
文部科学省には日本標準食品成分表のデータがある.食品の栄養素の計算に用いられるデータで,食品成分データベースやフィットネス,ダイエット関連アプリのデータベースの基本となっているものである.
このデータは 5 年ごとに更新されており,最新のデータは 2015 年のものである.次の更新は 2020 年の予定である.今回の記事ではこのデータをダウンロードし,クレンジングを行う.
ファイルをダウンロードする
データはこのページにある.2015 年版から PDF だけではなく EXCEL でも提供されるようになった.需要が多かったのだろう.ファイルは以下の3つである.日本語版はもう一段深い階層にある.
- 1369255_2.xlsx
- 1365334_1r12.xlsx
- 1374049_1r12.xlsx
EXCELで開いてみる
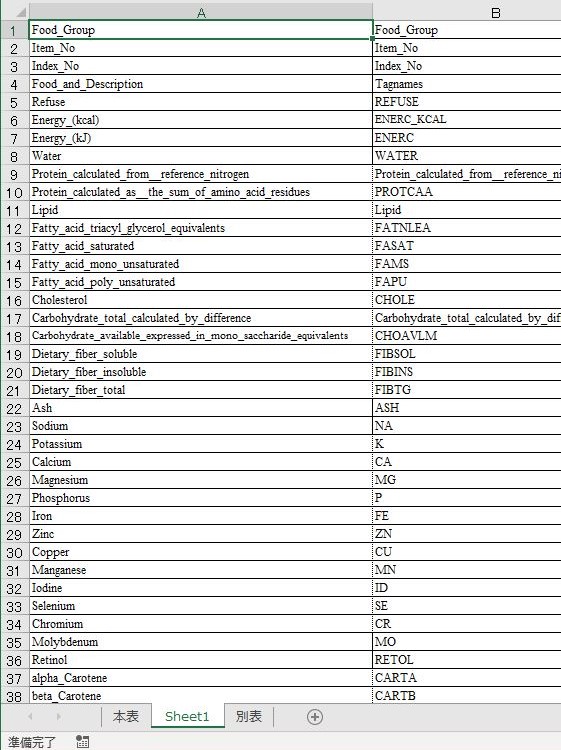
上記ファイルを EXCEL で開く.1369255_2 は成分表・アミノ酸成分表・脂質成分表・炭水化物成分表にそれぞれ記載があるかのサマリー,1365334_1r12 は日本語の成分表,1374049_1r12 は英語の成分表である.

上図は日本語版である.食品群ごとにファイルが分割されているが,ダウンロードする際には一括ダウンロード一択だ.

データ数は約13.5万件
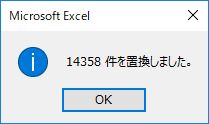
データのみで列数は 62 列,行数は 2192 行である.乗算すると 135,904 件.このうちハイフンは 35,963 件 (26 %), Tr は 3,092 件 (2.3 %), () で囲まれた数字が 14,358 件 (10.6 %) ある.
この割合が多いと見るか少ないと見るかは人によるが,これだけの成分を定量するために必要な資金と労力がどれほどのものかは想像に難くない.
しかし我々はそのデータをありがたく使わせてもらうことにしよう.
データクレンジングを行う
実はデータクレンジングが最も手間と時間のかかる作業である.普段は無意識に行っているため,改めて意識に上ることはなかったのだが,ちょうどよい機会なので文書化しておく.
データクレンジングとは?
データベースの読み込める形式にデータを整形することである.専門用語では第一正規形にするという.
ファイル形式は?
一般的には .csv ファイルの形になる.一行目がタイトルであり二行目からが実際のデータとなる.
どんなソフトで行うのか?
EXCEL が一般的だろう.データ数は 2198 件.手作業で扱える量ではない.フィルターや置換機能があるため,これらを活用してデータを整形していくことになる.
具体的な手順は?
- タイトル行を一行に集約する
- タイトルの項目名に重複を作らない
- データに空欄を作らない
- 数値型と文字列型を同じ列に入れない
- セル結合は解除する
書いてしまえば簡単だが,これがとても難しい.データの階層が分かっていないと苦労する.データの階層はテーブルを関数従属性に従って正規化する際に必要になってくる.
具体的に実際のデータを見てみよう.

5 行目から 8 行目までがタイトル行だが,実際にタイトル行になりうるのは 6 行目または 7 行目だけだと分かるだろうか? 8 行目はそもそも単位であり,タイトルにすらなりえない.
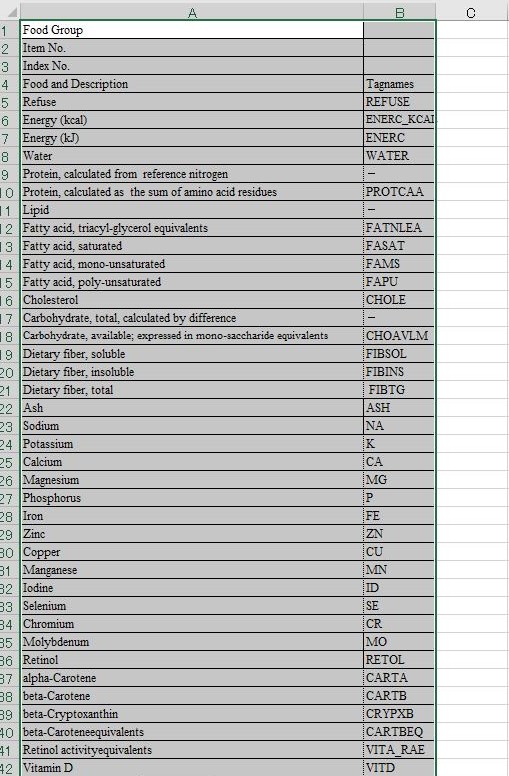
データベースソフトでは日本語も扱えるが,実際のところ,クエリエディタでキーボードから入力するのは英語のほうが扱いやすい.そこで英語ファイルの方からタイトルを取ってこよう.

英語ファイル 1374049_1r12 を開き,セル A6:BO6 を選択してコピーする.日本語ファイル 1365334_1r12 の同範囲に貼り付ける.

セル「すべてを選択」して右クリックし「セルの書式設定」を選択する.
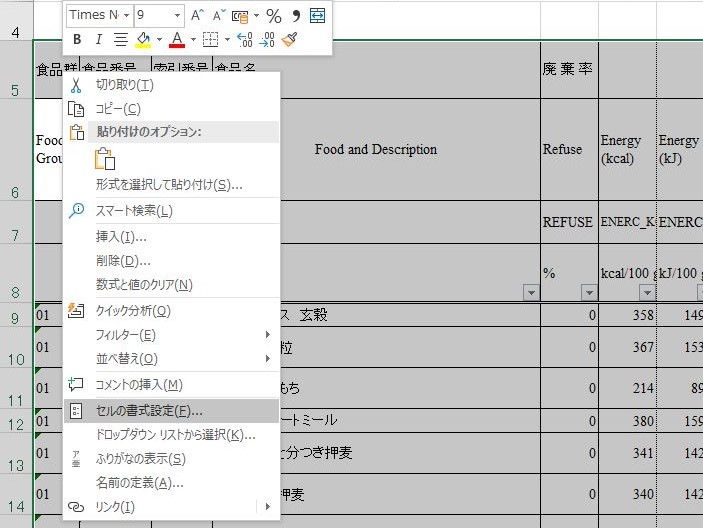
下図のように「配置」タブを設定する.
