
Microsoft の公式サイト,英語なら取得は容易であるが,当然日本語は取得できない.今回は日本語サイトから英語と日本語の両者を取得しようと試みた.
結論から言うと,この記事で述べた方法で全ての日本語と英語とが分離できたわけではない.2 バイト文字と 1 バイト文字との分離という手法を用いたが,最終的には手動での対応が必要だった.
Power Query のユーザーインターフェース
『データの取得と変換』の『Web から』
『データの取得と変換』の『Web から』をクリックする.
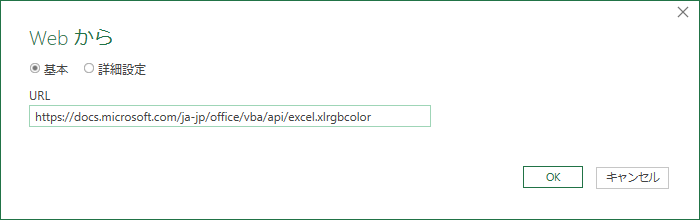
URLを貼り付け
URL を貼り付ける.
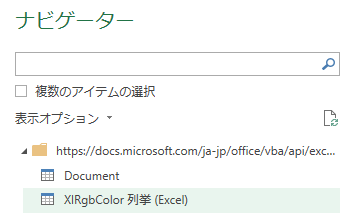
『ナビゲーター』ではテーブルを選択
ナビゲーターに遷移するので,フォルダーの階層下にあるうち,テーブルらしきアイコンを選択する.
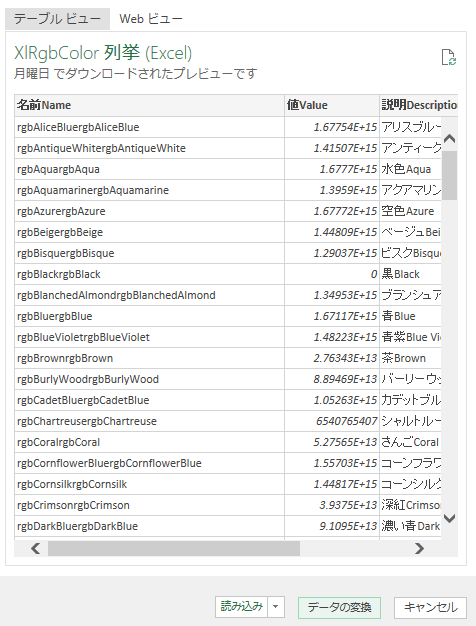
『データの変換』
『データの変換』をクリックする前に,よくプレビューを観察しよう.列は 3 列あり,列名はそれぞれ [名前Name], [値Value], [説明Description] である.このうち,[名前Name] と[値Value] とは同じ文字列が 2 回繰り返されている.
ここまで分かれば,前二者は文字列長を数えて半分の長さの文字列を切り出せば良いな,と見当がつく.
3 列目の [説明Description] が少々手こずる.前半が日本語,後半が英語である.間に半角スペースでもあれば簡単なのだが,そういう訳にも行かない.文字コードにまで踏み込む必要がありそうだ.
型の自動変換を削除して1ステップ戻る
Power Query の補完機能の一つ,型の自動変換は数字を扱う際に邪魔になることがある.今回のように最初は文字列として扱いたいので,『適用したステップ』で最後の『編集された型』を削除して文字列に戻す.
テキスト関数を使ってカスタム列に抽出
ワークシート関数の LEFT 関数に該当するのは Text.Middle 関数
EXCEL のテーブルなら LEFT 関数を使うが,M 言語の場合は Text.Middle 関数になる.文字列長をカウントするには Text.Length 関数である.こちらのサイトがわかりやすい.
まずカスタム列を追加
『列の追加』タブから『全般』の『カスタム列』をクリックする.
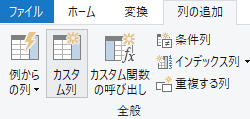
Text とタイプして関数の候補をポップアップさせる
『新しい列名』には Name とタイプし,『カスタム列の式』に Text とタイプすると,インテリセンスが働いて自動的に候補の関数がポップアップする.ここをスクロールして Text.Middle を選択する.
