

先週の記事では SQL Server 2017 のデータベースエンジンをインストールした.今回は SQL Server Data Tools 2017 をインストールしたので備忘録を兼ねて公開する.
そもそも SQL Server Data Tools とは?
ごく大雑把に言うと,以前 Business Intelligence (BI) と呼ばれていた機能をいくつかのソフトウェアで実現できるようにしたサービスである.
リレーショナルデータベースではデータの構造に従って正規化という手続きを経て,データがテーブルに分解されて格納されているのであるが, Analysis Services でも Reporting Services でも,一旦正規化したテーブルを結合して再び第一正規形に戻した上でクエリを発行する.
レポートの際に第一正規形に戻すのなら,そもそも何でわざわざ正規化してテーブルに分解するのか?ここらへんの詳しい話はおいおいして行くとして,今はそういうものだと思ってほしい.情報の無損失分解,という話があるんだ.
インストール作業の実際
インストーラのダウンロード
こちらのサイトからインストーラをダウンロードする.ファイル名は SQLServer2017-SSEI-Dev である.
インストーラの起動
ダウンロードしたファイルをダブルクリックして起動する.
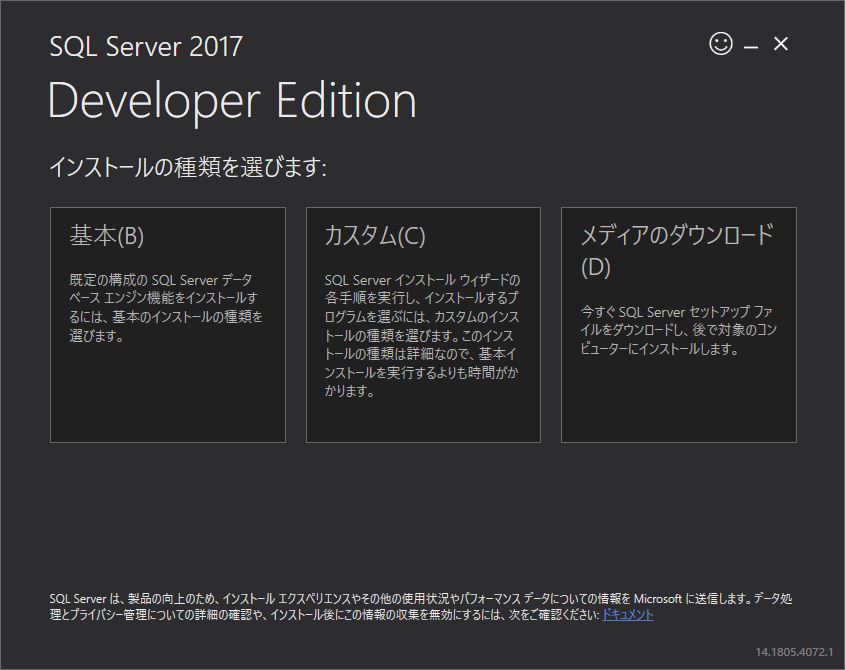
『カスタム』をクリックする.
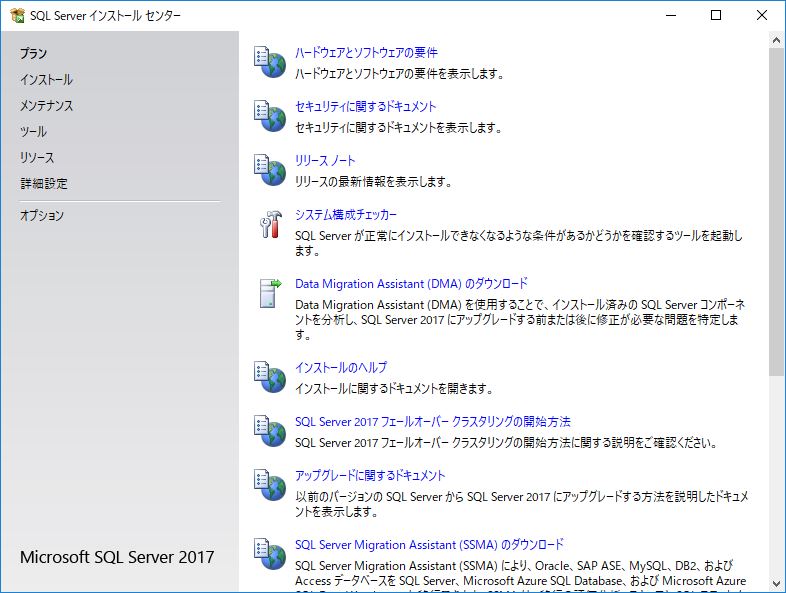
この画面を見ると複雑な気持ちになる.インストールだけで苦労した思い出が蘇る.だが,心配は杞憂だった.インスタンスの検出や管理者権限の設定などはほぼ自動化されているようで,ユーザーがいちいち手動で設定する必要はない.