「横位置」は「標準」にする.
「文字の制御」は「折り返して全体を表示する」と「縮小して全体を表示する」を共にチェックをオフにする.「セルを結合する」のチェックがオフになっていることを確認する.
いくつかのセルの左上にエラーが表示されているが気にしないこと.数値型のデータが文字列で表示されているという意味だ.
不適切な文字を置換する
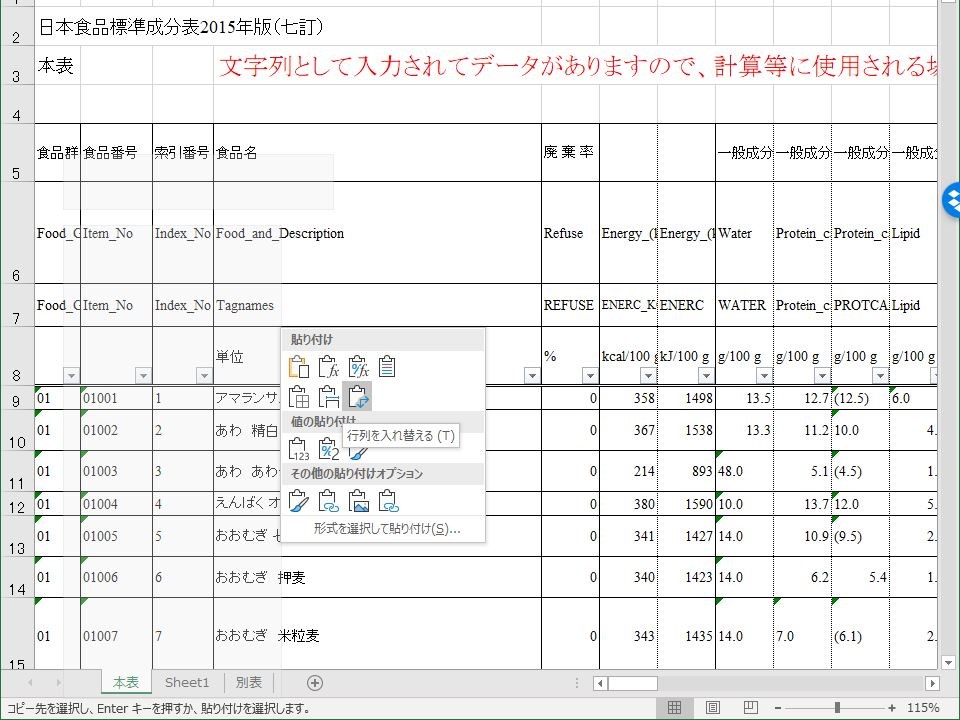
セル A6:BO7 をコピーし,ワークシートを追加して「形式を選択して貼り付け」から「行列を入れ替える」オプションで貼り付ける.
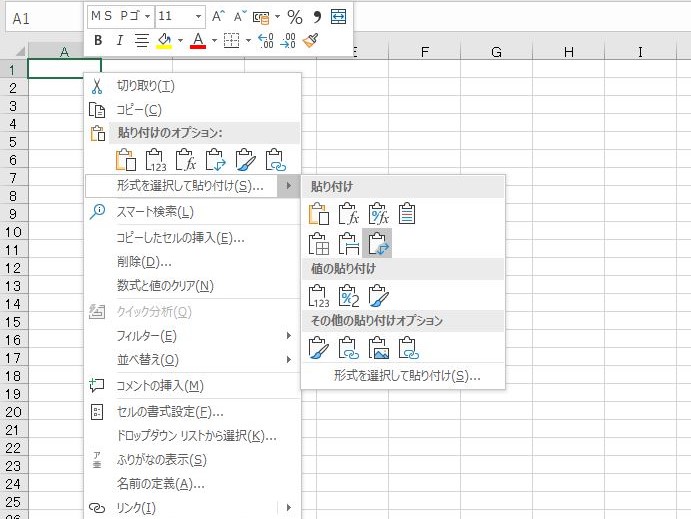
列 A と列 B の境界をダブルクリックすると列 A が広がる.A 列をタイトル項目に用いるか, B 列を用いるか吟味する.フルスペルがよいなら A 列だろうし,簡略化した方が好みなら B 列ということになる.
余談だが,この簡略化した略称はファイルを作成した人の好みが出るようだ.傍目からでは何が書いてあるのか分からない.本人が識別できればよいのかも知れないが.
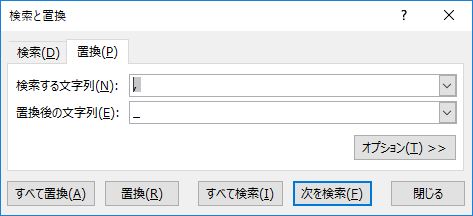
注意すべきはコンマとスペースの扱いだ..csv ファイルではコンマとスペースはデリミタとして扱われるため,残しておくと後でハマることがある.削除するか,別の文字列に置換しておいたほうがよい.俺がよく使うのは半角のアンダーバーだ.同様にハイフンも置換する.
置換の順序にも注意が必要だ.「長い文字列から先に置換する」という原則を覚えておこう.ここでは「コンマとスペース」,「スペース」,「ハイフン」の順序で置換することになる.
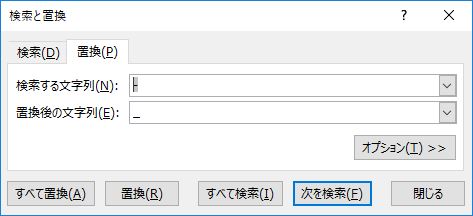
セル内の改行を削除する
データクレンジングはこれで終わりではない.「セル内の改行」という見えない敵が残っている.これも置換で削除できる.
下図をよく見てほしい.数式バー内で改行が行われている.これは見えない改行コードが挿入されていることを示している.

これを削除したい.どうすればよいか?答えは「検索する文字列」に「Control+J」とタイプする,である.
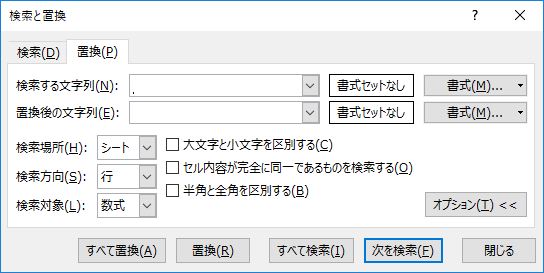
「置換後の文字列」には何も入力しない.これで「すべて置換」する.
