
気象庁の過去の気象データ・ダウンロードからは膨大な気象データをダウンロードできる.今回の記事ではSQL Server内に構築した熱中症データベースに日平均風速のテーブルを追加する.
SQL ServerのAdventureWorksデータベースをバックアップから復元する

SQL Serverのデータベースをバックアップから復元するでは手製のデータベースのバックアップからの復元を書いた.今回はMicrosoft謹製のデータベースAdventureWorksをバックアップから復元する手順を書いてみる.
東日本大震災の避難者数の統計を調べる
件の統計は復興庁の全国の避難者の数(所在都道府県別・所在施設別の数にあるが,このページはトップページから辿ることができず,検索からのみ到達できる.時系列でのデータは必須と思われるが,トップページから辿れるのは最新の情報のみであり,これは国民の利益に反する.
熱中症の搬送人員と最高気温との相関関係を可視化し閾値をχ二乗検定する
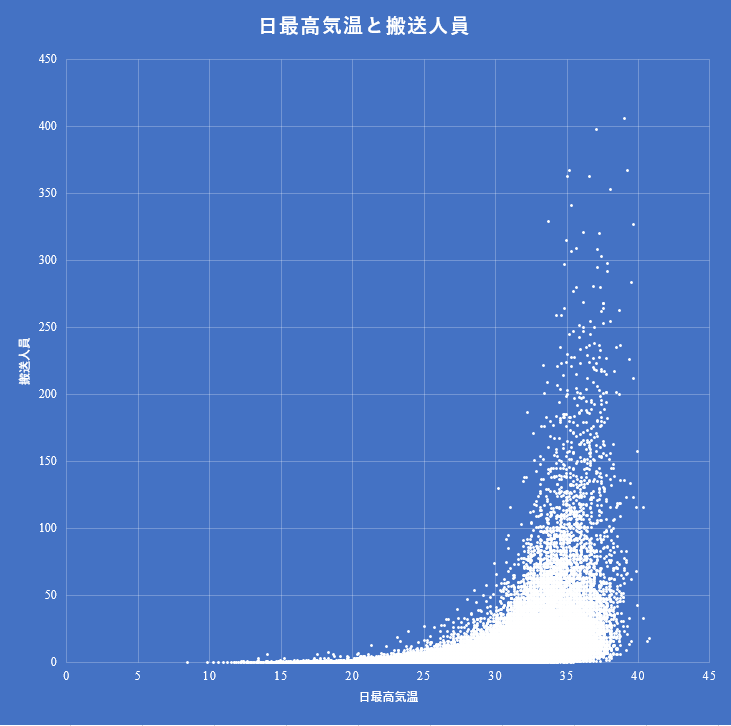
最高気温と熱中症の搬送人数との間に相関関係はあるだろうか.熱中症で救急搬送された人数は総務省の消防庁のサイトにある.これと気象庁のデータを結合してみた.
国土地理院の基盤地図情報ダウンロードサービスのファイル名を調べる
国土地理院の基盤地図情報はあらゆる日本地図の基礎となっている.ダウンロードしたファイル名に一定の規則があり,何を示したものか調べた.
Ecorisで国土地理院基盤地図情報の数値標高モデルをGeoTiffに変換する
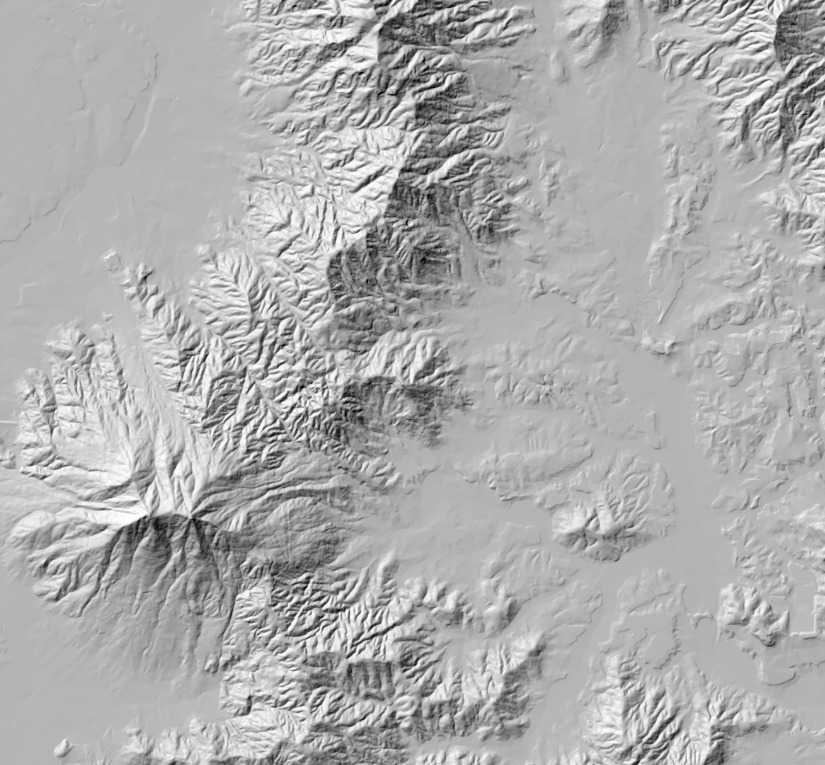
国土地理院の基盤地図情報ダウンロードサービスではベクタデータとラスタデータをダウンロードできる.Point, LineString, Polygon はベクタデータだが,数値標高モデルはラスタデータである.今回はラスタデータである数値標高モデルをダウンロードし,GeoTiff に変換する.