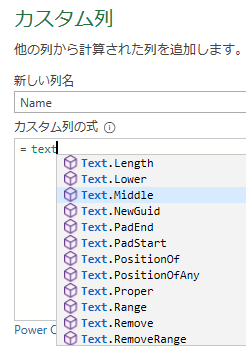
関数のネスト
さらに ( とタイプして引数のカッコを開き,Text とタイプして Text.Length 関数を選択する.
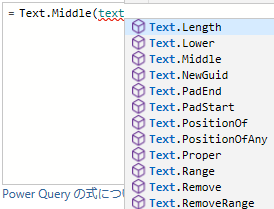
そして ( とタイプして引数のカッコを開き,[ とタイプすると今度は『使用できる列』がポップアップするので,[名前Name] を選択する.
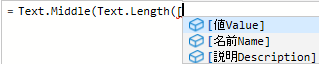
Text.Length 関数の結果を 2 で割る
重複削除のために文字列長を半分にしている.この後,図示してはいないが,Text.Middle 関数の引数に [名前Name], 0 を与えて式を完成している.
= Text.Middle([名前Name],0,Text.Length([名前Name])/2)
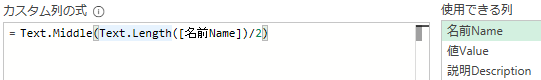
日本語と英語を分離するには文字コードに踏み込む
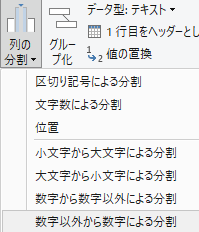
『列の分割』の最後4項目がヒント
『説明Description』列を選択した状態で『列の分割』を押下すると下図のような選択肢が出現する.『数字以外から数字による分割』を選択する.
上記処理の数式を数式バーで編集する.初期状態では下記コードのような状態である.
= Table.SplitColumn(変更された型, "説明Description", Splitter.SplitTextByCharacterTransition((c) => not List.Contains({"0".."9"}, c), {"0".."9"}), {"説明Description.1", "説明Description.2"})
1 バイト文字は下記コードで指定している.FromNumber 関数のカッコ内の引数は文字コードであり,ISO/IEC 8859 (Wikipedia)に詳しい.
{Character.FromNumber(0)..Character.FromNumber(255)}
= Table.SplitColumn(変更された型, "説明Description", Splitter.SplitTextByCharacterTransition((c) => not List.Contains({Character.FromNumber(0)..Character.FromNumber(255)}, c), {Character.FromNumber(0)..Character.FromNumber(255)}), {"説明", "Description"})
文字コードの歴史については,それだけで数記事が書けるくらいである.1 バイトは 7 ビットなのになぜ 255 まであるのかとか,今の筆者には答えられない.
この方法は Twitter のフォロワーの方に教えていただいた.
1バイト文字256字対応なら
— Yt-olt (@olt_yt) 2020年8月3日
{"!".."~"}
これを
{Character.FromNumber(0)..Character.FromNumber(255)}
こんな感じに書き換える感じ?
結果

エラーが 1 件見える.これは rgbBlack の値が .00 であることが原因であり,手動で直すほかない.もう一つ,下図のように LightGoldenrodYellow には日本語が存在しないため,英語のみ重複して記載されている.
実際に取得された結果を示す.重複が数件あるようだが,特に訂正はしていない.Value の数値は RGB() 関数で分解できる気がする.