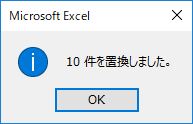
数式バーを見てみよう.
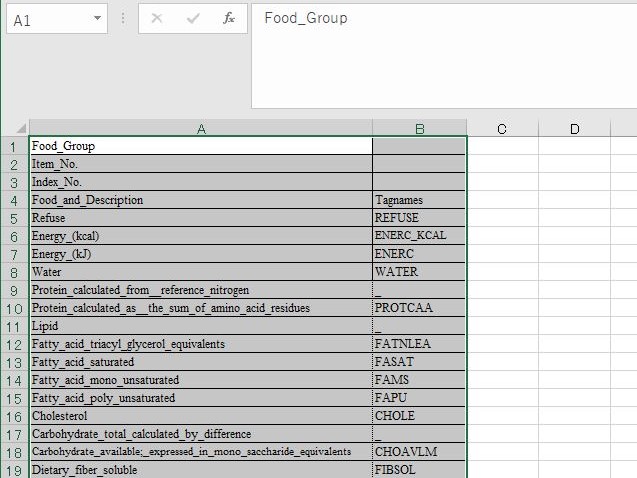
確かに数式バー内でも改行コードが削除されたのが分かる.もう少しだ.頑張ってついてきて欲しい.
危険な文字を削除する
危険な文字?何のことだ?と思われたかも知れない.上図のセル A18 内に半角セミコロンがあるのが分かるだろうか?
詳細は省略するが,データベースへの代表的な攻撃法として SQL インジェクションがある.攻撃者はクエリ内にデータベースの制御文字を紛れ込ませることで,データベースから本来取得できない情報を取得しようとする.半角セミコロンはその代表的な文字なのである.
今どきのデータベース管理ソフトはそこまでバカではないと思うが,データとして登録しようとする文字に半角セミコロンがあったら,削除しておいたほうがよい.クエリが予想外のエラーを返すかも知れない.
このファイルを作成した人は,そんなところまで考慮しているのだろうか?
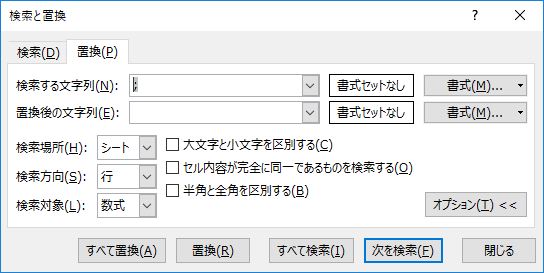
手作業は最後の手段だ
ここまでくれば後は細かい作業のみになる.念のためピリオドも削除しておこう.文字列の先頭や最後尾に半角のアンダーバーがある場合は手動で削除する.
人間の認知能力には限界がある.できるだけ検索・置換に頼るべきだ.手作業は最後の手段と心得よう.
Tagnamesか,フルスペルか?タイトルの項目名を吟味する
B 列の空欄に隣のセルから値をコピーする.半角のアンダーバーのみのセルも同様だ.A 列を選ぶか B 列を選ぶかはお好み次第だが,モニタが広いならフルスペルを,狭いなら略称を選ぶとよいかも知れない.
タイトルを書き戻す
セル A1:B67 を選択し,ワークシート「本表」の A6 を選択して行列を転値して貼り付ける.
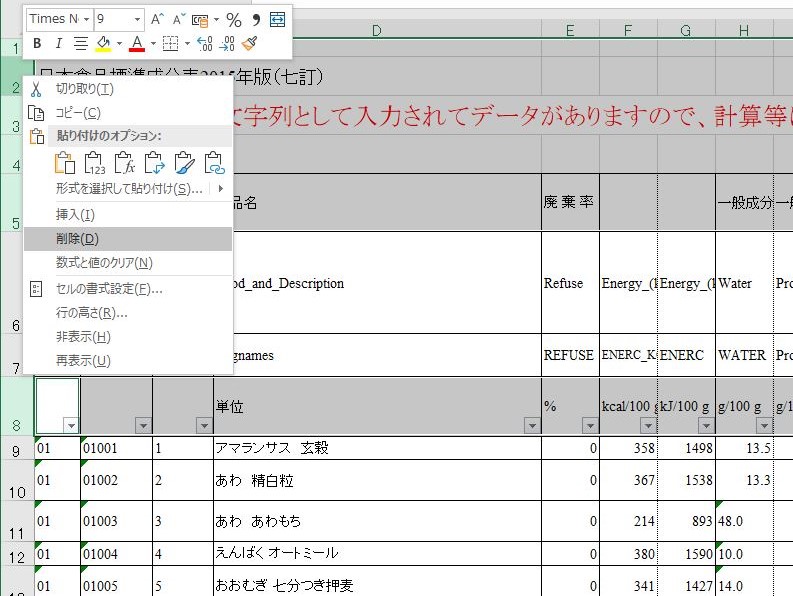
不要な行を削除する
行 1-5, 行 7, 8 を選択して削除する.
ワークシートをテーブルに変換する
データのあるセルを選択した状態で「挿入」タブの「テーブル」から「テーブル」をクリックする.