EXCEL VBA でフォルダ内のブックを開きデータを読み込む
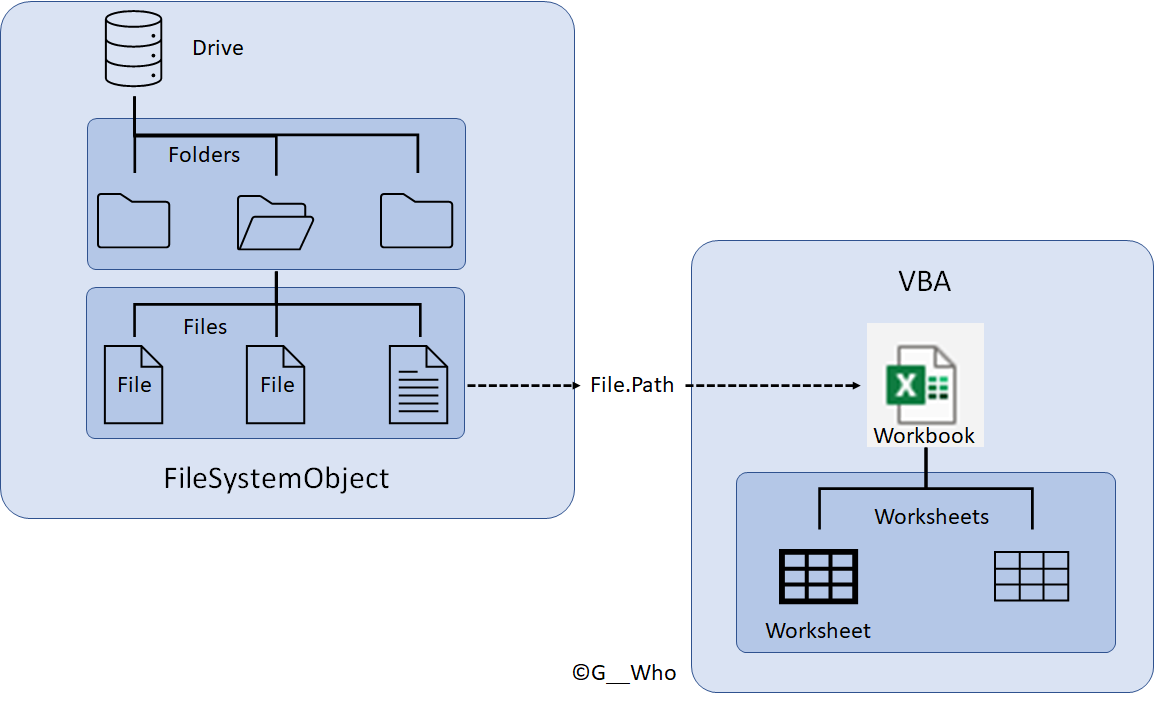
Power Query が使えないと不便である.先日 EXCEL 2010 の素の環境でフォルダ内のブックをすべて開き,データを読み込む必要があったのだが,Power Query が使えなかったため,VBA でブックを開いて読み込まなければならなかった.備忘録としての記事である.
この記事はPower Query でフォルダから複数ファイルを一括インポートすると対応している.やっていることは同じだが,.xls 形式だとクエリの検証に時間がかかるため,VBA で読み込んだほうが動作は早いかもしれない.
フォルダー内のファイル一覧を取得するには FileSystemObject を使う場合と Dir() 関数を使う方法とがある.ここでは FileSystemObject を使うことにする.
データは Range オブジェクトに格納されているため,Range オブジェクトを取得するのが当面の目標となる.
Power Query でフォルダから複数ファイルを一括インポートする
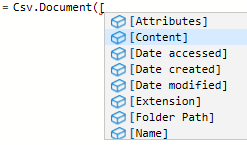
Power Query で,あるフォルダ内の同一構造のファイルを一括してインポートする機会は多い.M 言語は未開拓であるが,その一端に触れてみた.
EXCEL ブックであれ csv ファイルであれ,構造化されたデータという観点から見れば,ファイル形式などどうでも良い話である.この抽象化が理解できれば,Power Query への理解が一定程度進むのではないかと思う.
この記事はEXCEL VBA でフォルダ内のブックを開きデータを読み込むと対応する.
Microsoft 365 英語版を使う

英語版で Microsoft Office を使いたい場合はどうするか.いくつか方法がある.もともとインストールされた日本語版がある場合と,まっさらな状態からインストールする場合で対応が異なる.
色の知覚(1)太陽光
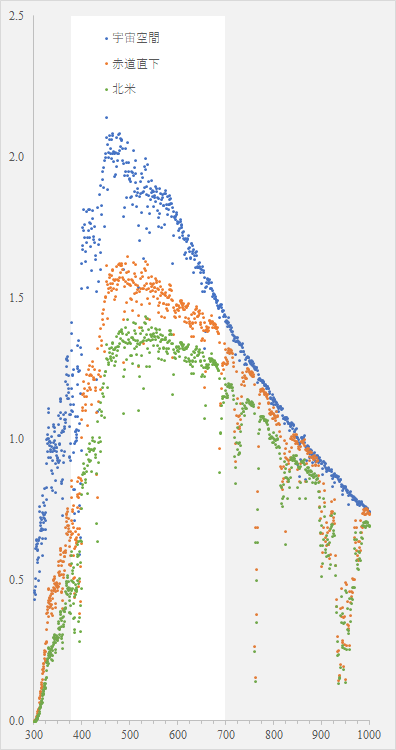
色彩に関してはこれまで先人の膨大な研究の積み重ねがある.その一端を紹介し,色の物理的性質から生理的反応への橋渡しについて考察する.
今回は太陽光について調べた.データベースは主に National Renewable Energy Laboratory から取った.日本国内にも太陽光についてのデータベースは気象庁や新エネルギー・産業技術総合開発機構がデータを公開している.