Name Value 説明 Description rgbBlack 0 黒 Black rgbMaroon 128 栗色 Maroon rgbDarkRed 139 濃い赤 Dark Red rgbRed 255 赤 Red rgbOrangeRed 17919 オレンジレッド Orange Red rgbDarkGreen 25600 濃い緑 Dark Green rgbGreen 32768 緑 Green rgbOlive 32896 オリーブ Olive rgbDarkOrange 36095 濃いオレンジ Dark Orange rgbOrange 42495 オレンジ Orange rgbGold 55295 ゴールド Gold rgbLawnGreen 64636 若草色 Lawn Green rgbLime 65280 黄緑 Lime rgbChartreuse 65407 シャルトルーズ Chartreuse rgbYellow 65535 黄 Yellow rgbDarkGoldenrod 755384 濃いゴールデンロッド Dark Goldenrod rgbGoldenrod 2139610 ゴールデンロッド Goldenrod rgbFireBrick 2237106 れんが色 Fire Brick rgbForestGreen 2263842 フォレストグリーン Forest Green rgbOliveDrab 2330219 オリーブドラブ Olive Drab rgbBrown 2763429 茶 Brown rgbSienna 2970272 シェンナ Sienna rgbDarkOliveGreen 3107669 濃いオリーブグリーン Dark Olive Green rgbGreenYellow 3145645 グリーンイエロー Green Yellow rgbLimeGreen 3329330 ライムグリーン Lime Green rgbYellowGreen 3329434 イエローグリーン Yellow Green rgbCrimson 3937500 深紅 Crimson rgbPeru 4163021 ペルー Peru rgbTomato 4678655 トマト Tomato rgbDarkSlateGray 5197615 濃いスレートグレー Dark Slate Gray rgbDarkSlateGrey 5197615 濃いスレートグレー Dark Slate Grey rgbCoral 5275647 さんご Coral rgbSeaGreen 5737262 シーグリーン Sea Green rgbIndianRed 6053069 インディアンレッド Indian Red rgbSandyBrown 6333684 サンディブラウン Sandy Brown rgbDimGray 6908265 ディムグレー Dim Gray rgbDimGrey 6908265 ディムグレー Dim Grey rgbDarkKhaki 7059389 濃いカーキ Dark Khaki rgbPaleGoldenrod 7071982 ペールゴールデンロッド Pale Goldenrod rgbMidnightBlue 7346457 ミッドナイトブルー Midnight Blue rgbMediumSeaGreen 7451452 淡いシーグリーン Medium Sea Green rgbSalmon 7504122 サーモンピンク Salmon rgbDarkSalmon 8034025 濃いサーモンピンク Dark Salmon rgbLightSalmon 8036607 薄いサーモンピンク Light Salmon rgbSpringGreen 8388352 スプリンググリーン Spring Green rgbNavy 8388608 ネイビー Navy rgbNavyBlue 8388608 ネイビーブルー Navy Blue rgbPurple 8388736 紫 Purple rgbTeal 8421376 青緑 Teal rgbGray 8421504 灰色 Gray rgbGrey 8421504 灰色 Grey rgbLightCoral 8421616 薄いさんご Light Coral rgbIndigo 8519755 インディゴ Indigo rgbMediumVioletRed 8721863 淡いバイオレットレッド Medium Violet Red rgbBurlyWood 8894686 バーリーウッド Burly Wood rgbDarkBlue 9109504 濃い青 Dark Blue rgbDarkMagenta 9109643 濃いマゼンタ Dark Magenta rgbDarkSlateBlue 9125192 濃いスレートブルー Dark Slate Blue rgbDarkCyan 9145088 濃いシアン Dark Cyan rgbLightCyan 9145088 明るい水色 Light Cyan rgbTan 9221330 タン Tan rgbKhaki 9234160 カーキ Khaki rgbRosyBrown 9408444 ローズブラウン Rosy Brown rgbDarkSeaGreen 9419919 濃いシーグリーン Dark Sea Green rgbSlateGray 9470064 スレートグレー Slate Gray rgbLightGreen 9498256 明るい緑 Light Green rgbDeepPink 9639167 深いピンク Deep Pink rgbPaleVioletRed 9662683 ペールバイオレットレッド Pale Violet Red rgbPaleGreen 10025880 ペールグリーン Pale Green rgbLightSlateGray 10061943 薄いスレートグレー Light Slate Gray rgbMediumSpringGreen 10156544 淡いスプリンググリーン Medium Spring Green rgbCadetBlue 10526303 カデットブルー Cadet Blue rgbDarkGray 11119017 濃い灰色 Dark Gray rgbDarkGrey 