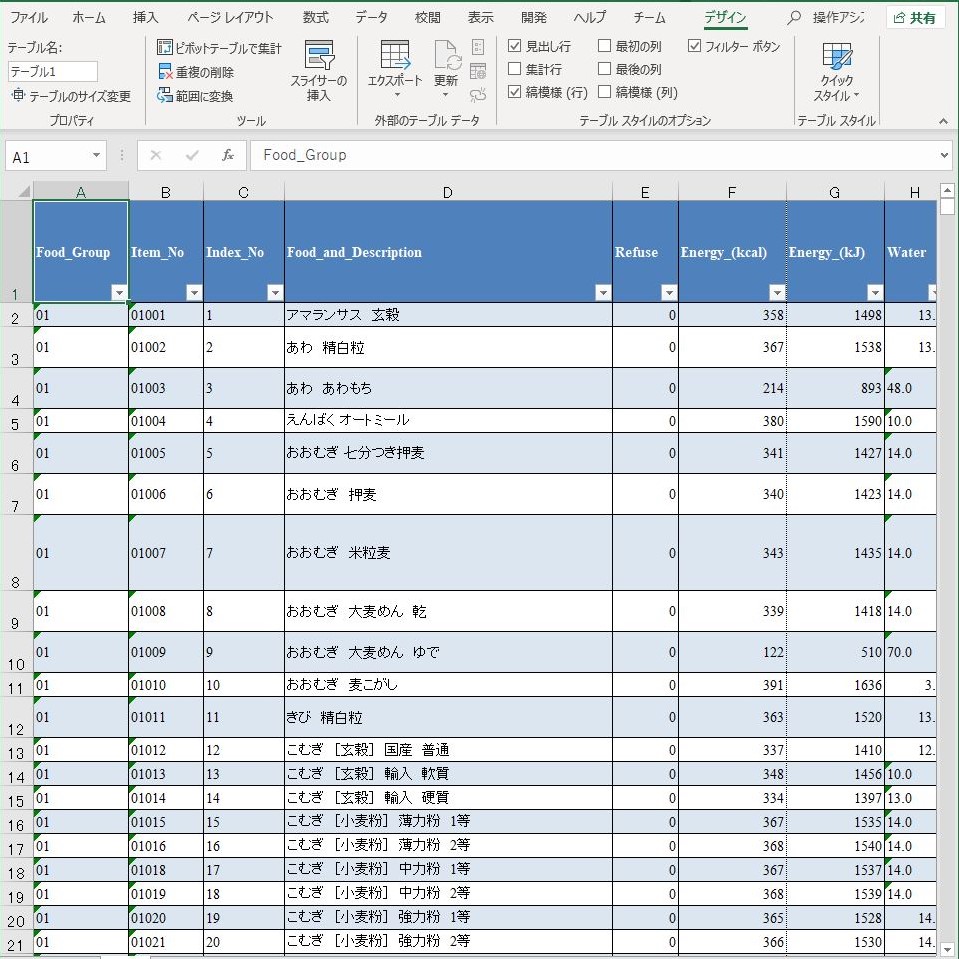
ワークシートがテーブルに変換された.ここまで来たら,いよいよデータ本体の整形に入る.
データクレンジング
クレンジングと言っても,基本は置換だ
身構える必要はない.ワークシートをテーブルに変換した時点でツールは揃っている.一行目はタイトル行になっており,フィルターが自動的に適用されている.
基本的に数値型のデータであることに留意しよう.しかし,フィルターを見ていくと,本来は数値型でないといけないのに,少なからず文字列型のデータが書き込まれているのが分かる.
具体例でいうと,カッコで囲まれた数字,「Tr」などのエラーを示す文字列,ハイフンなどである.
これら文字列型のデータを数値型に変換していく作業が必要になる.これがデータクレンジングの真髄だ.
俺は以前,2010 年版の日本標準食品成分表をデータクレンジングしたことがある.その際これらの文字列は一括してゼロに置換することにした.
一つだけ注意が必要だ.最後の列, BO 列の Yield だが,これは調理後の重量変化率を示している.主に水分を含んだ後の重量の増減だ.計算の際に必要になるかも知れない.これだけはデフォルトの値を 100 % にしておいたほうがよいと最初は思っていた.だが,後で考えが変わった.
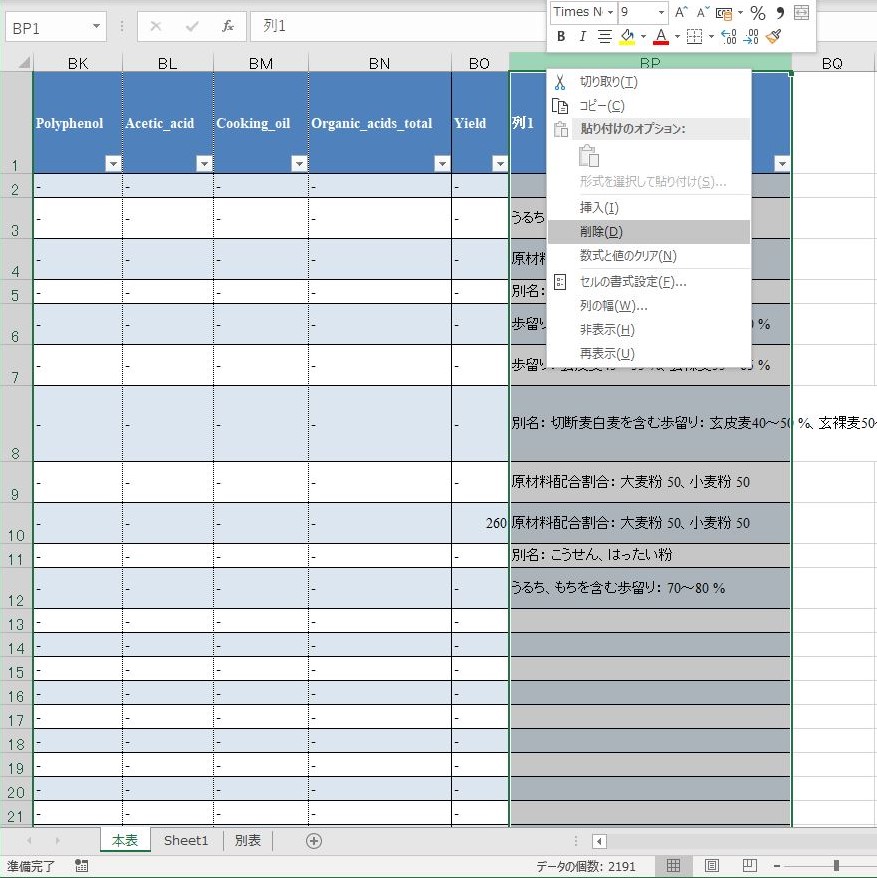
不要な列を削除する
Yield の右隣, BP 列のことである.これは備考欄であり,削除しよう.
オートフィルターでデータを閲覧する
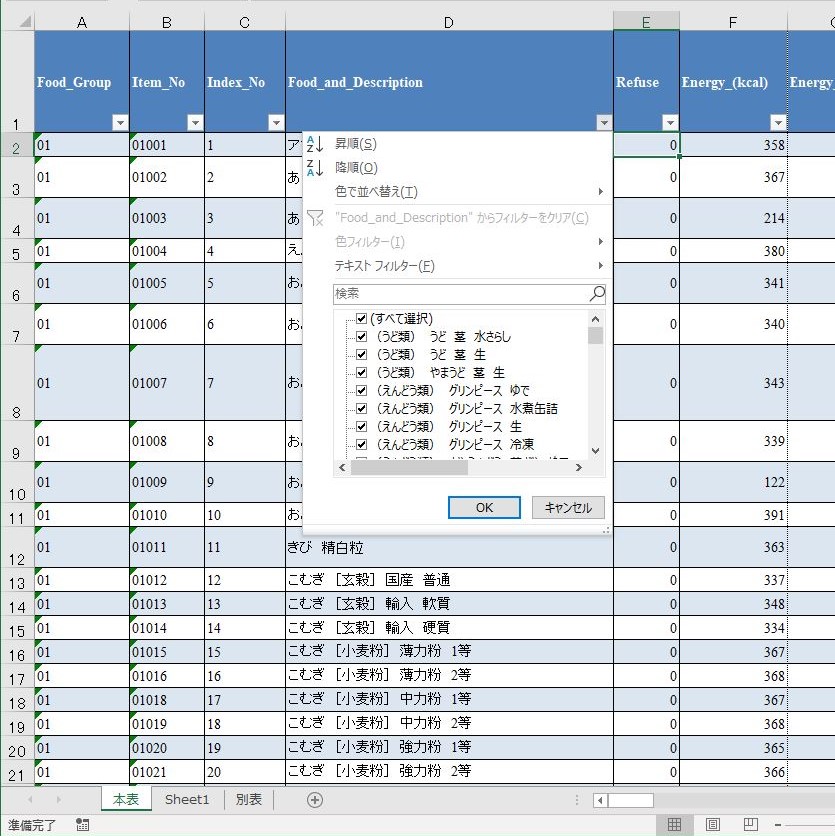
テーブルの 1 行目はタイトルであるが,これはフィルターの検索ボックスをも兼ねている.セルの右下に下向き三角のついたボタンがあるが,これがそうである.
