では「年」を降順とする.
次に両者を「都道府県・市区町村コード」の昇順でソートする.市区町村が集まってそれぞれが時間の順に並んでいる.


重複の排除
最近 EXCEL に搭載された機能のうち,かなり重要なものの一つである.「テーブルデザイン」タブの「ツール」にある.
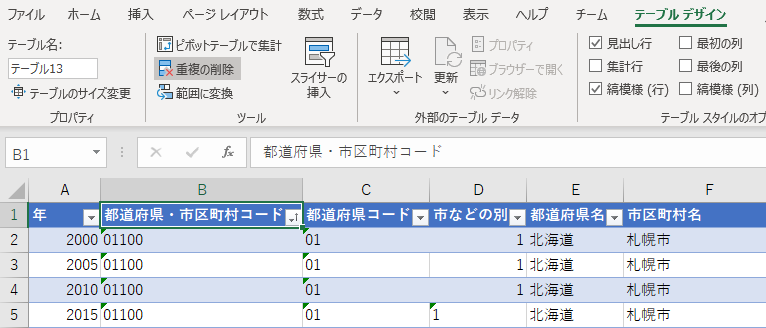
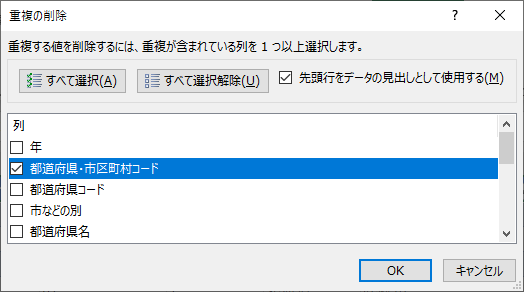
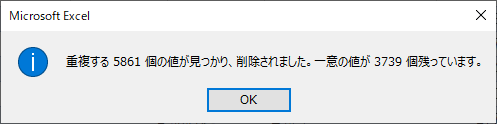
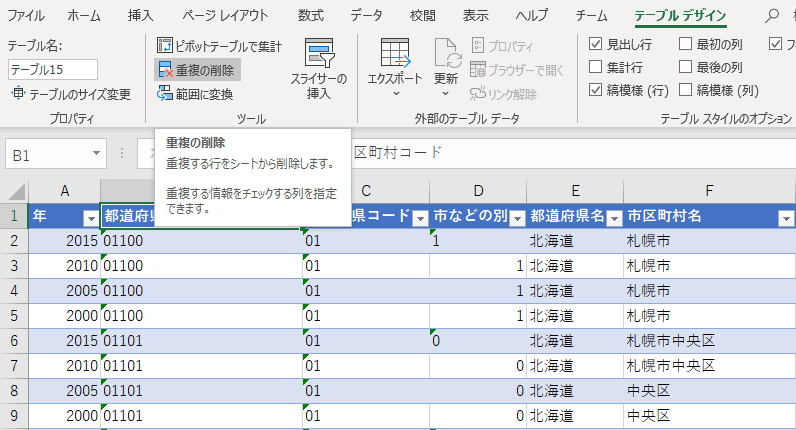
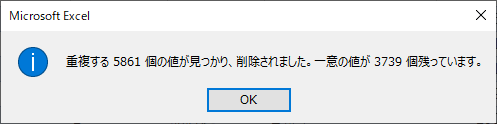
市区町村名に注意して結果を比較する
「年」を昇順でソートした場合は年が最小値のレコードが残り,「年」を降順でソートした場合は年が最大値のレコードが残った.
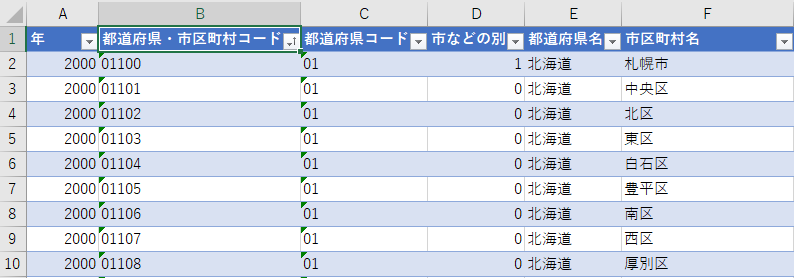
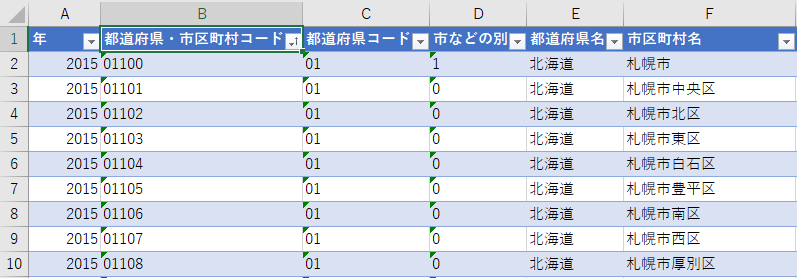
どちらが望ましい結果だろうか?俺は後者が良いと思う.市区町村名も一意の値に見えるからである.