左側のパネルに『プラン』,『インストール』,『メンテナンス』,『ツール』,『リソース』,『詳細設定』,『オプション』が並んでいる.『インストール』をクリックする.
SQL Server Data Tools のインストール
上から四番目,タイトル通りのメニューをクリックする.
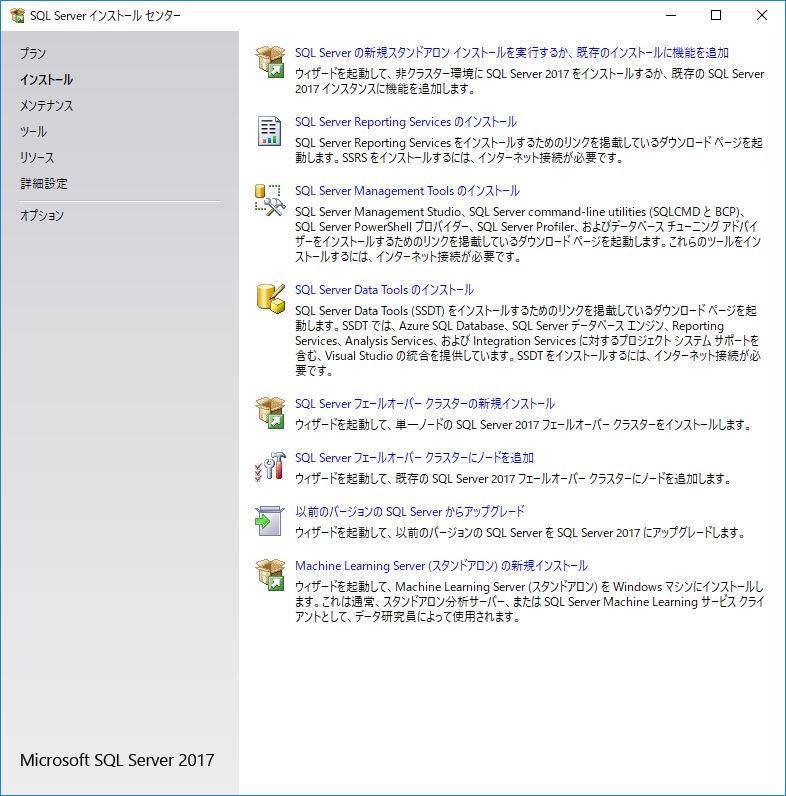
ブラウザからインストーラをダウンロードする
下記画像のサイトに飛ぶ.
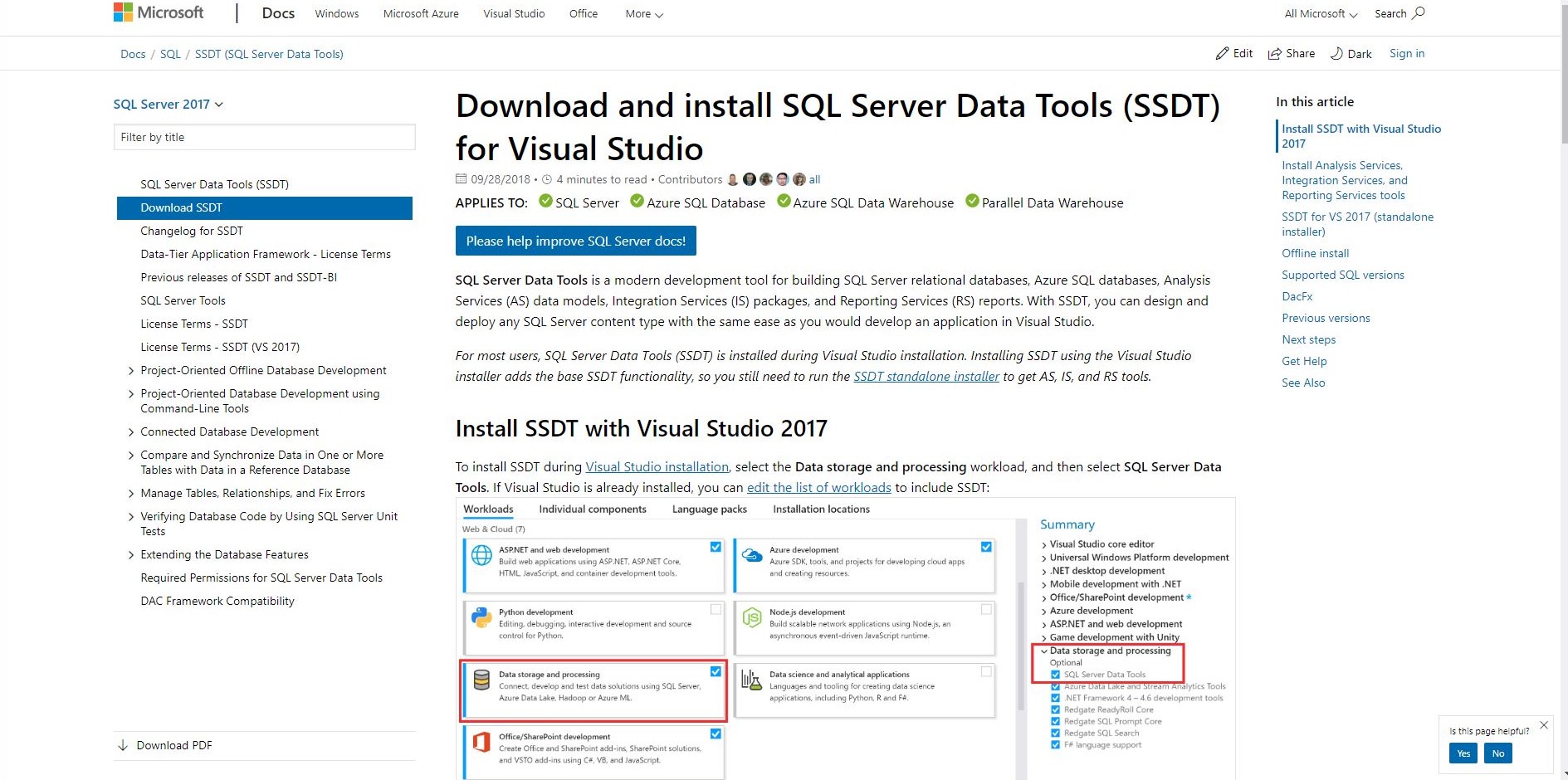
スクロールしていくと日本語版が出てくる.ファイル名は SSDT-Setup-JPN である.
SSDT のインストーラを起動する
ダウンロードフォルダに落ちてきたファイルをダブルクリックするとようやくインストーラが起動する.『次へ』をクリックして開始する.