このボタンを押すと,その列のすべてのデータが重複を排除された状態でポップアップする.しかも自動で昇順にソートされている.初期状態では(すべて選択)にチェックが入っており,すべての項目にチェックが入っている.このチェックをオン・オフすることでフィルター機能が提供される.
空白のセルを探せ!
ここまでの操作では幸運なことに空白のセルは見当たらない.しかし,一般的にデータクレンジングで最も問題になるのは空白のセルだ.EXCEL における空白のセルとはデータベースにおける NULL に該当する.
NULL が問題になるのは計算においてだ.加減乗除だけでなくありとあらゆる関数の結果に悪影響を及ぼす.1 + NULL = NULL などということが平気で起こる.計算式にたった一つの NULL が紛れ込むだけで,その計算は台無しになってしまう.
データベースの列の定義に NULL を許可しないという方針はそのためだ.リレーショナルデータベースにおいて NULL は最大のリスクである.
なぜそこまで NULL に対して神経質になるのか?そう思ったかも知れない.現実世界では「分からない」ことなど無数にある.分からないことを分からないままにしておいて,何が悪いのか?
データベースは事実の集合だからである
大事なことなのでもう一度書く.データベースは事実のみの集合だからである.データベースには事実以外の情報はない.もし事実以外の情報が存在すれば,そこからデータベースの崩壊が始まる.たとえ今問題にならなくても,いずれその問題は顕在化してプロジェクトは破綻するだろう.
データクレンジングの段階で空白のセルに対する方針を決める.数値ならゼロと置換するか,あるいは NULL を許容して空白のままとするか.個人的には NULL は許可したくない.
数値に紛れ込んだ文字列を探せ!
次に問題になるのは,本来は数値であるべき列に文字列が紛れ込んでいる場合だ.
食品成分表のファイルには様々な意味が込められている.しかし,データベースにインポートする目的は栄養素の計算のためだ.数値で定義した列に文字が入り込むとインポートそのものがエラーで停止する.
これはリレーショナルデータベースの限界でもある.データ型を厳密に定義するがゆえの宿命だ.だからこそ集合論と述語論理をベースとして,厳密な論理演算が可能となるのだが.
カッコつきの数字,エラーの意味を示した文字.そういったものをすべて数値に変換する.カッコは外し,エラーはゼロとする.
重量変化率の列は別に扱う
例外は BO 列の重量変化率だ.フィルターで見ると最後にハイフンがある.たとえば,最初の項目であるアマランサスの玄穀.玄穀をそのまま食べることはないからハイフンにしてあるのだが,データベースにインポートする際には支障になる.これをどう扱うか.
結論から言うと,この列は左外部結合してできた列であるため,どうしても NULL が生み出されてしまう.ならば,別のテーブルとして切り離したほうが好都合だ.具体的な扱いについては後で述べる.
カッコつきの数字のカッコを削除せよ
セル範囲の選択方法
ここでのコツは選択範囲だ.タイトルの文字列にあるカッコを削除してしまわないようにデータ範囲だけを選択する.具体的な手順を示す.
- セル E2 をクリックして選択する
- Control キー,Shift キーを押しながら右矢印キーを押す
- そのまま Control キーと Shift キーを押しながら下矢印キーを押す
まずは検索だ
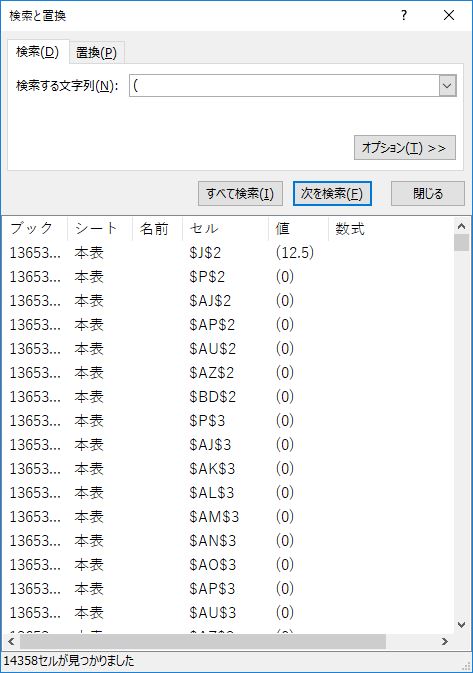
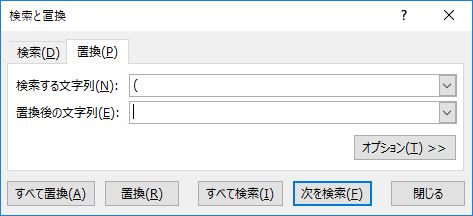
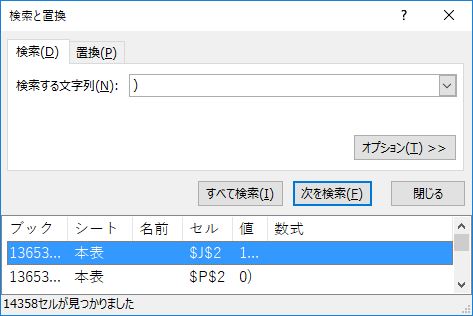
上記の状態のまま, Control+F キーで検索ウィンドウを開く.「検索する文字列」に ( とタイプし,「すべて検索」をクリックする.