「年」が最小値のレコードが残ったワークシート市区町村(2) を削除
最新の市区町村名を使いたいなら「年」が最大値のものを使うべきである.不要となったワークシートを削除しよう.ここでは市区町村(2) である.
シート名を市区町村マスターと変更する.
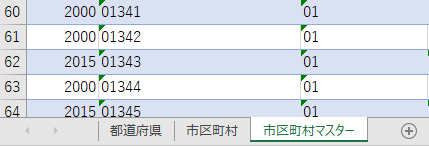
「市などの別」は行政区画の粒度
「市などの別」に 0 でフィルターをかけると 198 件が抽出される.フィルターを解除して「市区町村名」が「区で終わるテキストフィルター」をかけるとやはり 198 件が残り,その状態で「市などの別」のフィルターを見てみると値が 0 しかない.
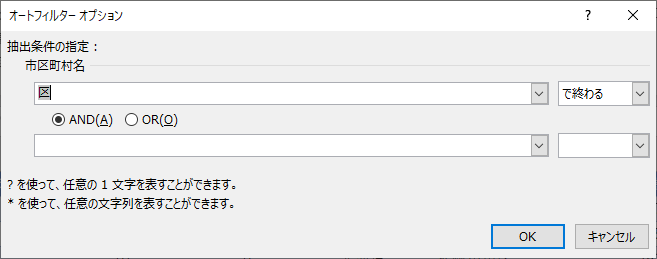
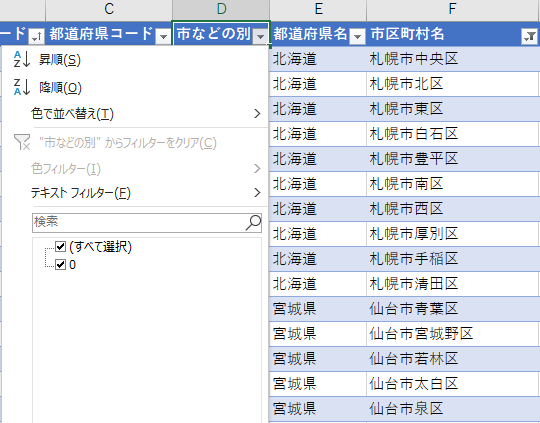
これもまた先程と同様,区のフラグであると分かる.面倒なのは東京都のみ,都と区の間に市がないことである.それ以外では道府県と区の間には市がある.
「市などの別」に 1 でフィルターをかけると 21 件が抽出される.ここまでの調査で見当がついていると思うが,このフラグは区の集合体としての市を意味しており,人口は集計行である.
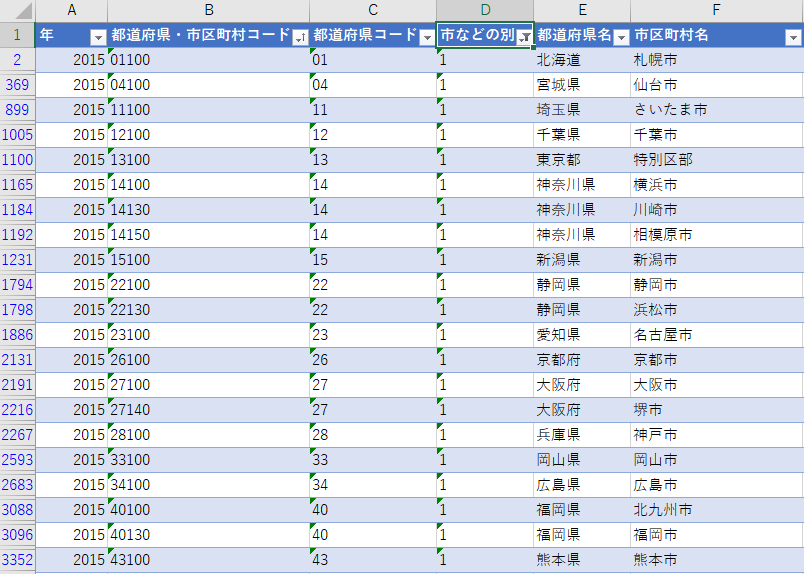
「市などの別」に 2 でフィルターをかけると 840 件が抽出される.これは一般の市を示すフラグであろう.