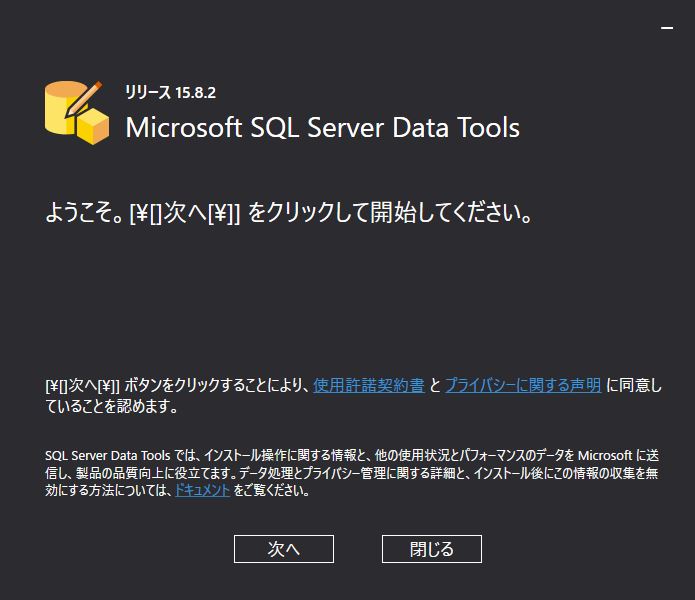
『インストール』をクリックして実際のインストール作業を開始する. SQL Server データベース, SQL Server Analysis Services, SQL Server Reporting Services, SQL Server Integration Services がインストールされるソフトウェアである.
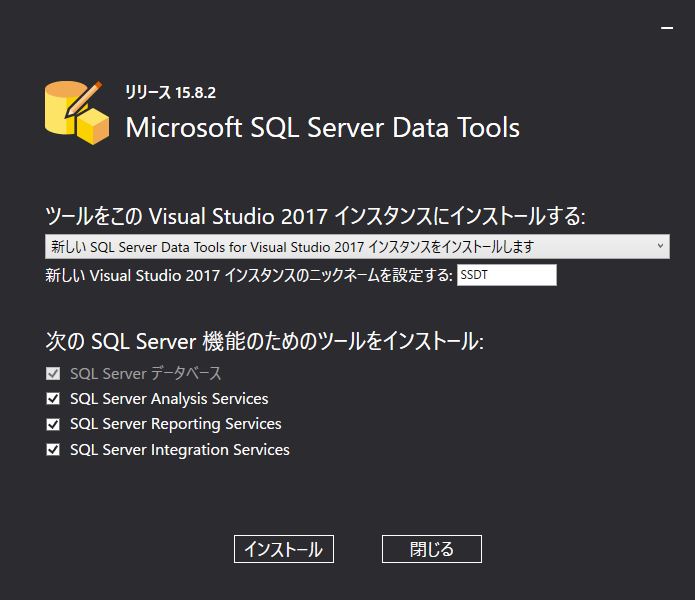
各ソフトウェアがまずダウンロードされ,次いでインストールされていく様子.この辺りも自動化されていてほとんどすることがない.所要時間は 1 時間ほどだった.