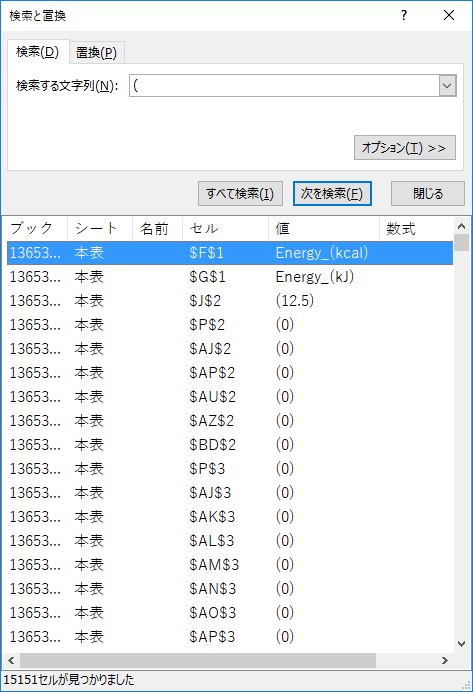
この状態でさらにもう一度「すべて検索」するとワークシート全体が検索の対象となり,その結果見つかるセルが増える.しかしこれは本意ではない.上述した「セル範囲の選択方法」どおりに選択し直そう.
これは少々分かりづらい EXCEL の仕様だ.
- 選択されたセルが一つの場合は,シート全体が検索対象になる
- 選択されたセルが複数の場合は,その範囲が検索対象になる
削除とは空白文字列に置換すること
これまでの作業でわかったと思うが,ある文字列を削除するとは「置換後の文字列」に何も入力せずに置換することである.
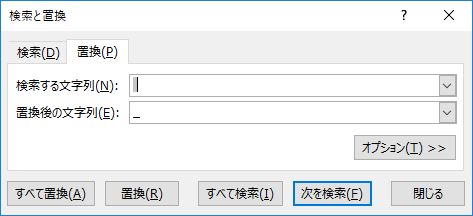
作業を進めよう.セル範囲 E2:BO2192 を選択し,下図のように「すべて置換」する.
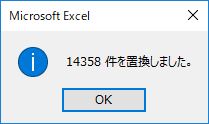
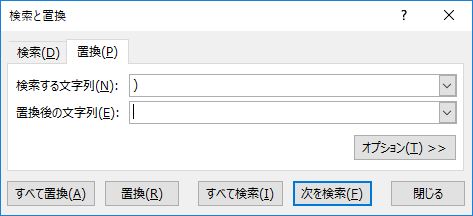
閉じカッコを削除する前に,閉じ括弧の数を確認する.確認後はセル範囲を選択し直すこと.
重量変化率の列は別のワークシートに移動する
先述したように,重量変化率の列は別テーブルに切り離したほうがよい.ここでは,別のワークシートに移動することにする.
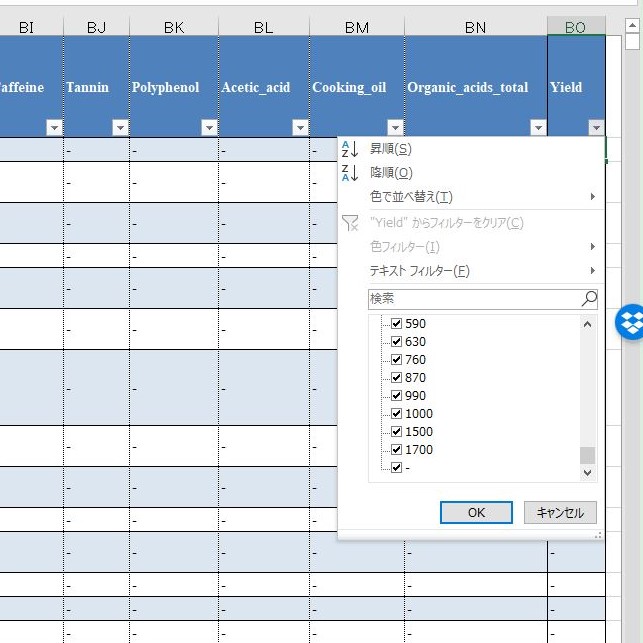
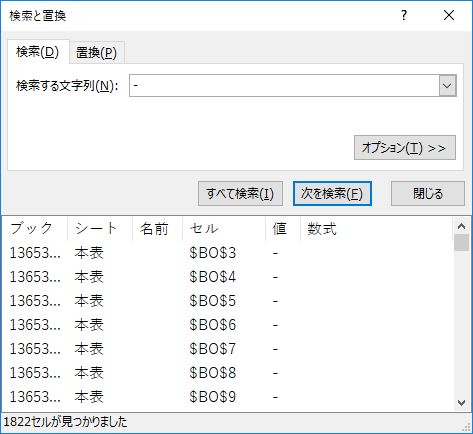
まず,ハイフンの数を確認する.セル範囲 BO2:BO2192 を選択して検索する.1822 個だ.つまり, 369 件しか重量変化率のデータが存在しないという意味だ.
次に A1:C2192 および BO1:BO2192 を選択し,コピーする.Control キーを押しながら選択すると,離れた領域でも同時に選択できる.
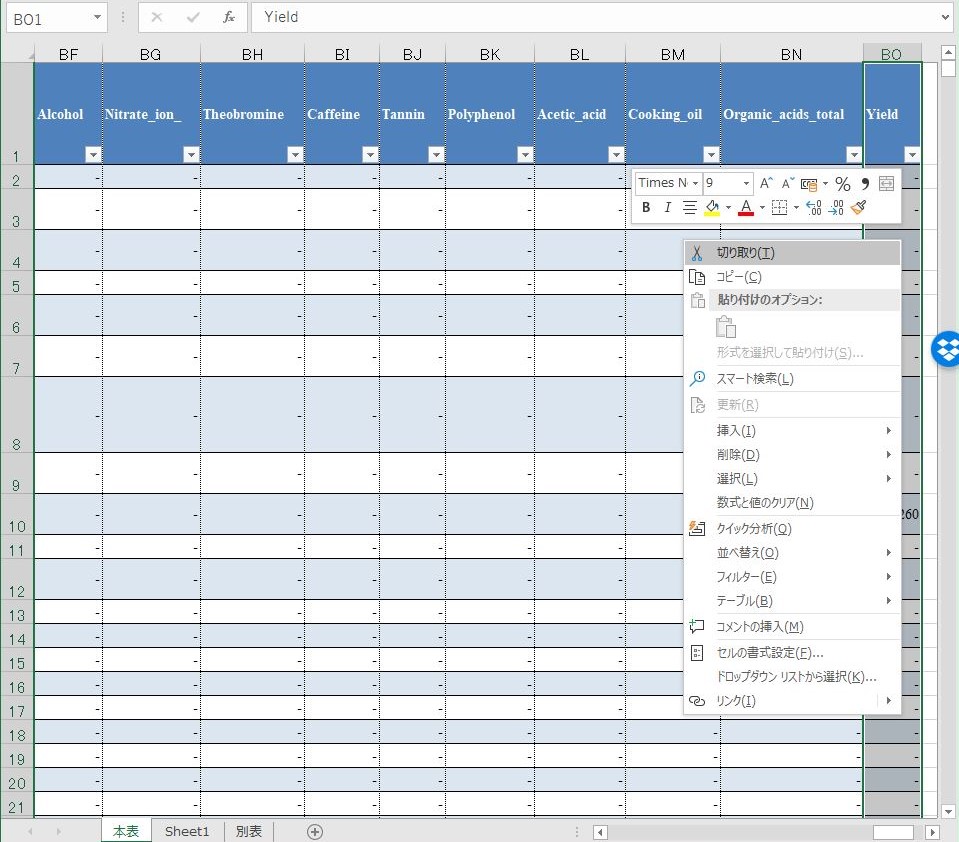
左下のワークシートを追加するボタンをクリックして新規シートを追加し,貼り付ける.シート名を T_YIELD とする.