「市などの別」に 3 でフィルターをかけると 2680 件が抽出される.これは町村のフラグであろう.
「市などの別」は行政区画の粒度を示しており,値が 1 の場合は人口が集計値となるため,注意が必要である.散布図を描く際にはフィルターで外したほうが良いかも知れない.しかし,東京 23 区以外の市は一般には一つの行政単位として認識されており,識別が難しい.
結局,表現する目的によって使い分けるしかないという結論となる.ここではこのまま進めることにしよう.
地方区分の列を挿入する
EXCEL の制約として,グラフのデータ系列数の上限が 255 であることは知っておいたほうが良い.市区町村マスターのレコード数は 3739 件ある.これを全て一つの散布図に載せることは不可能だ.かと言って,都道府県別の散布図を作成するのはグラフの数が多すぎる.
そこで,全国を地方区分で分けることにする.具体的には北海道地方,東北地方,関東地方,中部地方,近畿地方,中部地方,四国地方,九州・沖縄地方である.
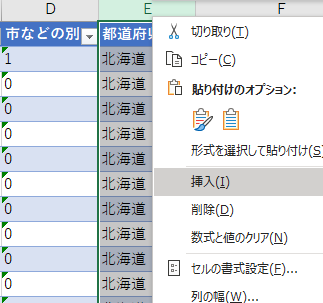
同じ地方区分の都道府県をチェックして地方区分名を入力する.
人口増減率を小数に変換する
データをよく見ると人口増減率の単位はパーセントになっている.散布図にする際に軸の表記が問題になるため,小数に変換しておく.
「人口増減率」の右隣に列を挿入する.
数式で=[@人口増減率]*0.01と入力する.[@Column] とは構造化参照による表記法であり,クリックだけで自動的に入力される.
![数式で[@人口増減率]*0.01と入力する](https://www.muscle-hypertrophy.com/wp-content/uploads/2019/08/91.png)
次はタイトルの入れ替えだ.元のタイトルを切り取る.
貼り付けると見かけは入れ替わるが,数式の参照関係がまだ残っている.
数式の参照関係を解消するのは「コピー」して「値のみ貼り付け」だった.
最後に元のJ列を削除して完了である.
散布図のデータ系列のためにソートを使い分ける
リレーショナルデータベースの観点からすれば,テーブル内のレコードの順序は関係がない.しかし,EXCEL の散布図に表現する時には留意したほうがよい.
複数の,というより多数のデータ系列を扱う際に,同じ系列のレコードが集まっていると便利である.そのためにソートを活用する.
先程は「市区町村マスター」で昇順のソートと降順のソートを使ったが,今度は「市区町村」で同様にソートする.
「年」を昇順でソートした後に「都道府県・市区町村コード」を昇順でソートする
まず「年」の列を昇順でソートする.
次に「都道府県・市区町村コード」を昇順でソートする.
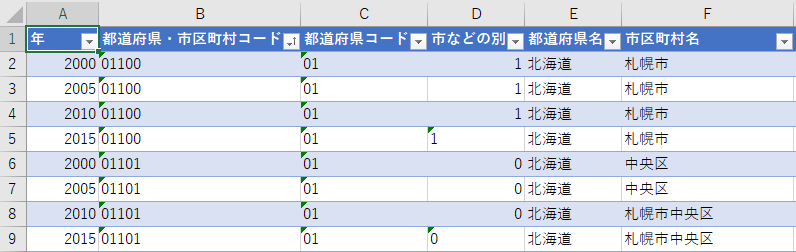
これで市区町村ごとに,時間の順番でレコードが集まる.これで散布図を描く準備が整った.
まとめ
総務省の都道府県・市区町村別統計表を元に,日本全国の市区町村の人口のテーブルを作成した.データクレンジングにはデータの本質にかかわる作業と,無関係の作業がある.
日本の官公庁のシステムは老朽化しており,数十年前のシステムを騙し騙し使い続けている状況である.官公庁のデータが使いにくいのはそのためだ.
しかし,データベースの整備を急ぐべきである.リレーショナルデータベースを基幹システムに導入し,データの再利用を促すべきだ.

“総務省の都道府県・市区町村別統計表をデータクレンジングする” への1件の返信