セットアップが完了すると下記画面のようになる.『閉じる』をクリックして終了すれば終わりだ.この後端末の再起動を要求された.
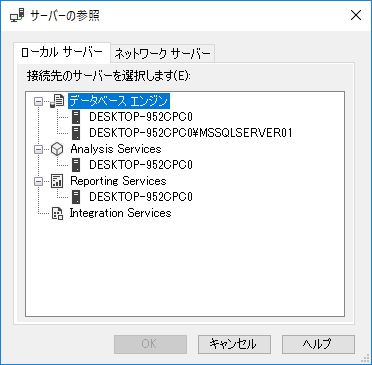
サーバーに接続する
Analysis Services にせよ Reporting Services にせよ,それぞれのサーバーに接続して処理を行うことになる.俺の環境ではインスタンスが二種類あり,下図のように MSSQLSERVER というインスタンスに紐付いてインストールされたようである.意図としては新しくインストールした MSSQLSERVER01 のインスタンスに紐付いてほしかったのだけど.一度まっさらな環境でインストールするしかないのだろう.
AI だのニューラルネットワークだの言う前にデータベースだろ
人工知能というバズワードが登場して久しい.これまでにもこういった用語は何度も登場し,期待感だけが先走ってやがて失望され,停滞するというサイクルが繰り返されてきた.こと日本における IT に関して言えば,先端技術の追求もやればいいと個人的には思っているが,基礎的な技術の普及が遅れているように思えてならない.
政府のシステムがダメ
具体的にはリレーショナルデータベースだ.まず,役所のシステムがもう壊滅的にダメだ.住民基本台帳がまったくなっていない.住民票を発行するくらいはコンビニでも出来るようにはなったが,それでも省をまたぐような処理となるともうダメだ.
猪瀬直樹も言っているが,日本の官僚は省益しか考えていない.それぞれの省が独自のシステムを構築していて相互接続できないというのは大きな問題だ.こういう縦割りの行政に風穴を開けていかないといけないのだが.

その最たる例が 2006 年頃から明らかになった年金記録の不備なのだが,日本人はもう忘れてしまっているようだ.社会保険庁の腐敗した運用が招いた事故ということになっているが,こういった問題は,最初からデータベースをきちんと設計して運用していれば防げた可能性がある.まともなデータベースを構築できる人材がいなかったのか.
年金時効特例法 (2007), 厚生年金特例法 (2007), 年金遅延加算金法 (2009), 年金延滞金軽減法 (2009) あたりを探してみると良いかも知れない.
ITインフラにカネを払わない日本人
計算機の性能がこれだけ上がっているのに,システムの刷新もまともに出来ていない.予算不足が言い訳だが,本当に日本人は情報に金を払う気がない.税金で作られたシステムなのだから,もっと議員をせっついてシステムの更新を促せば良いのに,老人の年金が巨大すぎて手付かずだ.このままでは役所の旧態依然たるシステムも更新されることなく,この国は経済的に没落し,やがてはシステムを維持する金もなくなっていくのだろう.
2000 年代の IT バブル時代は,もしかすると日本が IT 化する最後のチャンスだったかもしれなかった.あるいは,紙ベースで運用していた業務をそのまま電子化しただけの上っ面の改革で終わらせるのか.
日本人には哲学がない.哲学がないから個別最適化が金科玉条となって全体最適化がなされない.正に「木を見て森を見ず」となっている.
データベースは IT インフラすべての基礎だ
国は PEZY を潰して量子コンピュータに注力していくつもりのようだが,もっと基本的なシステムの刷新もやっていかないと,にっちもさっちも行かなくなることは目に見えている.人工知能にしても何にしても,学習データを蓄積するシステムの最も基礎となるのはデータベースなのだ.そこをなおざりにしていい訳がない.
人工知能の推論は統計解析を基本にしている.そして統計解析はデータベースと非常に相性がいい.データベースにおけるテーブルの正規化と,統計解析における多重共線性の排除とは全く別の概念だが,この二つは本質的に同じものだと俺は直感している.
人工知能も大事だが,データベースはもっと大事だ.