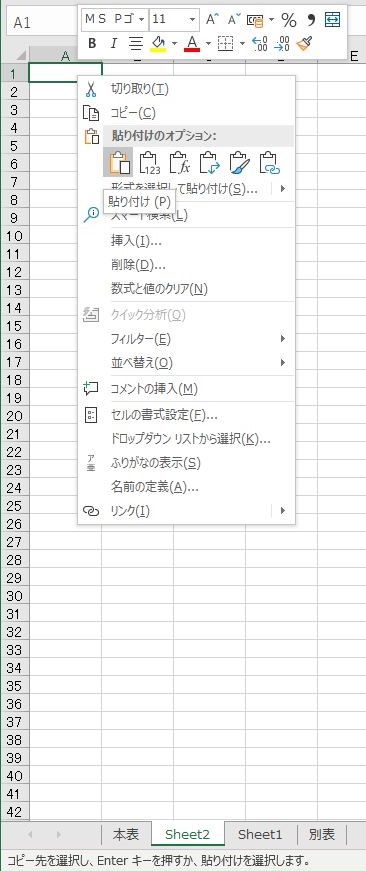
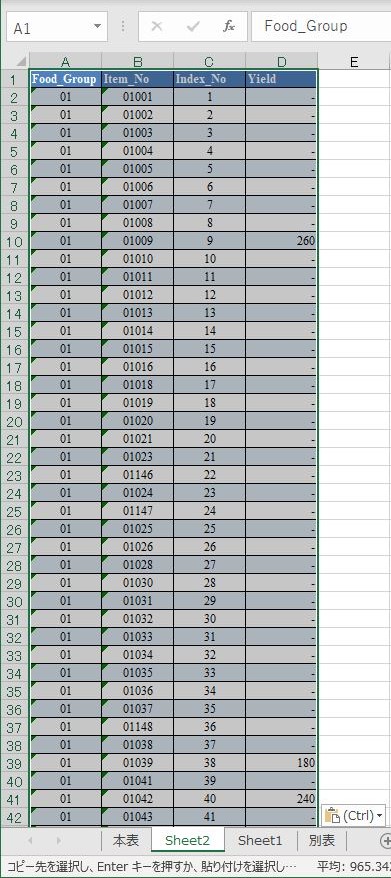
貼り付けた領域をテーブルに変換する.
フィルターを覗くと,最後にハイフンがある.
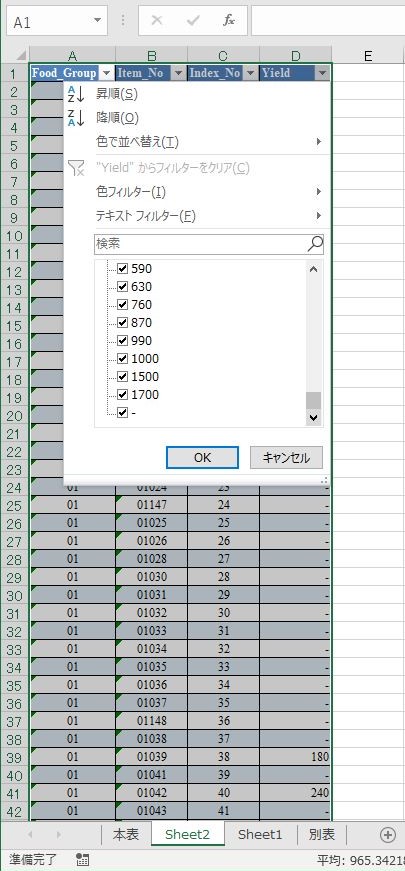
(すべて選択)のチェックを外し,ハイフンだけを選択する.
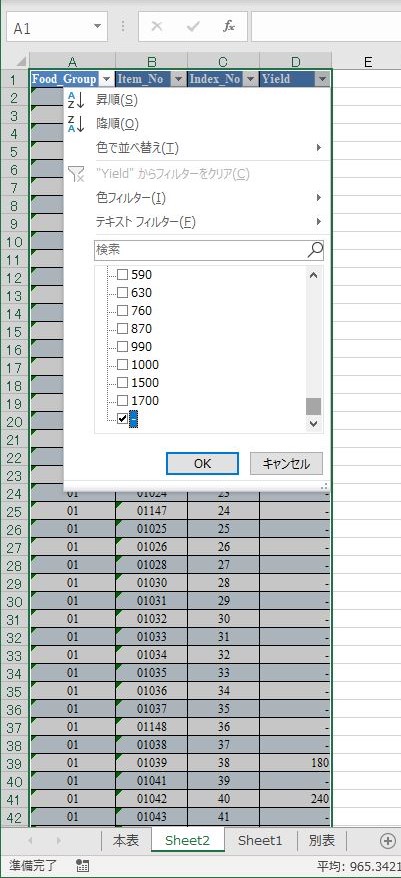
その状態で2行目以下を選択し,「行の削除」を行う.
(すべて選択)をチェックする.
重量変化率の有効な行だけが残る.シート名を T_YIELD と変更する.
本表に戻り,BO 列を削除する.
残る敵はハイフン,Tr, アスタリスクだ
データを丹念に見ていかないと気付かないのだが,アスタリスクが一個あった.人乳のヨードの成分だ.意味は調べていないが,計算できないものはゼロとみなす他ない.
ハイフンをゼロに置換する
例によってセル範囲 E2:BN2192 を選択し,ハイフンの数を確認する.
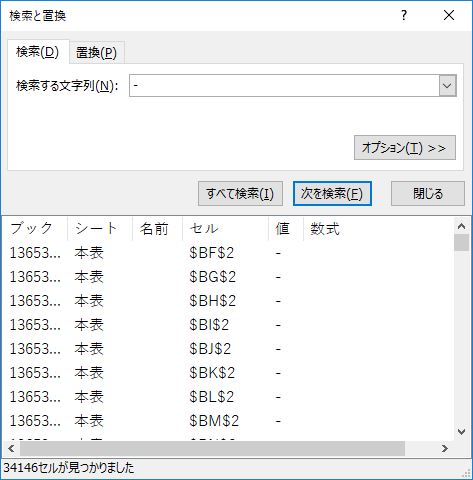
検索の結果,セル範囲の選択が外れるため,再度セル範囲 E2:BN2192 を選択し直してから「すべて置換」する.