11119017 濃い灰色 Dark Grey rgbLightSeaGreen 11186720 薄いシーグリーン Light Sea Green rgbMediumAquamarine 11206502 淡いアクアマリン Medium Aquamarine rgbNavajoWhite 11394815 ナバホホワイト Navajo White rgbWheat 11788021 小麦 Wheat rgbHotPink 11823615 ホットピンク Hot Pink rgbSteelBlue 11829830 スチールブルー Steel Blue rgbMoccasin 11920639 モカシン Moccasin rgbPeachPuff 12180223 ピーチパフ Peach Puff rgbSilver 12632256 銀色 Silver rgbLightPink 12695295 薄いピンク Light Pink rgbBisque 12903679 ビスク Bisque rgbPink 13353215 ピンク Pink rgbDarkOrchid 13382297 濃いオーキッド Dark Orchid rgbMediumTurquoise 13422920 淡いターコイズ Medium Turquoise rgbMediumBlue 13434880 淡い青 Medium Blue rgbSlateBlue 13458026 スレートブルー Slate Blue rgbBlanchedAlmond 13495295 ブランシュアーモンド Blanched Almond rgbLemonChiffon 13499135 レモンシフォン Lemon Chiffon rgbTurquoise 13688896 ターコイズ Turquoise rgbDarkTurquoise 13749760 濃いターコイズ Dark Turquoise rgbLightGoldenrodYellow 13826810 LightGoldenrodYellowLightGoldenrodYellow rgbDarkViolet 13828244 濃い紫 Dark Violet rgbMediumOrchid 13850042 淡いオーキッド Medium Orchid rgbLightGray 13882323 薄い灰色 Light Gray rgbLightGrey 13882323 薄い灰色 Light Grey rgbAquamarine 13959039 アクアマリン Aquamarine rgbPapayaWhip 14020607 パパイヤホイップ Papaya Whip rgbOrchid 14053594 オーキッド Orchid rgbAntiqueWhite 14150650 アンティークホワイト Antique White rgbThistle 14204888 あざみ色 Thistle rgbMediumPurple 14381203 淡い紫 Medium Purple rgbGainsboro 14474460 ゲーンズボロ Gainsboro rgbBeige 14480885 ベージュ Beige rgbCornsilk 14481663 コーンシルク Cornsilk rgbPlum 14524637 プラム Plum rgbLightSteelBlue 14599344 薄いスチールブルー Light Steel Blue rgbLightYellow 14745599 明るい黄 Light Yellow rgbRoyalBlue 14772545 ロイヤルブルー Royal Blue rgbMistyRose 14804223 ミスティローズ Misty Rose rgbBlueViolet 14822282 青紫 Blue Violet rgbLightBlue 15128749 明るい青 Light Blue rgbPowderBlue 15130800 パウダーブルー Powder Blue rgbLinen 15134970 リネン Linen rgbOldLace 15136253 オールドレース Old Lace rgbSkyBlue 15453831 スカイブルー Sky Blue rgbCornflowerBlue 15570276 コーンフラワーブルー Cornflower Blue rgbMediumSlateBlue 15624315 淡いスレートブルー Medium Slate Blue rgbViolet 15631086 紫色 Violet rgbPaleTurquoise 15658671 ペールターコイズ Pale Turquoise rgbSeashell 15660543 シーシェル Seashell rgbFloralWhite 15792895 フローラルホワイト Floral White rgbHoneydew 15794160 ハニーデュー Honeydew rgbIvory 15794175 アイボリー Ivory rgbLavenderBlush 16118015 ラベンダーブラッシュ Lavender Blush rgbWhiteSmoke 16119285 ホワイトスモーク White Smoke rgbLightSkyBlue 16436871 薄いスカイブルー Light Sky Blue rgbLavender 16443110 ラベンダー Lavender rgbSnow 16448255 スノー Snow rgbMintCream 16449525 ミントクリーム Mint Cream rgbBlue 16711680 青 Blue rgbFuchsia 16711935 明るい紫 Fuchsia rgbDodgerBlue 16748574 ドジャーブルー Dodger Blue rgbDeepSkyBlue 16760576 深いスカイブルー Deep Sky Blue rgbAliceBlue 16775408 アリスブルー Alice Blue rgbGhostWhite 16775416 ゴーストホワイト Ghost White rgbAqua 16776960 水色 Aqua rgbAzure 16777200 空色 Azure rgbWhite 16777215 白 White