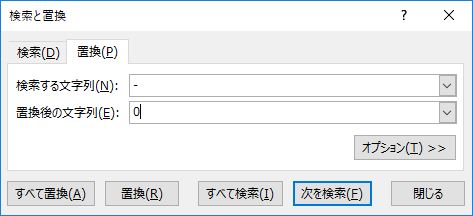
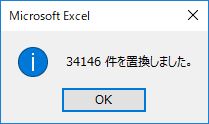
置換数が検索で選択されたセル数と同じであることを確認する.
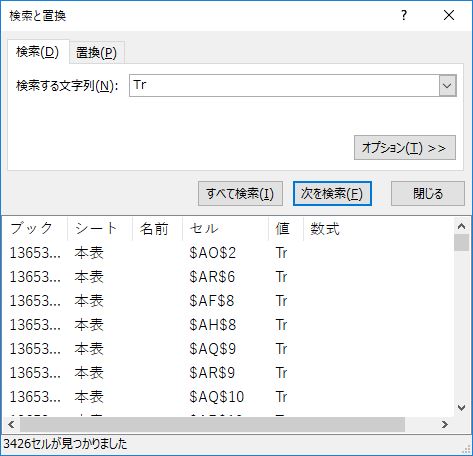
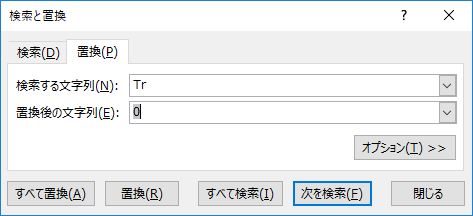
Trをゼロに置換する
ハイフンと同じ作業を行う.
アスタリスクは少々厄介だ
ここまでの作業でほとんどのデータクレンジングが終わっている.最後の敵はアスタリスクだ.実はこれはちょっと厄介だ.
というのも,アスタリスクは検索においてワイルドカードを意味しており,あらゆる文字に一致してしまう.試しに検索してみると,全セルがヒットする.
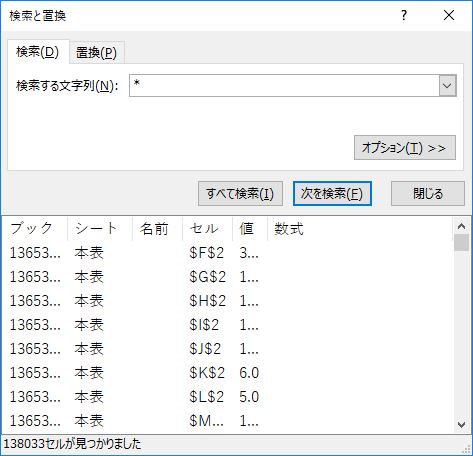
これは手作業で直すしかない.俺が確認したところ,このアスタリスクは人乳のヨードの項目にだけある.具体的には AF1810 のセルだ.これを手動でゼロと入力する.
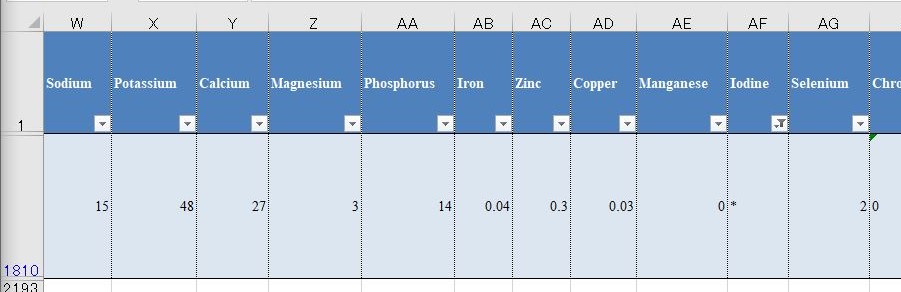
このデータを作った人間はちょっと意地が悪いと思ってしまう.何もこんなところに罠を仕掛けなくてもいいのに.
ファイルのプロパティを覗いてみる
ちょっと意地悪をしてみよう.ダウンロードしたファイルのプロパティを覗いてみる.
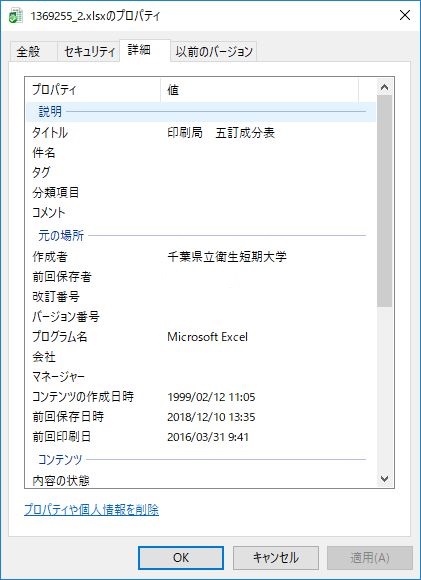
日本食品標準成分表2015年版(七訂)のページには付記1というファイルがある.ここで「千葉県立」で検索してみると 4 件ヒットするが,千葉県立保健医療大学である.担当したらしい人名が 2 名ほどあるが,ここでは出さないでおく.無関係かもしれないし.
.csvファイルに出力する
あとはワークシートを .csv ファイルに出力するだけだ.今回の記事はここまで.発生した問題点はまた次の機会に紹介しよう.
2019 年 3 月 1 日,データファイルを note に公開した.ダウンロードは日本標準食品成分表2015のcsvファイルから.
まとめと雑感
文部科学省のサイトから日本標準食品成分表の EXCEL のファイルをダウンロードしてデータを整形するまでを紹介した.特別な方法は何も用いていない.じっくり取り組めばできるはずだ.
しかし,である.本来ならこの .csv ファイルの状態でネットに公開すべきだ.データクレンジングに手間隙かかるせいで,いまだにこういう整形済みデータで金を取っている会社がある.
資本主義社会では情弱は金をむしられるようになってるんだと言えばそれまでだけど,本来税金で作られたデータなのだから,国民全員が共有できる形にしておくのが国の責務じゃないだろうか.文部科学省の人,見てる?
ここから先は愚痴だけど,2010 年版なんてもっとひどかった.PDF ファイルしか提供されてなくて,ファイルを開いてから EXCEL にコピペして VBA で検索置換してデータクレンジングしてた.泣きながら数ヶ月かかってやっと完成したんだ.
あれはとても全員ができるとは思えない.それを思えばだいぶマシになった方だ.だけど,まだ足りない.公務員なら国民の幸福に資することが仕事だろ?ダウンロードしたら即,データベースにぶち込める形にしておけよ.
俺が言いたいのはそれ.技術的なハードルをわざわざ作って参入障壁作るなよ.政治的な理由なんか知らん.国防以外に秘密を作るな.
“日本標準食品成分表2015をダウンロードし,データクレンジングを行う” への1件の返信